开篇词|拥抱Rust浪潮,迎接更极致的编程体验
你好,我是唐刚,Rust 语言中文社区联合创始人。欢迎加入《Rust语言从入门到实战》,开启一段全新的学习旅程。
2014年我开始接触Rust,到现在已经8年多了,从拥护者到布道者,一直在学习积累。
我以前是一个C极大主义者,觉得用C语言就能完成我想做的任何事情。但后来C程序中的各种缓冲区溢出、段错误等问题一直困扰着我,不管我采用何种最佳实践集合,那些问题总是根除不了。
这也是我学习Rust的重要契机。那时我就有种直觉——它一定会成为未来的一股潮流。
于是我积极参与国内Rust语言社区的贡献和维护,2016年组织并参与撰写了中文社区第一本免费开源的Rust语言教程:RustPrimer(也许是世界上第一本,比官方书 The Rust Programming Book 还早)。后续几年又参与翻译了《Rust权威指南》和《Rust实战》两本书。同时,我还维护着国内Rust语言中文社区论坛 Rustcc.cn 和 Rust语言中文社区公众号。
很幸运我亲历了Rust语言从诞生、成长,到被越来越多的开发者和企业接受的过程,也见证了Rust语言从初出茅庐的稚嫩到特性不断成熟、对初学者越来越友好的过程。难得的是,Rust始终保持初心: 对安全性的追求,对性能的不妥协。 也正因如此,它连续8年被StackOverfow评为最受程序员喜爱的语言。
因为日常工作的关系,我对Rust语言在国内的发展状况和困难点比较了解。至少在前几年,Rust语言一直都还处于叫好不叫座的状态。喜欢的人确实多,但是能真正在工作中实践的少之又少。我想这与Rust语言上手难度比较高有直接的关系。
暗潮汹涌的 Rust
不过到了2023年,我发现互联网上自发地学习和宣传Rust的人变多了,在各大招聘网站上的Rust岗位也多了起来,分布在各个领域,如操作系统、服务端、中间件、云原生、数据库、大数据、区块链、嵌入式、大模型、客户端,甚至Web前端开发领域都涌现出一批业界不可忽视的项目。
也就是说,前期的观望期可能已经快结束了。而验证期过后,很可能是一个爆发期,如果你能赶在它爆发前掌握它,那对自身的竞争力来说会是一个极大的加成。我们来看一个数据, Rust官方的包仓库crates.io的下载量。

这是一个明显的指数曲线,crate下载量在以每年1.8倍的速度递增(已超过摩尔定律)。另外一方面,国内国外的一些大厂也都在力推Rust。
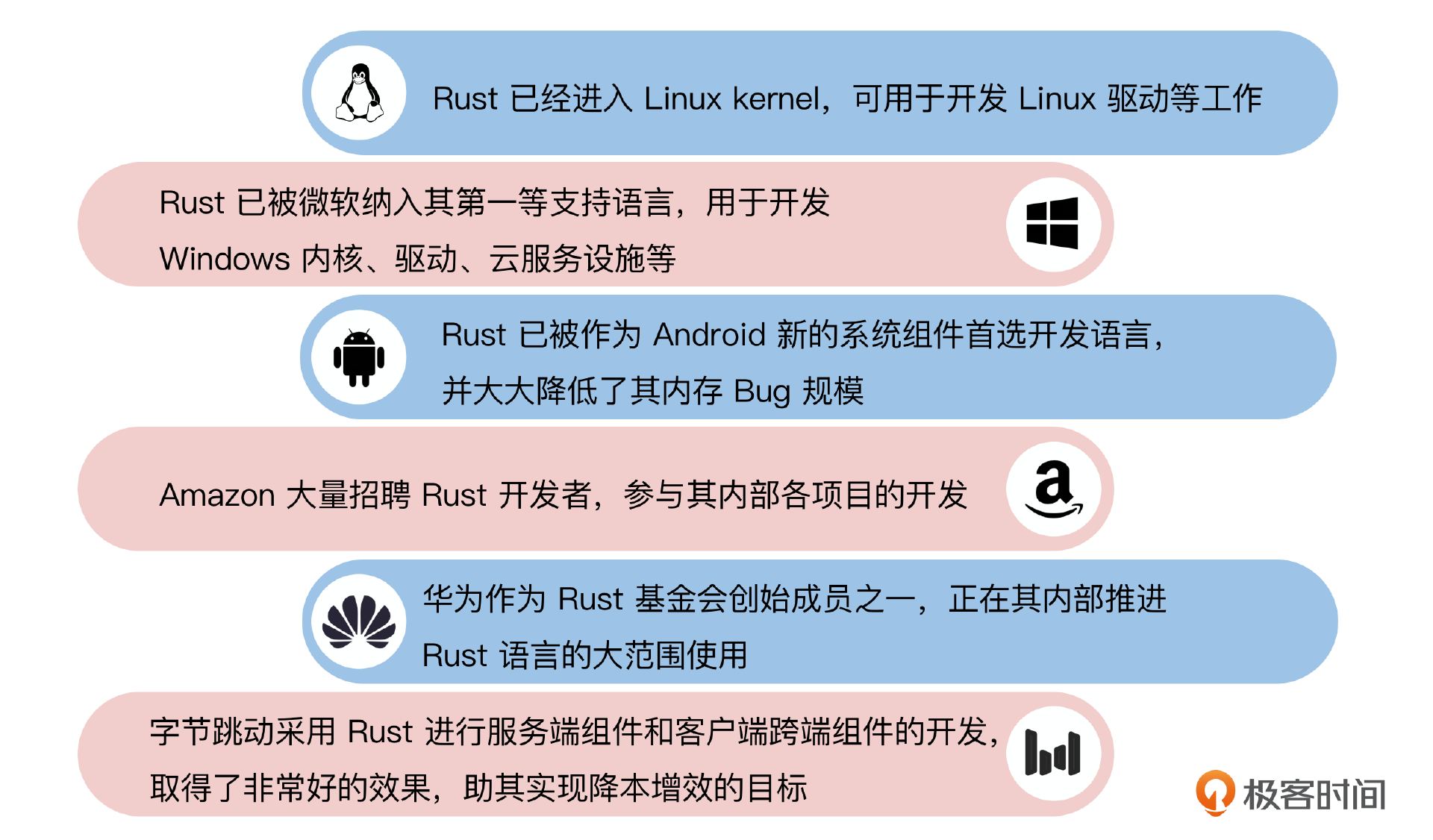
这些数据让我们对Rust的未来信心满满!
Rust 为什么这么难学?
但是就像前面说的,Rust确实“难学”,这是一个必须面对的客观事实。难学最主要的原因是, Rust语言中的概念和风格跟现在主流的编程语言不一致,这导致了几个问题。
- 需要重新理解一些基础概念,如变量赋值、可变性、所有权等。
- 需要重新熟悉一些新的编程范式,如非OOP、Trait约束、链式操作等。
- 以前习惯了的快速学习方法不顶用了,比如像Go语言快速过两遍语法就能上手做小工具。
这和前面20多年我们一直认为的“编程语言发展方向就是语法越来越简单易用”的理念背道而驰。其实,关于编程语言的发展方向还真不是这样,现在的趋势反而是在朝着 类型化、健壮性 方向发展。所以我们首先得调整一下心态。
其实,Rust之所以“难”,是因为 编程这件事儿本身就很难, 或者说客观世界的复杂性本来就在那里,你不可能投机取巧绕过它们。 只是不同语言对这种客观复杂性的处理思路或者说设计哲学不一样,比如C语言就把场景复杂性留给了程序员,而像Java、Python和JavaScript这些高级语言则尽可能将内部复杂性进行封装和隐藏,所以相对来说会更容易入门。
而C++则是把复杂性留给了自己,这也导致了入门和学好它都比较困难。而Rust也基本继承自C++。它吸收了前辈语言很多优秀成分,从所有权理论出发,打造出了一个全新的体系。
与C++一样,Rust是一门全问题域语言,或者叫真正的全栈语言。它可以适应从嵌入式裸金属编程、OS开发,到上层数据库、大模型系统几乎所有层次的开发需求。Rust从一开始就被设计成一门立足安全、追求性能、迎合并行计算需求的语言。
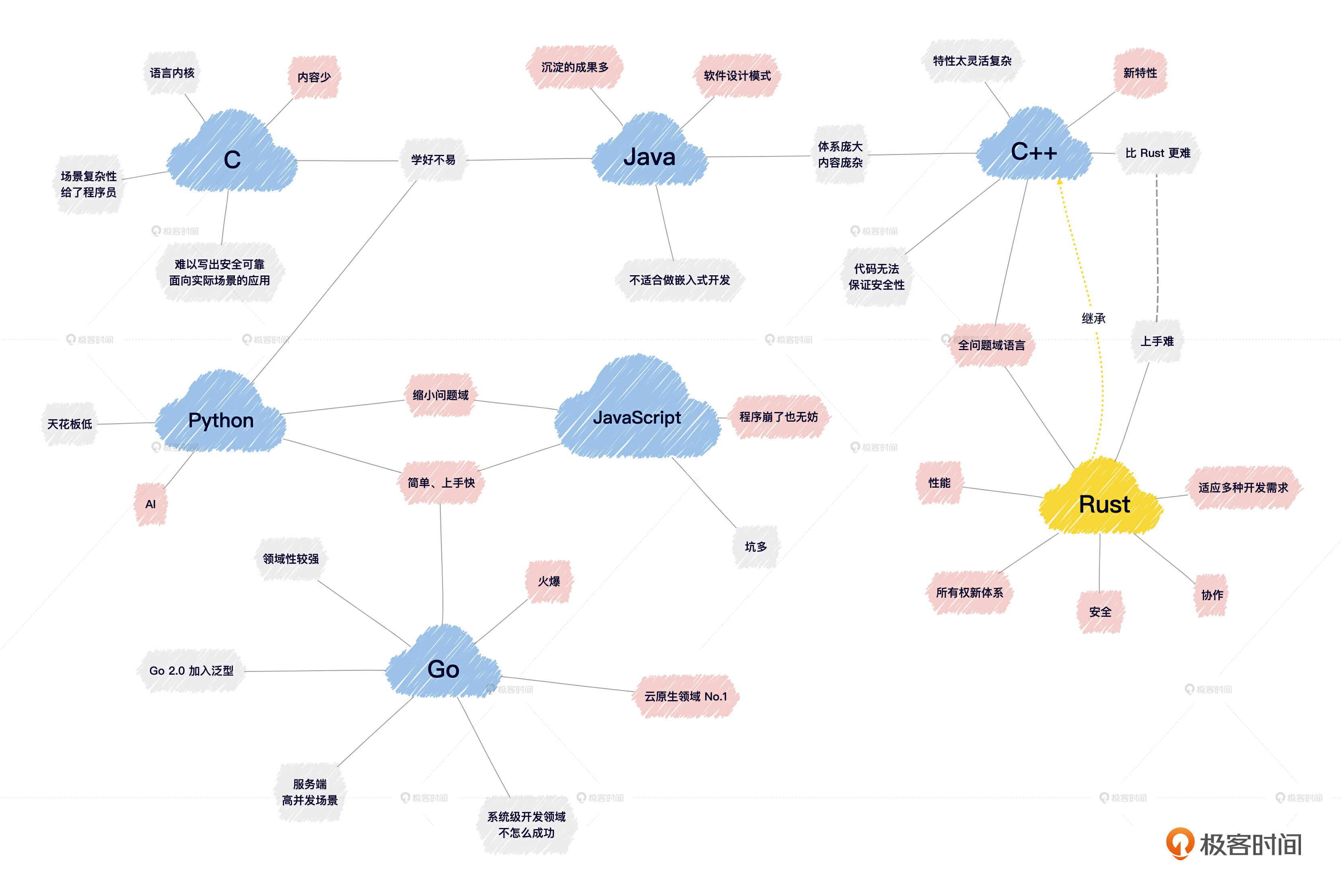
不走寻常路的 Rust
Rust之前的语言,在 内存管理 上主要是走两条路子。第一条是为了追求高性能,内存管理基本上全权交给程序员。写出的程序是否安全,由程序员自己来保证。这类语言典型的就是C、C++。后来人们觉得第一条路对程序员要求太高了,太难了,因此转向了GC这条路。从Java开始的这些语言基本走的都是这条路。但是这条路子也有相当大的牺牲,比如运行时的负担、Stop The World等问题。
后来,C++中出现了一些智能指针的设计,用来帮助程序员减轻内存管理的痛苦。但是就像前面提到过的,这些创新改进无法从根本上解决C++写出不安全代码的问题。更别说很多程序员甚至都不愿意去使用这些新的特性。
而Rust语言选择了第三条路子: 使用所有权对资源进行管理。 既不需要让程序员手动管理内存,也不需要借助GC来管理内存。这个方式灵感来源于RAII(Resource Acquisition Is Initialization,资源获取即初始化),但做得更精细。
Rust语言,不管吸收整合了多少种语言的优秀特性,从根本上来说,主要还是来自于C++,如果把Rust简单粗暴地理解为Better C++也不为过。但由于Rust语言完全重新设计,因此从一出生就没有了C++沉重的历史包袱,可以把很多特性做得更彻底。
如何不被 Rust 劝退,顺利入门?
好了,明白了Rust不是故意设计成这样来刁难我们之后,问题就转化成了另外一个:有没有一些好的方法能够让我们顺利地入门Rust而不被劝退呢?关键就在于 上手期的顺利程度。
因为Rust本身具有较多独特的语言元素,初学者第一次遇到这些元素时容易卡壳,导致编译不通过。如果卡壳的地方多了,并且搜索也找不到答案的话,就容易被击退。所以从入门到放弃就成了Rust社区中的一个梗。
到了2023年,Rust相关资料已经相当丰富了。但在如何引导新人更容易地上手这一块儿,无论是官方还是社区,做得都还远远不够。而我们的课程也正是这样一次探索成果的展示。我希望在这个课程中,用示例来引导你小阶梯地一步一步往上走。真正找到写Rust程序的感觉,体会到学习Rust语言的乐趣。
不过这门课程不会面面俱到,而是会专注于把Rust语言中最核心的概念讲透,详细解析对于初学者来说容易卡壳的地方。通过设计大量的代码示例,把这些细微精妙的东西讲清楚。
学习,从本质上来说,其实就是N+1的过程。就是要一点一点地理解新知识,将其消化,与已有的知识体系融合,学好一步后,再学下一步,也就是不能直接 N+2,要 N+1+1。跳过一步,也许后面就脱节了。因此你不需要着急,多花点时间把Rust的基础打好至关重要。Rust语言是一门全栈语言,它能够用很久。所以静下心来学习,似慢实快!
课程设计
为了实现这种 N+1+1 的效果,我把整个课程分成三部分。
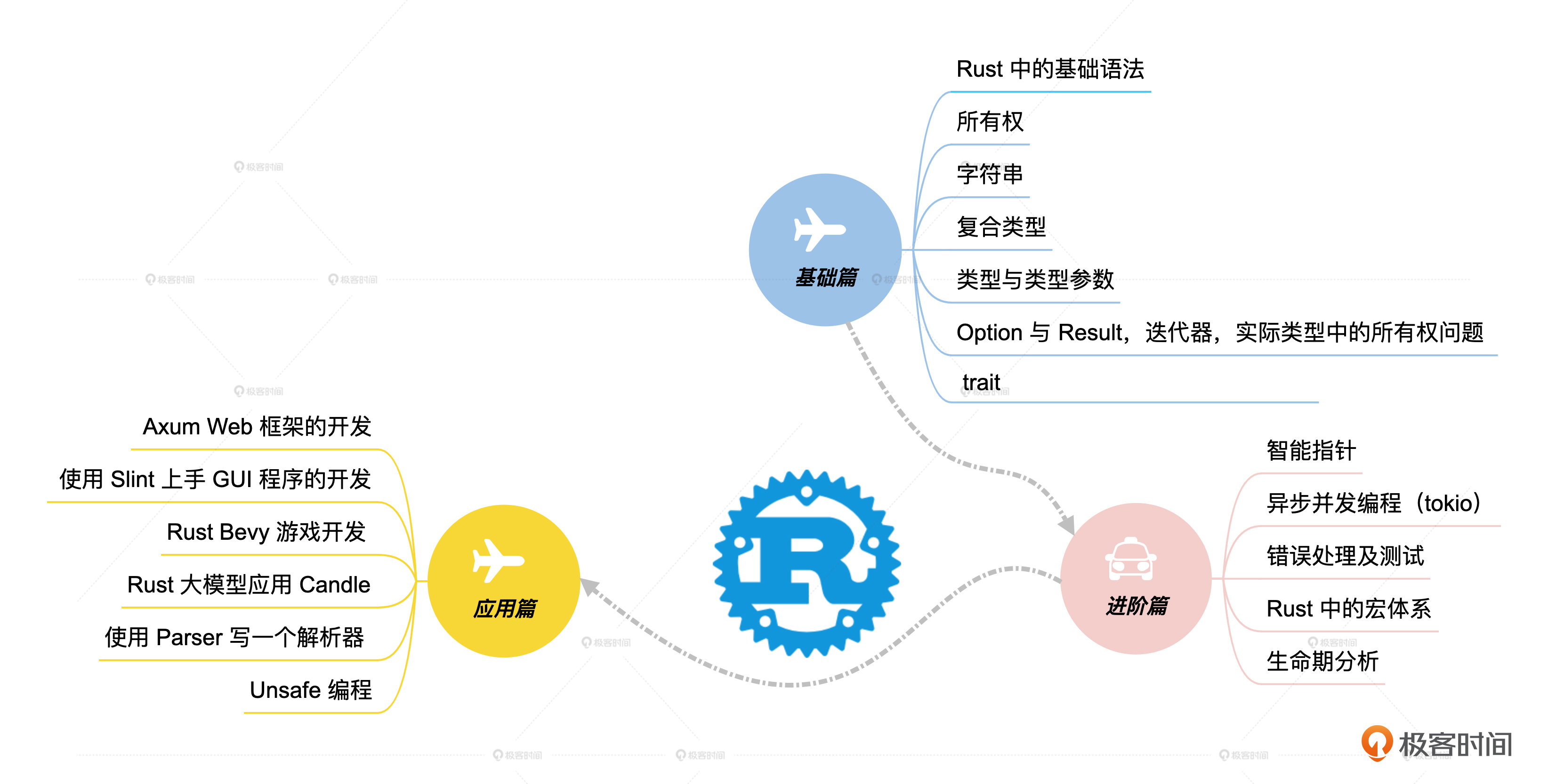
基础篇
在基础篇,我会给你详细讲解Rust语言的基础语法,学习Rust中最常用的语言组件,并用大量示例学习Rust所有权、类型Trait。Rust中的知识点非常多,但是我们初学者并不需要学完所有知识点才能开始写代码。因此我们在基础篇中将Rust必须掌握的部分拎出来,让你在有限的时间里掌握Rust语言的精髓。
进阶篇
在学完基础篇的那些概念的基础上,我们在进阶篇中会学习智能指针、错误处理、宏、生命期初步分析、Rust异步并发编程等内容。因为异步并发编程在实际生产中使用越来越广泛,所以它的占比也是最大的。通过这部分的学习,我们将掌握使用Rust高效解决实际问题的方法。与Java类似,Rust的编程模式是非常固定的,学习起来并不困难。
应用篇
第三阶段应用篇,我会带你在实际的项目中应用Rust。通过Web后端开发、前端 GUI开发、游戏开发、大模型实践、解析器开发和跨语言开发这6个不同领域的实战,你可以学会利用Rust生态中的框架快速解决问题。同时能感受到Rust语言的强大能力及其广泛的适用场景。在完成第三阶段的学习后,你可以选择一个方向继续深入,毕竟要想在任何一个方向上成为专家,都必须花大量的时间去积累。
纸上得来终觉浅,绝知此事要躬行。我们课程中含有大量的示例代码,希望你能跟着我一起手敲代码,体会架构设计和编译调试过程中的乐趣。我保证课程中的每一步进展,都是你可以理解的,我会尽量使用简短的代码或示意图来把问题说清楚。相信我,跟着我做,你一定会对Rust的理解到达一个新的层次。
下面我们就正式开始这一次的Rust学习之旅吧!
快速入门:Rust 中有哪些你不得不了解的基础语法?
你好,我是 Mike。今天是我们的 Rust 入门与实战第一讲。
无论对人,还是对事儿,第一印象都很重要,Rust 也不例外。今天我们就来看一看 Rust 给人的第一印象是什么吧。其实 Rust 宣称的安全、高性能、无畏并发这些特点,初次接触的时候都是感受不到的。第一次能直观感受到的实际是下面这些东西。
- Rust 代码长什么样儿?
- Rust 在编辑器里面体验如何?
- Rust 工程如何创建?
- Rust 程序如何编译、执行?
下面我们马上下载安装 Rust,快速体验一波。
下载安装
要做 Rust 编程开发,安装 Rust 编译器套件是第一步。如果是在 MacOS 或 Linux 下,只需要执行:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
按提示执行操作,就安装好了,非常方便。
而如果你使用的是 Windows 系统,那么会有更多选择。你既可以在 WSL 中开发编译 Rust 代码,也可以在 Windows 原生平台上开发 Rust 代码。
如果你计划在 WSL 中开发,安装方式与上面一致。
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
如果想在 Windows 原生平台上开发 Rust 代码,首先需要确定安装 32 位的版本 还是 64 位的版本。在安装过程中,它会询问你是想安装 GNU 工具链的版本还是 MSVC 工具链的版本。安装 GNU 工具链版本的话,不需要额外安装其他软件包。而安装 MSVC 工具链的话,需要先安装微软的 Visual Studio 依赖。
如果你暂时不想在本地安装,或者本地安装有问题,对于我们初学者来说,也有一个方便、快捷的方式,就是 Rust 语言官方提供的一个网页端的 Rust 试验场,可以让你快速体验。
这个网页 Playground 非常方便,可以用来快速验证一些代码片段,也便于将代码分享给别人。如果你的电脑本地没有安装 Rust 套件,可以临时使用这个 Playground 学习。
编辑器/ IDE
开发 Rust,除了下载、安装 Rust 本身之外,还有一个工具也推荐你使用,就是 VS Code。需要提醒你的是,在 VS Code 中需要安装 rust-analyzer 插件才会有自动提示等功能。你可以看一下 VS Code 编辑 Rust 代码的效果。
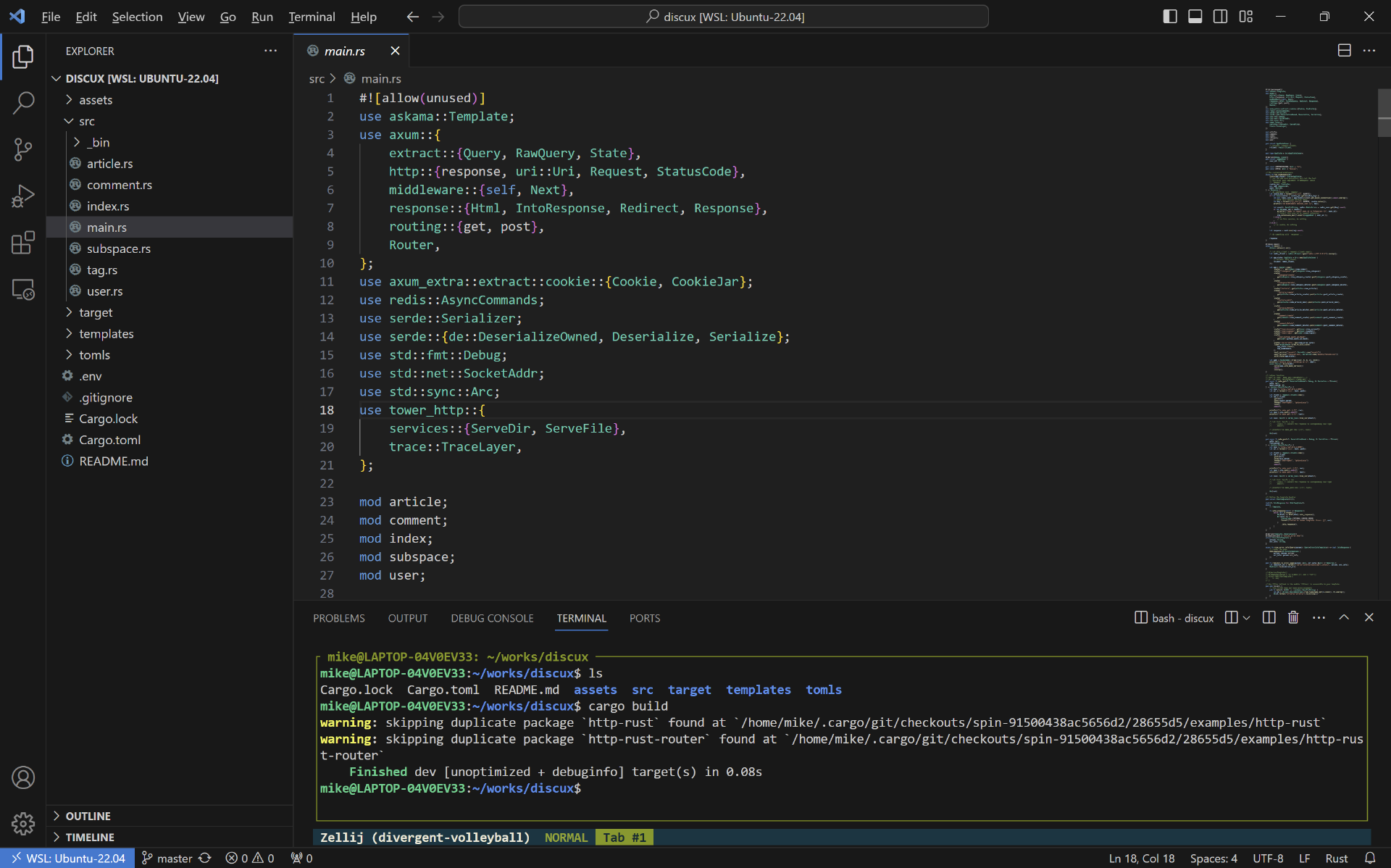
VS Code 功能非常强大,除了基本的 IDE 功能外,还能实现 远程编辑。 比如在 Windows 下开发,代码放在 WSL Linux 里面,在 Windows Host 下使用 VS Code 远程编辑 WSL 中的代码,体验非常棒。
其他一些常用的 Rust 代码编辑器还有 VIM、NeoVIM、IDEA、Clion 等。JetBrains 最近推出了 Rust 专用的 IDE:RustRover,如果有精力的话,你也可以下载下来体验一下。
Rust 编译器套件安装好之后,会提供一些工具,这里我们选几个主要的简单介绍一下。
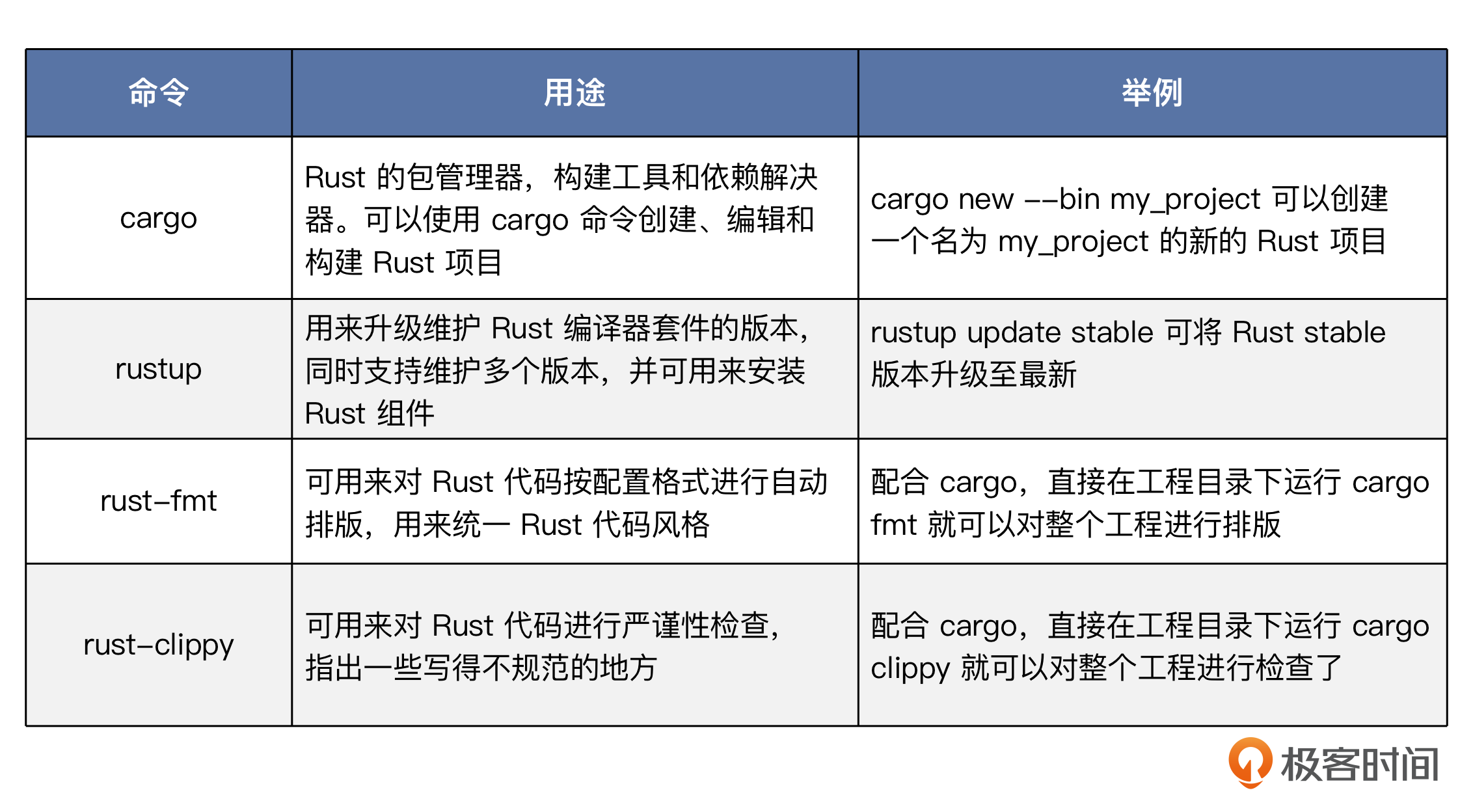
工具齐备了,下面我们马上体验起来,先来创建一个 Rust 工程。
创建一个工程
创建工程我们应该使用哪个工具呢? 没错,就是刚刚我们提到的 cargo 命令行工具。我们用它来创建一个 Rust 工程 helloworld。
打开终端,输入:
cargo new --bin helloworld
显示:
Created binary (application) `helloworld` package
这样就创建好了一个新工程。这个新工程的目录组织结构是这样的:
helloworld
├── Cargo.toml
└── src
└── main.rs
第一层是一个 src 目录和一个 Cargo.toml 配置文件。src 是放置源代码的地方,而 Cargo.toml 是这个工程的配置文件,我们来看一下里面的内容。
[package]
name = "helloworld"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
Cargo.toml 中包含 package 等基本信息,里面有名字、版本和采用的 Rust 版次。Rust 3 年发行一个版次,目前有 2015、2018 和 2021 版次,最新的是 2021 版次,也是我们这门课使用的版次。可以执行 rustc -V 来查看我们课程使用的 Rust 版本。
rustc 1.69.0 (84c898d65 2023-04-16)
好了,一切就绪后,我们可以来看看 src 下的 main.rs 里面的代码。
Hello, World
fn main() { println!("Hello, world!"); }
这段代码的意思是,我们要在终端输出这个 "Hello, world!" 的字符串。
使用 cargo build 来编译。
$ cargo build
Compiling helloworld v0.1.0 (/home/mike/works/classes/helloworld)
Finished dev [unoptimized + debuginfo] target(s) in 1.57s
使用 cargo run 命令可以直接运行程序。
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target/debug/helloworld`
Hello, world!
可以看到,最后终端打印出了 Hello, world。我们成功地执行了第一个 Rust 程序。
Rust 基础语法
快速体验 Hello World 后,你是不是对 Rust 已经有了一个感性的认识?不过只是会 Hello World 的话,我们离入门 Rust 尚远。下面我们就从 Rust 的基础语法入手开始了解这门语言,为今后使用 Rust 编程打下一个良好的基础。
Rust 基础语法主要包括基础类型、复合类型、控制流、函数与模块几个方面,下面我带你一个一个看。
Rust 的基础类型
赋值语句
Rust 中使用 let 关键字定义变量及初始化,你可以看一下我给出的这个例子。
fn main() { let a: u32 = 1; }
可以看到,Rust 中类型写在变量名的后面,例子里变量 a 的类型是 u32, 也就是无符号 32 位整数,赋值为 1。Rust 保证你定义的变量在第一次使用之前一定被初始化过。
数字类型
与一些动态语言不同,Rust 中的数字类型是区分位数的。我们先来看整数。
整数
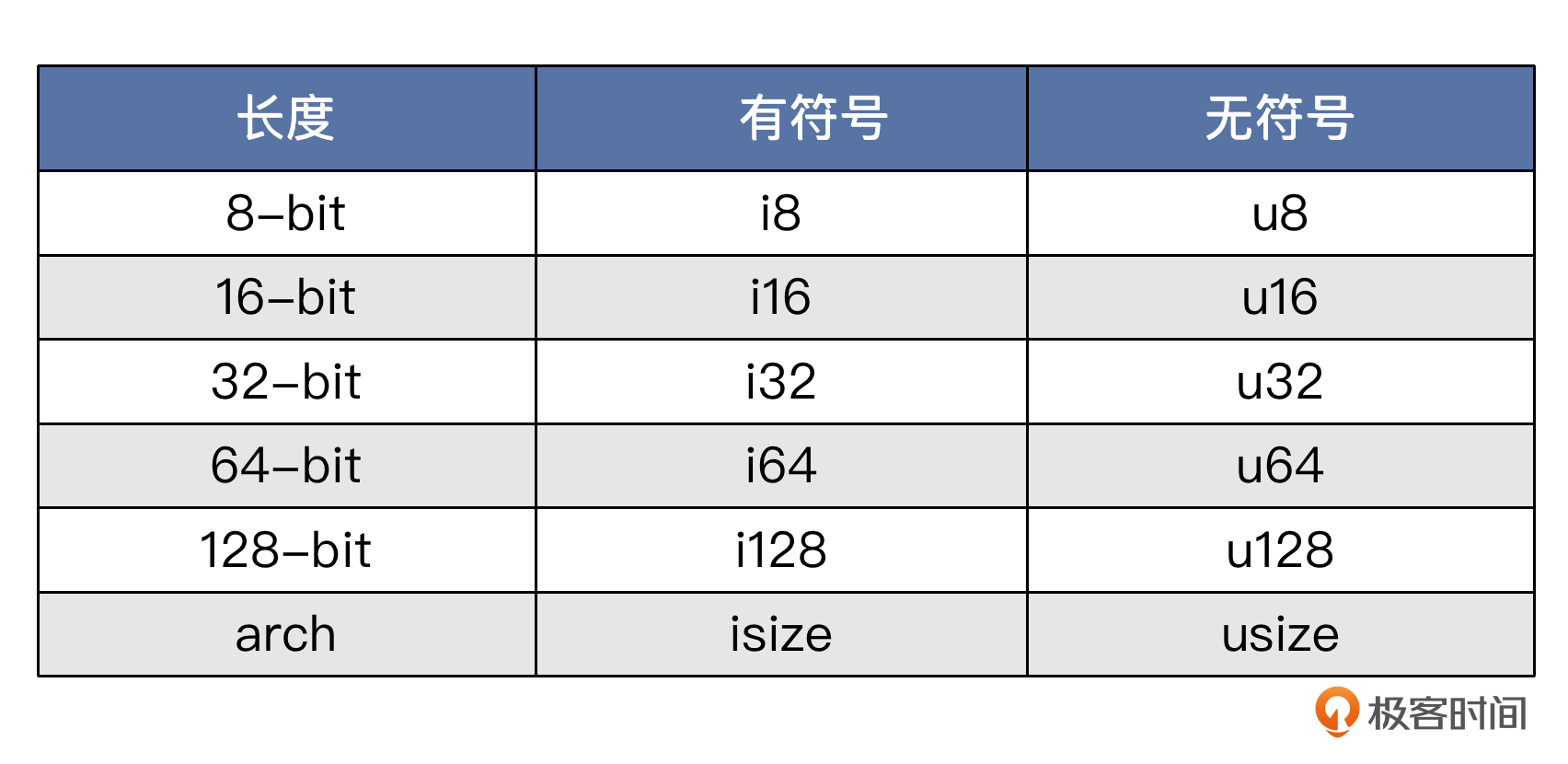
其中,isize 和 usize 的位数与具体 CPU 架构位数有关。CPU 是 64 位的,它们就是 64 位的,CPU 是 32 位的,它们就是 32 位的。这些整数类型可以在写字面量的时候作为后缀跟在后面,来直接指定值的类型,比如 let a = 10u32; 就定义了一个变量 a,初始化成无符号 32 位整型,值为 10。
整数字面量的辅助写法
Rust 提供了灵活的数字表示方法,便于我们编写整数字面量。比如:
十进制字面量 98_222,使用下划线按三位数字一组隔开
十六进制字面量 0xff,使用0x开头
8进制字面量 0o77,使用0o(小写字母o)开头
二进制字面量 0b1111_0000,使用0b开头,按4位数字一组隔开
字符的字节表示 b'A',对一个ASCII字符,在其前面加b前缀,直接得到此字符的ASCII码值
各种形式的辅助写法是为了提高程序员写整数字面量的效率,同时更清晰,更不容易犯错。
浮点数
浮点数有两种类型:f32 和 f64,分别代表 32 位浮点数类型和 64 位浮点数类型。它们也可以跟在字面量的后面,用来指定浮点数值的类型,比如 let a = 10.0f32; 就定义了一个变量 a,初始化成 32 位浮点数类型,值为 10.0。
布尔类型
Rust 中的布尔类型为 bool,它只有两个值,true 和 false。
let a = true;
let b: bool = false;
字符
Rust 中的字符类型是 char,值用单引号括起来。
fn main() { let c = 'z'; let z: char = 'ℤ'; let heart_eyed_cat = '😻'; let t = '中'; }
Rust 的 char 类型存的是 Unicode 散列值。这意味着它可以表达各种符号,比如中文符号、emoji 符号等。在 Rust 中,char 类型在内存中总是占用 4 个字节 大小。这一点与 C 语言或其他某些语言中的 char 有很大不同。
字符串
Rust 中的字符串类型是 String。虽然中文表述上,字符串只比前面的字符类型多了一个串字,但它们内部存储结构完全不同。String 内部存储的是 Unicode 字符串的 UTF8 编码,而 char 直接存的是 Unicode Scalar Value(二者的区别可查阅 这里)。也就是说 String 不是 char 的数组,这点与 C 语言也有很大区别。
通过下面示例我们可以看到,Rust 字符串对 Unicode 字符集有着良好的支持。
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שָׁלוֹם");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
注意,Rust 中的 String 不能通过下标去访问。
let hello = String::from("你好");
let a = hello[0]; // 你可能想把“你”字取出来,但实际上这样是错误的
为什么呢?你可以想一想。因为 String 存储的 Unicode 序列的 UTF8 编码,而 UTF8 编码是变长编码。这样即使能访问成功,也只能取出一个字符的 UTF8 编码的第一个字节,它很可能是没有意义的。因此 Rust 直接对 String 禁止了这个索引操作。
字符串字面量中的转义
与 C 语言一样,Rust 中转义符号也是反斜杠 \ ,可用来转义各种字符。你可以运行我给出的这几个示例来理解一下。
fn main() { // 将""号进行转义 let byte_escape = "I'm saying \"Hello\""; println!("{}", byte_escape); // 分两行打印 let byte_escape = "I'm saying \n 你好"; println!("{}", byte_escape); // Windows下的换行符 let byte_escape = "I'm saying \r\n 你好"; println!("{}", byte_escape); // 打印出 \ 本身 let byte_escape = "I'm saying \\ Ok"; println!("{}", byte_escape); // 强行在字符串后面加个0,与C语言的字符串一致。 let byte_escape = "I'm saying hello.\0"; println!("{}", byte_escape); }
除此之外,Rust 还支持通过 \x 输入等值的 ASCII 字符,以及通过 \u{} 输入等值的 Unicode 字符。你可以看一下我给出的这两个例子。
fn main() { // 使用 \x 输入等值的ASCII字符(最高7位) let byte_escape = "I'm saying hello \x7f"; println!("{}", byte_escape); // 使用 \u{} 输入等值的Unicode字符(最高24位) let byte_escape = "I'm saying hello \u{0065}"; println!("{}", byte_escape); }
注:字符串转义的详细知识点,请参考 Tokens - The Rust Reference (rust-lang.org)。
禁止转义的字符串字面量
有时候,我们不希望字符串被转义,也就是想输出原始字面量。这个在 Rust 中也有办法,使用 r"" 或 r#""# 把字符串字面量套起来就行了。
fn main() { // 字符串字面量前面加r,表示不转义 let raw_str = r"Escapes don't work here: \x3F \u{211D}"; println!("{}", raw_str); // 这个字面量必须使用r##这种形式,因为我们希望在字符串字面量里面保留"" let quotes = r#"And then I said: "There is no escape!""#; println!("{}", quotes); // 如果遇到字面量里面有#号的情况,可以在r后面,加任意多的前后配对的#号, // 只要能帮助Rust编译器识别就行 let longer_delimiter = r###"A string with "# in it. And even "##!"###; println!("{}", longer_delimiter); }
一点小提示,Rust 中的字符串字面量都支持换行写,默认把换行符包含进去。
字节串
很多时候,我们的字符串字面量中用不到 Unicode 字符,只需要 ASCII 字符集。对于这种情况,Rust 还有一种更紧凑的表示法: 字节串。用 b 开头,双引号括起来,比如 b"this is a byte string"。这时候字符串的类型已不是字符串,而是字节的数组 [u8; N],N 为字节数。
你可以在 Playground 里面运行一下代码,看看输出什么。
fn main() { // 字节串的类型是字节的数组,而不是字符串了 let bytestring: &[u8; 21] = b"this is a byte string"; println!("A byte string: {:?}", bytestring); // 可以看看下面这串打印出什么 let escaped = b"\x52\x75\x73\x74 as bytes"; println!("Some escaped bytes: {:?}", escaped); // 字节串与原始字面量结合使用 let raw_bytestring = br"\u{211D} is not escaped here"; println!("{:?}", raw_bytestring); }
字节串很有用,特别是在做系统级编程或网络协议开发的时候,经常会用到。
数组
Rust 中的数组是 array 类型,用于存储同一类型的多个值。数组表示成[T; N],由中括号括起来,中间用分号隔开,分号前面表示类型,分号后面表示数组长度。
fn main() { let a: [i32; 5] = [1, 2, 3, 4, 5]; let a = [1, 2, 3, 4, 5]; }
Rust 中的数组是固定长度的,也就是说在编译阶段就能知道它占用的字节数,并且在运行阶段,不能改变它的长度(尺寸)。
听到这里你是不是想说,这岂不是很麻烦?Rust 中的数组竟然不能改变长度。这里我解释一下,Rust 中区分固定尺寸数组和动态数组。之所以做这种区分是因为 Rust 语言在设计时就要求适应不同的场合,要有足够的韧性能在不同的场景中都达到最好的性能。因为固定尺寸的数据类型是可以直接放栈上的,创建和回收都比在堆上动态分配的动态数组性能要好。
是否能在编译期计算出某个数据类型在运行过程中占用内存空间的大小, 这个指标很重要,Rust 的类型系统就是按这个对类型进行分类的。后面的课程中我们会经常用到这个指标。
数组常用于开辟一个固定大小的 Buffer(缓冲区),用来接收 IO 输入输出等。也常用已知元素个数的字面量集合来初始化,比如表达一年有 12 个月。
let months = ["January", "February", "March", "April", "May", "June", "July",
"August", "September", "October", "November", "December"];
数组的访问,可以用下标索引。
fn main() { let a: [i32; 5] = [1, 2, 3, 4, 5]; let b = a[0]; println!("{}", b) } // 输出 1
我们再来看看,如果下标索引越界了会发生什么。
fn main() { let a: [i32; 5] = [1, 2, 3, 4, 5]; let b = a[5]; println!("{}", b) }
提示:
Compiling playground v0.0.1 (/playground)
error: this operation will panic at runtime
--> src/main.rs:3:13
|
3 | let b = a[5];
| ^^^^ index out of bounds: the length is 5 but the index is 5
这时候你可能已经发现了,Rust 在编译的时候,就给我们指出了问题,说这个操作会在运行的时候崩溃。为什么 Rust 能指出来呢?就是因为 数组的长度是确定的,Rust 在编译时就分析并提取了这个数组类型占用空间长度的信息,因此直接阻止了你的越界访问。
不得不说,Rust 太贴心了。
动态数组
Rust 中的动态数组类型是 Vec(Vector),也就是向量,中文翻译成动态数组。它用来存储同一类型的多个值,容量可在程序运行的过程中动态地扩大或缩小,因此叫做动态数组。
fn main() { let v: Vec<i32> = Vec::new(); let v = vec![1, 2, 3]; let mut v = Vec::new(); v.push(5); v.push(6); v.push(7); v.push(8); }
动态数组可以用下标进行索引访问。
比如:
fn main() { let s1 = String::from("superman 1"); let s2 = String::from("superman 2"); let s3 = String::from("superman 3"); let s4 = String::from("superman 4"); let v = vec![s1, s2, s3, s4]; println!("{:?}", v[0]); } // 输出 "superman 1"
如果我们下标越界了会发生什么?Rust 能继续帮我们提前找出问题来吗?试一试就知道了。
fn main() { let s1 = String::from("superman 1"); let s2 = String::from("superman 2"); let s3 = String::from("superman 3"); let s4 = String::from("superman 4"); let v = vec![s1, s2, s3, s4]; // 这里下标访问越界了 println!("{:?}", v[4]); }
运行后,出现了提示。
Compiling playground v0.0.1 (/playground)
Finished dev [unoptimized + debuginfo] target(s) in 0.62s
Running `target/debug/playground`
thread 'main' panicked at 'index out of bounds: the len is 4 but the index is 4', src/main.rs:9:22
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
可以看到,这段代码正确通过了编译,但在运行的时候出错了,并且导致了主线程的崩溃。
你可以将其与前面讲的数组 array 下标越界时的预警行为对比理解。为什么 array 的越界访问能在编译阶段检查出来,而 Vec 的越界访问不能在编译阶段检查出来呢?你可以好好想一想。
哈希表
哈希表是一种常见的结构,用于存储 Key-Value 映射关系,基本在各种语言中都有内置提供。Rust 中的哈希表类型为 HashMap。对一个 HashMap 结构来说,Key 要求是同一种类型,比如是字符串就统一用字符串,是数字就统一用数字。Value 也是一样,要求是同一种类型。Key 和 Value 的类型不需要相同。
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); }
因为哈希表能从一个键索引到一个值,所以应用场景非常广泛,后面我们还会仔细分析它的用法。
Rust 中的复合类型
复合类型可以包含多种基础类型,是一种将类型进行有效组织的方式,提供了一级一级搭建更高层类型的能力。Rust 中的复合类型包括元组、结构体、枚举等。
元组
元组是一个固定(元素)长度的列表,每个元素类型可以不一样。用小括号括起来,元素之间用逗号隔开。例如:
fn main() { let tup: (i32, f64, u8) = (500, 6.4, 1); }
元组元素的访问:
fn main() { let x: (i32, f64, u8) = (500, 6.4, 1); // 元组使用.运算符访问其元素,下标从0开始,注意语法 let five_hundred = x.0; let six_point_four = x.1; let one = x.2; }
与数组的相同点是,它们都是固定元素个数的,在运行时不可伸缩。与数组的不同点是,元组的每个元素的类型可以不一样。元组在 Rust 中很有用,因为它可以用于 函数的返回值,相当于把多个想返回的值捆绑在一起,一次性返回。
当没有任何元素的时候,元组退化成 (),就叫做 unit 类型,是 Rust 中一个非常重要的基础类型和值,unit 类型唯一的值实例就是(),与其类型本身的表示相同。比如一个函数没有返回值的时候,它实际默认返回的是这个 unit 值。
结构体
结构体也是一种复合类型,它由若干字段组成,每个字段的类型可以不一样。Rust 中使用 struct 关键字来定义结构体。比如下面的代码就定义了一个 User 类型。
struct User {
active: bool,
username: String,
email: String,
age: u64,
}
下面这段代码演示了结构体类型的实例化。
fn main() { let user1 = User { active: true, username: String::from("someusername123"), email: String::from("someone@example.com"), age: 1, }; }
枚举
Rust 中使用 enum 关键字定义枚举类型。比如:
enum IpAddrKind {
V4,
V6,
}
枚举类型里面的选项叫做此枚举的变体(variants)。变体是其所属枚举类型的一部分。
枚举使用变体进行枚举类型的实例化,比如:
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
可以看到,枚举类型也是一种复合类型。但是与结构体不同,结构体类型是里面的所有字段(所有类型)同时起作用,来产生一个具体的实例,而枚举类型是其中的一个变体起作用,来产生一个具体实例,这点区别可以细细品味。学术上,通常把枚举叫作 和类型(sum type),把结构体叫作 积类型(product type)。
枚举类型是 Rust 中最强大的复合类型,在后面的课程中我们会看到,枚举就像一个载体,可以携带任何类型。
Rust 中的控制流
下面我们来了解一下 Rust 语言的控制流语句。
分支语句
Rust 中使用 if else 来构造分支。
fn main() { let number = 6; // 判断数字number能被4,3,2中的哪一个数字整除 if number % 4 == 0 { println!("number is divisible by 4"); } else if number % 3 == 0 { println!("number is divisible by 3"); } else if number % 2 == 0 { println!("number is divisible by 2"); } else { println!("number is not divisible by 4, 3, or 2"); } }
与其他 C 系语言不同,Rust 中 if 后面的条件表达式不推荐用()包裹起来,因为 Rust 设计者认为那个是不必要的,是多余的语法噪音。
还要注意一点,if else 支持表达式返回。
fn main() { let x = 1; // 在这里,if else 返回了值 let y = if x == 0 { // 代码块结尾最后一句不加分号,表示把值返回回去 100 } else { // 代码块结尾最后一句不加分号,表示把值返回回去 101 }; println!("y is {}", y); }
像上面这样的代码,其实已经实现了类似于 C 语言中的三目运算符这样的设计,在 Rust 中,不需要额外提供那样的特殊语法。
循环语句
Rust 中有三种循环语句,分别是 loop、while、for。
- loop 用于无条件(无限)循环。
fn main() { let mut counter = 0; // 这里,接收从循环体中返回的值,对result进行初始化 let result = loop { counter += 1; if counter == 10 { // 使用break跳出循环,同时带一个返回值回去 break counter * 2; } }; println!("The result is {result}"); }
请仔细品味这个例子,这种 返回一个值到外面对一个变量初始化的方式,是 Rust 中的习惯用法,这能让代码更紧凑。
- while 循环为条件判断循环。当后面的条件为真的时候,执行循环体里面的代码。和前面的 if 语句一样,Rust 中的 while 后面的条件表达式不推荐用()包裹起来。比如:
fn main() { let mut number = 3; while number != 0 { println!("{number}!"); number -= 1; } println!("LIFTOFF!!!"); }
- for 循环在 Rust 中,基本上只用于迭代器(暂时可以想象成对数组,动态数组等)的遍历。Rust 中没有 C 语言那种 for 循环风格的语法支持,因为那被认为是一种不好的设计。
你可以看一下下面的代码,就是对一个数组进行遍历。
fn main() { let a = [10, 20, 30, 40, 50]; for element in a { println!("the value is: {element}"); } }
上面代码对动态数组 Vec 的遍历阻止了越界的可能性,因此用这种方式访问 Vec 比用下标索引的方式访问更加安全。
对于循环的场景,Rust 还提供了一个便捷的语法来生成遍历区间: ..(两个点)。
请看下面的示例。
fn main() {
// 左闭右开区间
for number in 1..4 {
println!("{number}");
}
println!("--");
// 左闭右闭区间
for number in 1..=4 {
println!("{number}");
}
println!("--");
// 反向
for number in (1..4).rev() {
println!("{number}");
}
}
// 输出
1
2
3
--
1
2
3
4
--
3
2
1
我们再来试试打印字符。
fn main() { for ch in 'a'..='z' { println!("{ch}"); } } // 输出: a b c d e f g h i j k l m n o p q r s t u v w x y z
嘿,Rust 很智能啊!
Rust 中的函数和模块
最后我们来看 Rust 的函数、闭包和模块,它们用于封装和复用代码。
函数
函数基本上是所有编程语言的标配,在 Rust 中也不例外,它是一种基本的代码复用方法。在 Rust 中使用 fn 关键字 来定义一个函数。比如:
fn print_a_b(a: i32, b: char) { println!("The value of a b is: {a}{b}"); } fn main() { print_a_b(5, 'h'); }
函数定义时的参数叫作 形式参数(形参),函数调用时传入的参数值叫做 实际参数(实参)。函数的调用要与函数的签名(函数名、参数个数、参数类型、参数顺序、返回类型)一致,也就是实参和形参要匹配。
函数对于几乎所有语言都非常重要,实际上各种编程语言在实现时,都是以函数作为基本单元来组织栈上的内存分配和回收的,这个基本的内存单元就是所谓的 栈帧(frame),我们在下节课会讲到。
闭包(Closure)
闭包是另一种风格的函数。它使用两个竖线符号 || 定义,而不是用 fn () 来定义。你可以看下面的形式对比。
// 标准的函数定义
fn add_one_v1 (x: u32) -> u32 { x + 1 }
// 闭包的定义,请注意形式对比
let add_one_v2 = |x: u32| -> u32 { x + 1 };
// 闭包的定义2,省略了类型标注
let add_one_v3 = |x| { x + 1 };
// 闭包的定义3,花括号也省略了
let add_one_v4 = |x| x + 1 ;
注:可参考完整代码 链接
闭包与函数的一个显著不同就是,闭包可以捕获函数中的局部变量为我所用,而函数不行。比如,下面示例中的闭包 add_v2 捕获了 main 函数中的局部变量 a 来使用,但是函数 add_v1 就没有这个能力。
fn main() { let a = 10u32; // 局部变量 fn add_v1 (x: u32) -> u32 { x + a } // 定义一个内部函数 let add_v2 = |x: u32| -> u32 { x + a }; // 定义一个闭包 let result1 = add_v1(20); // 调用函数 let result2 = add_v2(20); // 调用闭包 println!("{}", result2); }
这样会编译出错,并提示错误。
error[E0434]: can't capture dynamic environment in a fn item
--> src/main.rs:4:40
|
4 | fn add_v1 (x: u32) -> u32 { x + a } // 定义一个内部函数
| ^
|
= help: use the `|| { ... }` closure form instead
闭包之所以能够省略类型参数等信息,主要是其定义在某个函数体内部,从闭包的内容和上下文环境中能够分析出来那些类型信息。
模块
我们不可能把所有代码都写在一个文件里面。代码量多了后,分成不同的文件模块书写是非常自然的事情。这个需求需要从编程语言层级去做一定的支持才行,Rust 也提供了相应的方案。
分文件和目录组织代码理解起来其实很简单,主要的知识点在于目录的组织结构上。比如下面示例:
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden // 子目录
│ └── vegetables.rs
├── garden.rs // 与子目录同名的.rs文件,表示这个模块的入口
└── main.rs
第五行代码到第七行代码组成 garden 模块,在 garden.rs 中,使用 mod vegetables; 导入 vegetables 子模块。
在 main.rs 中,用同样的方式导入 garden 模块。
mod garden;
整个代码结构就这样一层一层地组织起来了。
另一种文件的组织形式来自 2015 版,也很常见,有很多人喜欢用。
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden // 子目录
│ └── mod.rs // 子目录中有一个固定文件名 mod.rs,表示这个模块的入口
│ └── vegetables.rs
└── main.rs
同上,由第五行到第七行代码组成 garden 模块,在 main.rs 中导入它使用。
你可以在本地创建文件,来体会两种不同目录组织形式的区别。
测试
Rust 语言中自带单元测试和集成测试方案。我们来看一个示例,在 src/lib.rs 或 src/main.rs 下有一段代码。
fn foo() -> u32 { 10u32 }
#[cfg(test)] // 这里配置测试模块
mod tests {
use crate::foo;
#[test] // 具体的单元测试用例
fn it_works() {
let result = foo(); // 调用被测试的函数或功能
assert_eq!(result, 10u32); // 断言
}
}
在项目目录下运行 cargo test,会输出类似如下结果。
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Rust 自带测试方案,让我们能够非常方便地写测试用例,并且统一了社区的测试设计规范。
配置文件 Cargo.toml
这节课开头的时候,我们简单介绍过 Cargo.toml,它是 Rust 语言包和依赖管理器 Cargo 的配置文件,由官方定义约定。写 Rust 代码基本都会按照这种约定来使用它,对所在工程进行配置。这里面其实包含的知识点非常多,后面实战的部分,我们会详细解释用到的特性。
我们要对包依赖这件事情的复杂度有所了解。不知道你有没有听说过 npm 依赖黑洞?指的就是 Node.js 的包依赖太多太琐碎了。这怪不得 Node.js,其实 Rust 也类似。包依赖这件事儿,本身就很复杂,可以说这是软件工程固有的复杂性。对固有复杂性,不能绕弯过,只能正面刚。
幸运的是,Cargo 工具已经帮我们搞定了包依赖相关方方面面的麻烦事(此刻 C++社区羡慕不已)。为了应对这种复杂性,Cargo 工具的提供了非常多的特性,配置起来也相对比较复杂。有兴趣的话,你可以详细了解一下 各种配置属性。
小结
这节课我们洋洋洒洒罗列了写一个 Rust 程序所需要用到的基本的语法结构和数据类型,让你对 Rust 语言有了一个初步印象。这些知识点虽多,但并不复杂。因为这节课呈现的绝大部分元素都能在其他语言中找到,所以理解起来应该不算太难。
这节课出现了一个比较重要的指标: 是否能在编译期计算出某个数据类型在运行过程中占用的内存空间的大小。如果能计算出,那我们称之为固定尺寸的数据类型;如果不能计算出,那我们称之为不固定尺寸的数据类型,或动态数据类型。
其实这也很好理解,因为 Rust 要尽量在编译期间多做一些事情,帮我们做安全性的检查。而在编译期只有能计算出内存尺寸的数据类型,才能被更详尽地去分析和检查,就是这个原理。
思考题
- Rust 中能否实现类似 JS 中的 number 这种通用的数字类型呢?
- Rust 中能否实现 Python 中那种无限大小的数字类型呢?
希望你可以积极思考这几个问题,然后把你的答案分享到评论区,如果你觉得这节课对你有帮助的话,也欢迎你分享给你的朋友,邀他一起学习,我们共同进步。下节课再见!
所有权(上):Rust是如何管理程序中的资源的?
你好,我是Mike。今天我们来讲讲Rust语言设计的出发点——所有权,它也是Rust的精髓所在。
在第一节课中,我们了解了Rust语言里的值有两大类:一类是固定内存长度(简称固定尺寸)的值,比如 i32、u32、由固定尺寸的类型组成的结构体等;另一类是不固定内存长度(简称非固定尺寸)的值,比如字符串String。这两种值的本质特征完全不一样。而 怎么处理这两种值的差异,往往是语言设计的差异性所在。
就拿数字类型来说,C、C++、Java 这些语言就明确定义了数字类型会占用内存中的几个字节,比如8位,也就是一个字节,16位,也就是两个字节。而JavaScript这种语言,就完全屏蔽了底层的细节,统一用一个Number表示数字。Python则给出了int整数、float浮点、complex复数三种数字类型。
Rust语言因为在设计时就定位为一门通用的编程语言(对标C++),它的应用范围很广,从最底层的嵌入式开发、OS开发,到最上层的Web应用开发,它都要兼顾。所以它的数字类型不可避免地就得暴露出具体的字节数,于是就有了i8、i16、i32、i64等类型。
前面我们说到,一种类型如果具有固定尺寸,那么它就能够在编译期做更多的分析。实际上固定尺寸类型也可以用来管理非固定尺寸类型。具体来说,Rust中的非固定尺寸类型就是靠指针或引用来指向,而指针或引用本身就是一种固定尺寸的类型。
栈与堆
现代计算机会把内存划分为很多个区。比如,二进制代码的存放区、静态数据的存放区、栈、堆等。
栈上的操作比堆高效,因为栈上内存的分配和回收只需移动栈顶指针就行了。这就决定了分配和回收时都必须精确计算这个指针的增减量,因此 栈上一般放固定尺寸的值。另一方面,栈的容量也是非常有限的,因此也不适合放尺寸太大的值,比如一个有1000万个元素的数组。
那么非固定尺寸的值怎么处理呢?在计算机体系架构里面,专门在内存中拿出一大块区域来存放这类值,这个区域就叫“堆”。
栈空间与堆空间
在一般的程序语言设计中,栈空间都会与函数关联起来。每一个函数的调用,都会对应一个帧,也叫做 frame 栈帧,就像图片栈空间里的方块 main、fn1、fn2等。一个函数被调用,就会分配一个新的帧,函数调用结束后,这个帧就会被自动释放掉。因此 栈帧是一个运行时的事物。函数中的参数、局部变量之类的资源,都会放在这个帧里面,比如图里fn2中的局部变量a,这个帧释放时,这些局部变量就会被一起回收掉。
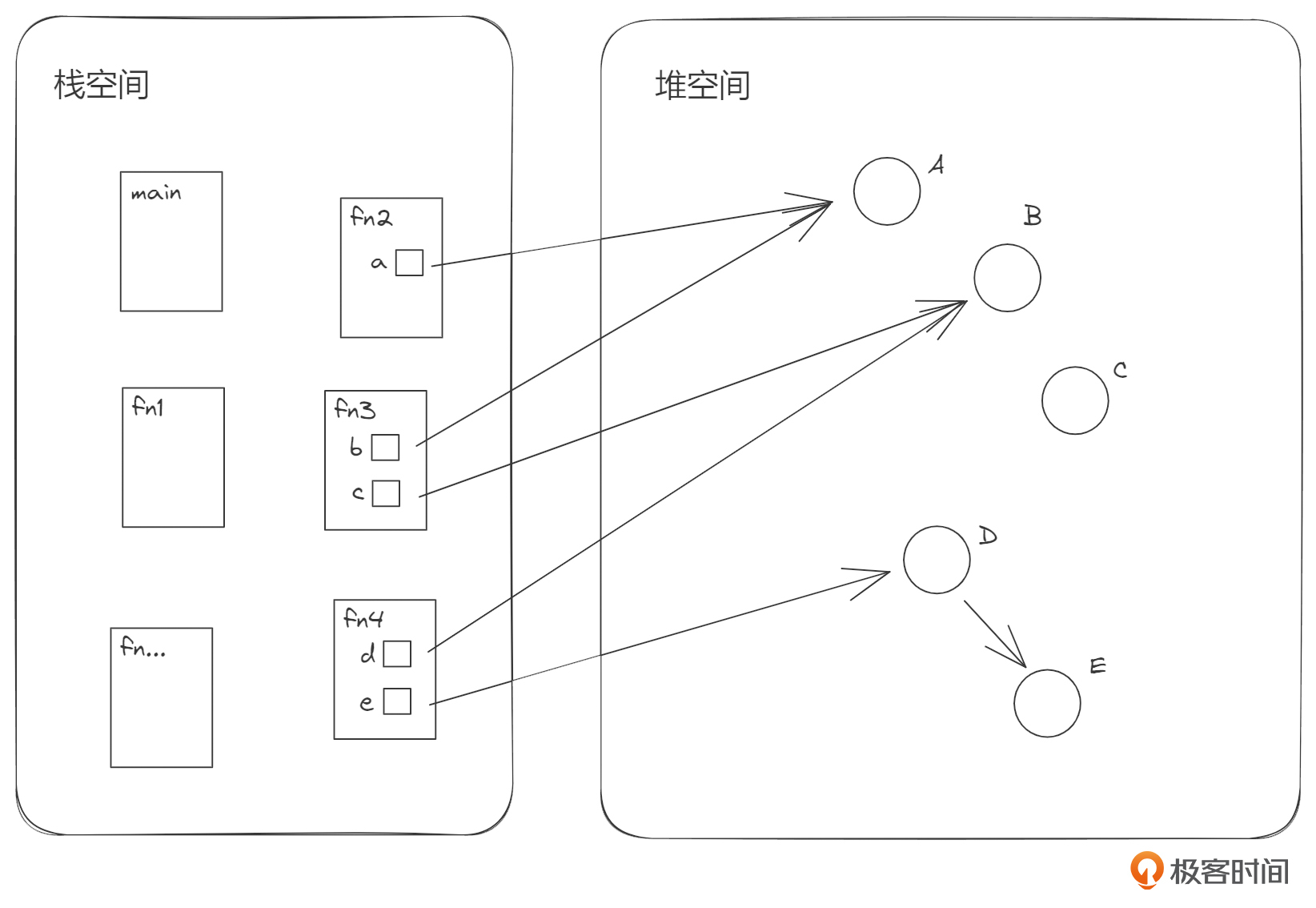
函数的调用会形成层级关系,因此栈空间中的帧可能会同时存在很多个,并且在它们之间也对应地形成层级关系。如上图所示,可能的函数调用关系为,main函数中调用了函数fn1,fn1中调用了函数fn2,fn2中调用了函数fn3,fn3中调用了函数fn4,fn4调用了更深层次的其他函数。这样的话,在程序执行的某个时刻,main函数、fn1、fn2、fn3、fn4 等对应的帧副本就同时存在于栈中了。
图中右边堆空间里面的一些小圈表示堆空间中资源,也就是被分配的内存。从图中可以看到,栈空间中函数帧的局部变量是可以引用这些堆上资源的。一个栈帧中的多个局部变量可以指向堆中的多个资源,如fn3中的b指向资源A,c指向资源B;同时存在的多个栈帧中的局部变量还可以指向堆上的同一个资源,如图中的a和b,c和d;堆上的资源也可以存在引用关系,如图中的D和E。
如果一个资源没有被任何一个栈帧中的变量引用或间接引用,如图中的C,那么它实际是一个被泄漏的资源,也就是发生了内存泄漏。被泄漏的资源会一直伴随程序的运行,直到程序自身的进程被停止时,才会一起被OS回收掉。
而计算机程序内存管理的复杂性,主要就在于 堆内存的管理比较复杂——既要高效,又要安全。
这里我们稍微提及了一点计算机的结构知识,你可以停下来仔细理解这张图示表达的意思,在后面我们还会经常回顾这张图。有了栈和堆的知识作为铺垫,你会更容易理解Rust中的一些特性为什么要那样设计。
下面我们回到Rust语言,继续讲Rust中另一个重要概念——可变性。
变量与可变性
回顾第一讲的知识,在Rust中定义一个变量,使用 let variable = value; 这种语法。比如 let x = 10u32;,就定义了变量 x。然后,10u32是一个值,它被绑定到这个变量上。
默认变量是不可变的,我们来做个实验。
fn main() { let x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); }
输出:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| -
| |
| first assignment to `x`
| help: consider making this binding mutable: `mut x`
3 | println!("The value of x is: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
Rust默认这样做是为了减少一些很低级的Bug。假如默认可以改的话,如果你在一个代码量很大而且离定义变量很远的某个分支语句里面修改了这个变量的值,然后在后面某个函数调用里面又用到了它,结果导致程序行为与期望不符,这时你很难看出来问题出在哪儿。这种低级错误能不犯就不犯,Rust干脆帮你禁用了这种方式。
但是下面这样做是可以的。
fn main() { let x = 5; println!("The value of x is: {x}"); let x = 6; // 注意这里,重新使用了 let 来定义新变量 println!("The value of x is: {x}"); }
这种方式在Rust中叫做变量的Shadowing。意思很好理解,就是定义了一个新的变量名,只不过这个变量名和老的相同。原来那个变量就被遮盖起来了,访问不到了。这种方式最大的用处是程序员不用再去费力地想另一个名字了!变量的Shadow甚至支持新的变量的类型和原来的不一样。
比如:
fn main() { let a = 10u32; let a = 'a'; println!("{}", a); }
那如果我们要修改变量的值应该怎么做呢?只需要在变量名前面加一个mut就可以声明一个变量为可以修改内容的。
let mut x = 10u32;
例子:
fn main() { let mut x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); } // 输出 The value of x is: 5 The value of x is: 6
注意,值的改变只能在同一种类型中变化,在变量x定义的时候,就已经确定了变量x的类型为数字了,你可以试试将其改成字符串,看会报什么错误。
这里你可以回过头去对比一下,可修改变量和变量的Shadow的不同之处。
一个变量,其内容是否可变,被称作这个变量的 可变性(mutability)。mut 叫作可变性修饰符(modifier)。
可能你会非常疑惑,变量不就应该是会变化的吗? 既然默认不可变,为什么要称其为变量呢?其实上面一段我已经回答了这个问题,Rust中变量的可变性是一种潜力,只要它有可能会变化,那么就可以称之为变量。而Rust给这种潜力加了一道开关, 当你想让这个变量的可变性暴露出来的时候,就在变量名前面明确地加个mut修饰符。
可以看到,变量名加了mut,多打了4个字符,这实际是在代码中留下了一种足迹。也就是说给了程序员一个信息,当你自己或别的程序员在读到这个变量的定义时,他会知道,后面一定会修改这个变量,因为如果你后面没修改它,Rust编译器会提示你把这个mut去掉。
这种设计还有一个好处,那就是减少滥用概率。我们在这里构造一个编程语言界的墨菲定律, 如果一个特性不太利于程序的健壮性,但是很好用,滥用的成本非常低,那么它一定会被滥用。
比如 TypeScript 中的 any 类型,有时写TS代码懒得去设计类型,直接就用any类型了,反正“先跑通了再说”。结果就是最后项目完成了,代码里面any满天飞,TS的设计初衷被抛至脑后。偷懒是人的天性,Rust接受了这种天性,让你想要修改一个变量的时候,需要多付出点成本,也就是多打4个字符。
另一个例子是 JS 中的 var 和 let,都是三个字符,敲的字符数一样,成本一样,结果就是在语言层面并不能驱动程序员往好的实践方面靠。有人会辩称,在这些语言中会有推荐规范或强制要求,要求你按好的实践方式写。不过在实际项目中,由于进度等问题,这些规范总是很难完全贯彻下去,即使贯彻下去也很难达到预期效果,这方面已有太多案例了。因为那些都是补救措施,哪有从语言层面强制约束你做来得统一。
变量的类型
值是有类型的,比如 10u32,它就是一个u32类型的数字。一旦一个变量绑定了一个值,或者说一个值被绑定到了一个变量上,那么这个变量就被指定为这种值的类型。比如 let x = 10u32; 编译器会自动推导出变量x的类型为 u32。完整的写法就是 let x: u32 = 10u32;。
此外还有一种方式,就是直接先指定变量的类型,然后把一个值绑定上去,比如 let x: u32 = 10;。这种方式更好, 它能说明你在写这句代码的时候就已经对它做了一个架构上的规划和设计,这种形式能帮助我们在编译阶段阻止一些错误。
比如输入下面这段代码:
fn main() { let a: u8 = 323232; println!("{a}"); }
编译器就会报错,指出u8类型装不下这么大的一个数字。
error: literal out of range for `u8`
--> src/main.rs:5:17
|
5 | let a: u8 = 323232;
| ^^^^^^
|
= note: the literal `323232` does not fit into the type `u8` whose range is `0..=255`
看到这个错误,你是不是感觉Rust特别贴心。同样的代码,你可以放在其他语言中实现,做一下对比。
所有的变量都应该具有明确的类型是Rust程序的基本设计。 当然其他语言中也有类型,不同语言对类型重视的程度不一样,这取决于语言自身的设计定位。
好了,变量的概念我们先解析到这里,下面我们来看一个Rust中的“奇怪”行为。
Rust中“奇怪”的行为
我们先来看一个例子。
fn main() { let a = 10u32; let b = a; println!("{a}"); println!("{b}"); }
很简单,它打印出:
10
10
然后我们再来看字符串的行为,你猜一下程序会输出什么。
fn main() { let s1 = String::from("I am a superman."); let s2 = s1; println!("{s1}"); println!("{s2}"); }
是两行“I am a superman”吗?反正在其他语言中是这样的。
结果在Rust中不是,编译器给出了出错信息,我们来看看。
Compiling playground v0.0.1 (/playground)
error[E0382]: borrow of moved value: `s1`
// 借用了移动后的值 `s1`
--> src/main.rs:4:15
|
2 | let s1 = String::from("I am a superman.");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
// 移动发生了,因为 `s1` 的类型是 `String`,而这种类型并没有实现 `Copy` trait."。
3 | let s2 = s1;
| -- value moved here
// 在这里值移动了。
4 | println!("{s1}");
| ^^^^ value borrowed here after move
// 值在被移动后在这里被借用
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
// 如果性能成本可以接受的话,考虑克隆这个值
|
3 | let s2 = s1.clone();
| ++++++++
既然给出了修改建议,那我们直接照着代码建议改一下试试。
fn main() { let s1 = String::from("I am a superman."); let s2 = s1.clone(); println!("{s1}"); println!("{s2}"); }
好了,这下输出我们预期的结果了。
I am a superman.
I am a superman.
Rust中的字符串为何有如此奇怪的行为呢?
所有权
首先,我们看到在Rust中,字符串的行为好像与u32这种数字类型不一样。前面我们说过,u32这种类型是固定尺寸类型,而String是非固定尺寸类型。一般来说,对于固定尺寸类型,会默认放在栈上;而非固定尺寸类型,会默认创建在堆上,成为堆上的一个资源,然后在栈上用一个局部变量来指向它,如代码中的s1。
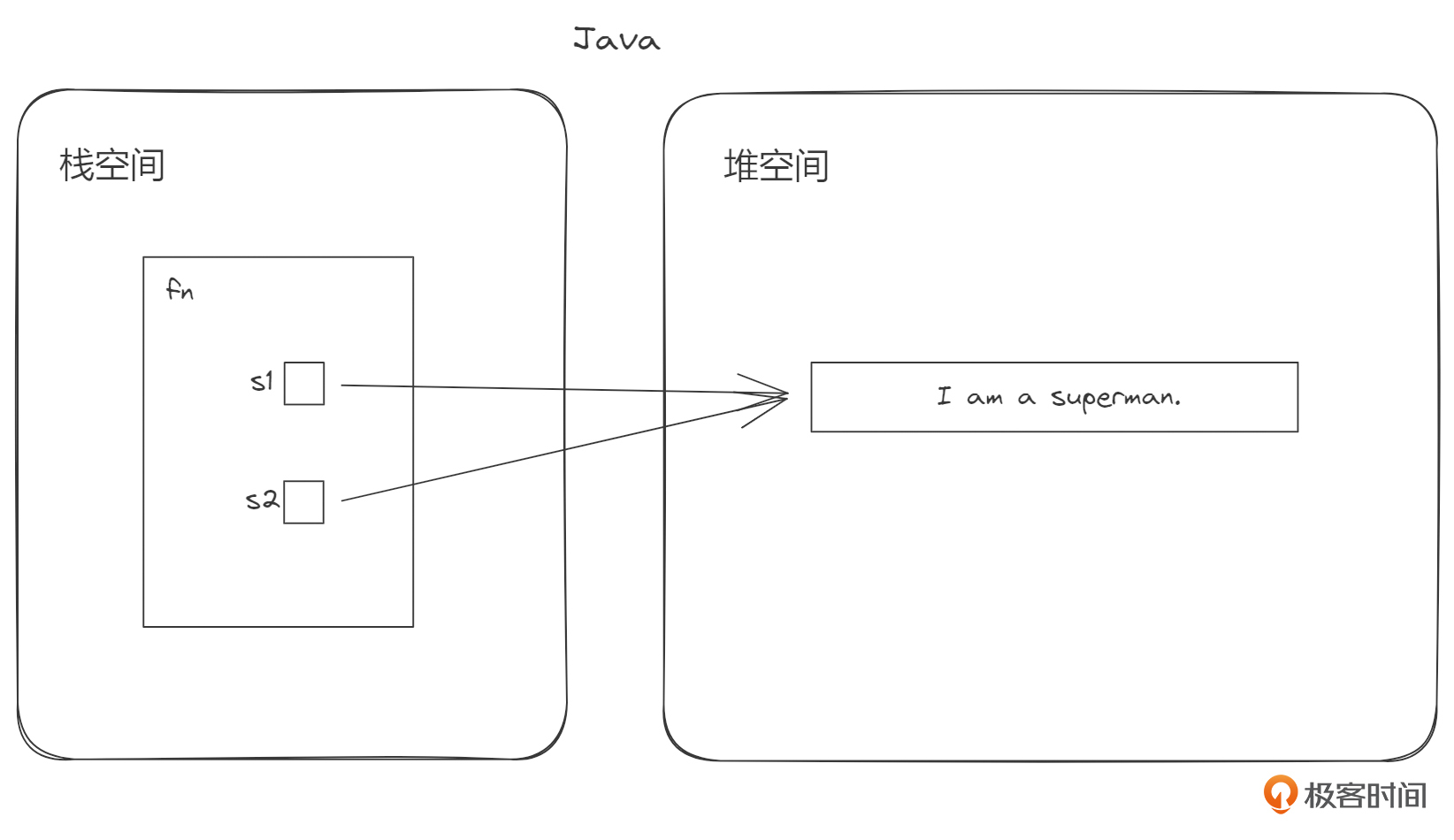
在将一个变量赋值给另一个变量的时候,不同语言对底层细节的处理不一样。这里我们拿Java举例。前面我们说过,局部变量都是定义在栈帧中的,Java也是一样。Java语言对于int这类固定尺寸类型,在复制给另一个变量的时候,会直接复制它的值。在面对Object这种复杂对象的时候,默认只会复制这个Object的引用给另一个变量。这个引用的值(内存地址)就存在栈上的局部变量里面。
为什么会这样设计呢?因为如果那个Object占用的内存很大,每一次重新赋值,就把那个对象重新拷贝一次,也就是完全克隆,是非常低效的,凡是脑筋正常的语言都不会那样干。所以在用Java编程时,它实际上是隐藏了对象 引用的复制 这个细节。
回到Rust,我们看到对于u32这种固定尺寸类型来说,Rust与Java也是同样的处理,直接在栈上进行内容的拷贝。而对于字符串这种动态长度的类型来说,在变量的再赋值上,Rust除了拷贝字符串的引用外,实际还做了更多事情。具体是什么事情呢?我们先来看一下修改后的例子。
fn main() { let s1 = String::from("I am a superman."); let s2 = s1; //println!("{s1}"); println!("{s2}"); }
这个例子,就能正常打印。
I am a superman.
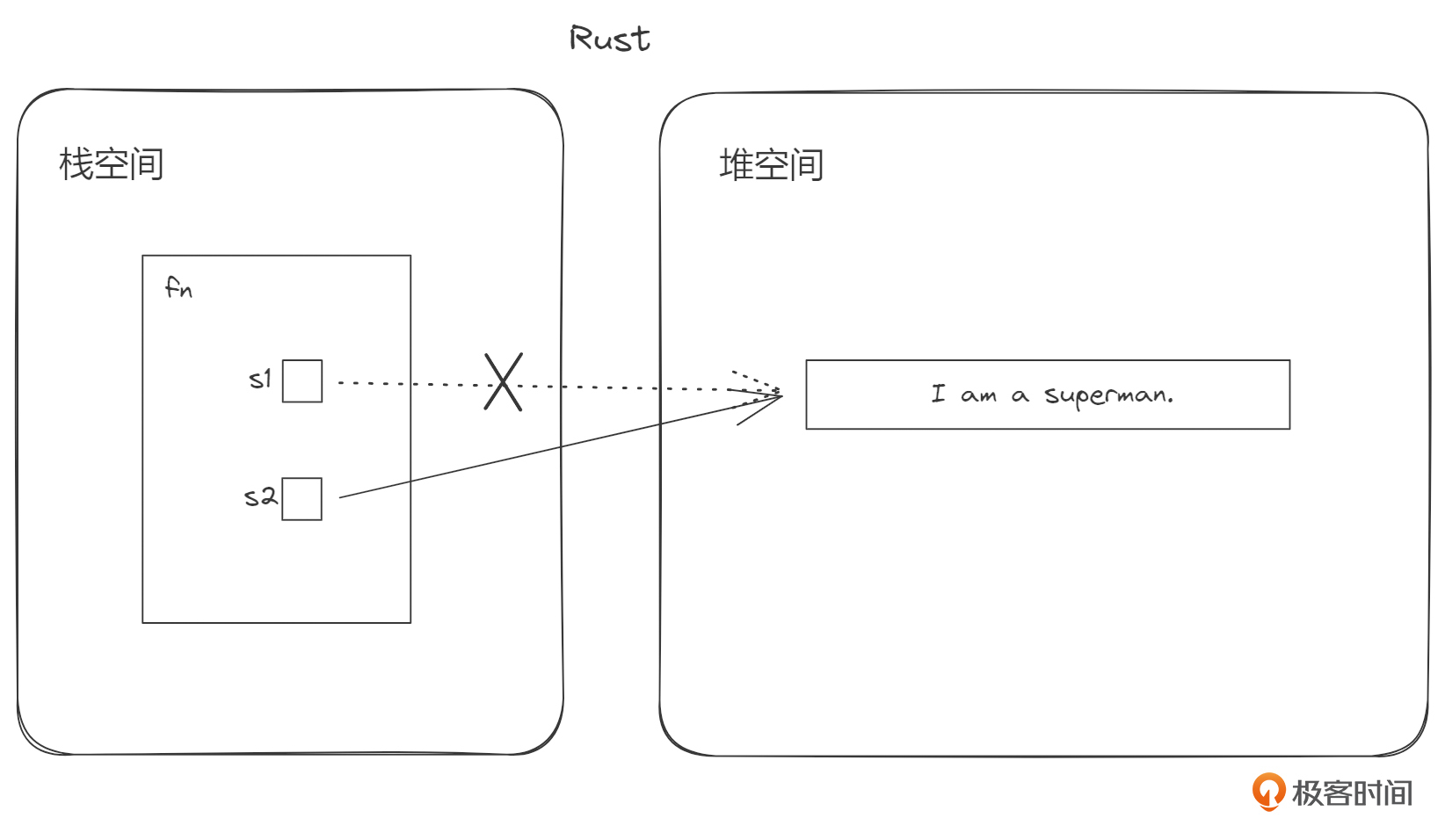
对比之后,我们发现 let s2 = s1; 语句执行后,s2可以使用,而s1不能再使用了。也就是说,在Rust里面,s1把内容“复制”给s2后,s2可用,s1不能用了!
从代码层面我们也可以说,s1把值(资源)“移动”给了s2。既然是移动了,那原来的变量就没有那个值了。请仔细体会这里与Java的不同之处。Java默认做了引用的拷贝,并且新旧两个变量同时指向原来那个对象。而Rust不一样, Rust虽然也是把字符串的引用由s1拷贝到了s2,但是只保留了最新的s2到字符串的指向,同时却把s1到字符串的指向给“抹去”了。 s1之后都处于一种“不可用”的状态,直到函数结束。这就是Rust编译器做的那个“更多”的部分。
下面的图示展示了这两种行为上的差异。
好奇怪呀!Rust怎么会这样设计呢?
其实这正是Rust从头开始梳理整个软件体系的地方,剑指一个目标: 内存安全。
所有权
长久以来,计算机领域最聪明的大脑都在探索如何写出更安全的程序,为此建立了各种理论、模式、模型。而Rust不走寻常路,它采用了一种全新的思路,利用所有权来管理内存资源,保证内存安全。接下来我们就一起来好好品鉴一下这个独特的思路。此刻 ,请你先卸下之前固有的思维,将脑袋放空一下。
Rust明确了所有权的概念,值也可以叫资源,所有权就是拥有资源的权利。一个变量拥有一个资源的所有权,那它就要负责那个资源的回收、释放。 Rust基于所有权定义出发,推导出了整个世界。
所有权的基础是三条定义。
- Rust中,每一个值都有一个所有者。
- 任何一个时刻,一个值只有一个所有者。
- 当所有者所在作用域(scope)结束的时候,其管理的值会被一起释放掉。
这三条规则涉及两个概念: 所有者和作用域。
所谓所有者,在代码里就用变量表示。而变量的作用域,就是变量有效(valid)的那个代码区间。在Rust中,一个所有权型变量的作用域,简单来说就是它定义时所在的那个最里层的花括号括起的部分,从变量创建时开始,到花括号结束的地方。
比如:
fn main() { let s = String::from("hello"); // do stuff with s } // 变量s的作用域到这里结束 fn main() { let a = 1u32; { let s = String::from("hello"); } // 变量s的作用域到这里结束 // xxxx } // 变量a的作用域到这里结束
变量在其作用域内是有效的,离开作用域就无效了。
好,理解了这一点,我们现在尝试用所有权规则去翻新一下对前面例子的理解。
fn main() { let a = 10u32; let b = a; println!("{a}"); println!("{b}"); }
在这个例子中,a具有对值 10u32的所有权。执行 let b = a 的时候,把值 10u32 复制了一份,b具有对这个新的10u32值的所有权。当main函数结束的时候,a、b两个变量就离开了作用域,其对应的两个10u32,就都被回收了。这里是栈帧结束,栈帧内存被回收,局部变量位于栈帧中,所以它们所占用的内存就被回收了。
再来看一个字符串的例子。
fn main() { let s1 = String::from("I am a superman."); println!("{s1}"); }
局部变量s1拥有这个字符串的所有权。s1的作用域从定义到开始,直到花括号结束。s1(栈帧上的局部变量)离开作用域时,变量s1上绑定的内存资源(字符串)就被回收掉了。注意,这里发生的事情是,栈帧中的局部变量离开作用域了,顺带要求堆内存中的字符串资源被回收。之所以能够做到这一点,是因为这个堆中的字符串资源被栈帧中的局部变量所指向了的。
而从Rust的语法层面看起来,就是变量s1对那个字符串拥有所有权。所以s1离开作用域的时候,那个资源就一起被回收了。这看起来好像是一个自动的过程,我们并没有像C语言中那样,需要手动调用free()函数去释放堆中的字符串资源。
这种 堆内存资源随着关联的栈上局部变量一起被回收 的内存管理特性,叫作 RAII(Resource Acquisition Is Initialization)。它实际不是Rust的原创,而是C++创造的。如果你学过C的话,可以对比一下C中的malloc()分配堆内存的方式,在分配堆内存后,C语言里面必须由程序员手动在后续的代码中使用free()来释放堆内存中的资源。而有了RAII特性后,我们不需要手动写free(),因此可以认为RAII内存管理方式是一个相当大的进步。
有了所有权的知识后,我们再回过头来分析上面那个例子。
fn main() { let s1 = String::from("I am a superman."); let s2 = s1; //println!("{s1}"); println!("{s2}"); }
变量s1持有这个字符串的所有权。s1对字符串的所有权从第2行定义时开始,到 let s2 = s1 执行后结束。这一行执行后,s2持有那个字符串的所有权。而此时s1处于什么状态呢?处于一种不可用的状态,或者叫无效状态(invalid),这个状态是由Rust编译器在编译阶段帮我们管理的,我们只需要从所有权模型去理解它,而不需要操心细节。Rustc小助手把这些事情给我们打理得明明白白的。
然后直到花括号结束,s2及s2所拥有的字符串内存,就被回收掉了,s1所对应的那个局部变量的内存空间也一并被回收了。
所有权是Rust语言的出发点,我们写的任何Rust程序,都必须遵循这套规则。
需要注意的一点是,所有权其实是内存结构之上的更上层概念,并不是说只有在堆中分配的资源才有所有权。实际上,栈上的资源也是有所有权的。所有权这个概念实际上屏蔽了底层内存结构的细节,让我们可以站在一个新的层次上更有效地对问题进行建模。
这个思维一定要注意,Rust语言中并不是所有的分析都需要归结到内存结构上去才能搞清楚,思维一直停留在内存结构上,有时会妨碍你的抽象建模能力,就像你精通量子力学不一定能当一个好的建筑师,所以这一点尤其要注意。
使用所有权书写函数
下面我们来看一下,基于所有权规则,函数的写法会变成什么样。
fn foo(s: String) { println!("{s}"); } fn main() { let s1 = String::from("I am a superman."); foo(s1); }
输出:
I am a superman.
没问题。
稍微改动一下例子,我们想在函数调用结束后,在外面再打印一下s1的值。
fn foo(s: String) { println!("{s}"); } fn main() { let s1 = String::from("I am a superman."); foo(s1); println!("{s1}"); // 这里加了一行 }
咦,编译出错了。提示:
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:8:16
|
6 | let s1 = String::from("I am a superman.");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
7 | foo(s1);
| -- value moved here
8 | println!("{s1}");
| ^^ value borrowed here after move
|
note: consider changing this parameter type in function `foo` to borrow instead if owning the value isn't necessary
--> src/main.rs:1:11
|
1 | fn foo(s: String) {
| --- ^^^^^^ this parameter takes ownership of the value
| |
| in this function
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
7 | foo(s1.clone());
| ++++++++
这个例子在其他语言中,一般是不会有问题的。foo函数也许会修改字符串的值,在外面重新打印的时候,会打印出新的值。但是,这其实是一种相当隐晦的设计模式,可能会造成一些错误(在下一讲我们会讲到),而Rust阻止了这种模式。
这个例子代码的提示与前面差不多,就是说s1所有权已经被移动进函数里面了,不能在移动后再使用了。
注意提示中的这一行:
1 | fn foo(s: String) {
| --- ^^^^^^ this parameter takes ownership of the value
函数的参数s获取了这个值的所有权。函数参数是这个函数的一个局部变量,它在这个函数栈帧结束的时候会被回收,因此这个字符串在这个函数调用结束后,就已经被回收了,这就是我们无法再打印这个字符串的原因。
同样我们再看一个上面例子的变形。
fn foo(s: String) { println!("{s}"); } fn main() { let s1 = String::from("I am a superman."); foo(s1); foo(s1); }
我们简单地想调用两次 foo() 函数都做不到,原因跟前面是一样的。这就是Rust有点反直觉的地方,也是令很多初学者崩溃的地方。原因我们再重复一下,一个苹果,你给了别人,那你就没有了。一个知识,我教给了你,我们都会得到。Rust的编程模型默认选择了前者,而以往的主流编程语言默认选择了后者。
回到前面例子,那我们后面的代码还想用s1,该怎么办?
可以这样,既然能把所有权移动到函数里面,也当然能把所有权转移出来。
fn foo(s: String) -> String { println!("{s}"); s } fn main() { let s1 = String::from("I am a superman."); let s1 = foo(s1); println!("{s1}"); }
这样就输出了结果:
I am a superman.
I am a superman.
我们适配了Rust的所有权规则,实现了我们期望的函数调用效果。
移动还是复制
前面讲到,u32这种类型在做变量的再赋值的时候,是做了复制所有权的操作。而String这种类型在做变量再赋值的时候,是做了移动所有权的操作。那么,在Rust中哪些类型默认是做移动所有权操作,哪些类型默认是做复制所有权操作呢?
默认做复制所有权的操作的有7种。
- 所有的整数类型,比如u32;
- 布尔类型bool;
- 浮点数类型,比如f32、f64;
- 字符类型char;
- 由以上类型组成的元组类型 tuple,如(i32, i32, char);
- 由以上类型组成的数组类型 array,如 [9; 100];
- 不可变引用类型&。
其他类型默认都是做移动所有权的操作。
小结
所有权是Rust语言中非常重要的一个概念,用于 管理程序中使用的资源。这些资源可以是堆上的动态分配的内存资源,也可以是栈上的内存资源,或者是其他的系统资源,比如IO资源。所有权通过把语句绑定在变量上,封装了栈和堆的实现细节。对于固定尺寸基础类型(小尺寸类型),它们的值默认是可复制的,这主要是为了编程方便。对于非固定尺寸类型或大尺寸类型的变量再赋值时,默认使用移动操作。除非显式地clone,否则它只保持一份所有权。
所有权可以被转移,一旦所有权被转移,原来持有该资源的变量就失效了。变量的作用域是在最近的花括号位置内。
思考题
最后我来考一考你。
- 下面的示例将输出什么?
fn main() { let s = "I am a superman.".to_string(); for i in 1..10 { let tmp_s = s; println!("s is {}", tmp_s); } }
- 一个由固定尺寸类型组成的结构体变量,如下面示例中的Point类型,在赋值给另一个变量时,采用的是移动方式还是复制方式?
struct Point {
x: i64,
y: i64,
z: i64
}
欢迎你把你思考后的答案分享到评论区,和我一起讨论,也欢迎你把这节课分享给需要的朋友,邀他一起学习,我们下节课再见!
所有权(下):Rust中借用与引用的规则是怎样的?
你好,我是Mike。今天我们继续探讨Rust中所有权这一关键设计。
上节课我们了解了计算机内存结构知识,理解了Rust在内存资源管理上特立独行的设计——所有权,也知道了Rust准备采用所有权来重构整个软件体系。那么这节课我们继续学习所有权的相关内容——借用与引用,学完这节课我们就会对Rust语言的所有权方案有一个相对完整的认知了。
这节课我会用一些精心设计的示例,让你体会Rust引用的独特之处。
借用与引用
我们来复习一下上一节课最后一个例子。我们想在函数 foo 执行后继续使用字符串s1,我们通过把字符串的所有权转移出来,来达到我们的目的。
fn foo(s: String) -> String { println!("{s}"); s } fn main() { let s1 = String::from("I am a superman."); let s1 = foo(s1); println!("{s1}"); }
这样可以是可以,不过很麻烦。一是会给程序员造成一些心智负担,还得想着把值传回来再继续使用。如果代码中到处都是所有权传来传去,会让代码显得相当冗余,毕竟很多时候函数返回值是要用作其他类型的返回的。为了解决这个问题,Rust引入了借用的概念。
借用概念也是实际生活中思维的映射。比如你有一样东西,别人想用一下,可以从你这里借,你可以借出。那“引用”概念又是什么呢?其实在Rust中, 借用和引用是一体两面。你把东西借给别人用,也就是别人持有了对你这个东西的引用。这里你理解就好,后面我们会混用这两个词。
在Rust中,变量前用“&”符号来表示引用,比如 &x。
其实 引用也是一种值,并且是固定尺寸的值,一般来说,与机器CPU位数一致,比如64位或32位。因为是值,所以就可以赋给另一个变量。同时它又是固定的而且是小尺寸的值,那其实赋值的时候,就可以直接复制一份这个引用。
让我们来看一下如何使用引用。
fn main() { let a = 10u32; let b = &a; // b是变量a的一级引用 let c = &&&&&a; // c是变量a的多级引用 let d = &b; // d是变量a的间接引用 let e = b; // 引用b再赋值给e println!("{a}"); println!("{b}"); println!("{c}"); println!("{d}"); println!("{e}"); } // 输出 10 10 10 10 10
从上面示例中可以看出,Rust识别了我们一般情况下的意图,不会打印出引用的内存地址什么的,而是打印出了被引用对象的值。示例中的c实际是a的5次引用,但是打印时仍然正确获取到了a的值。d是a的间接引用,但是仍然正确获取到了a的值。这里我们可以看出Rust与C这种纯底层语言的显著区别,Rust对程序员更友好,它会更多地面向业务。因为人们还是普遍关注最终那个值的部分,而不是中间过程的内存地址。
上面示例中,b和e都是对a的一级引用。由于引用是固定尺寸的值, let e = b 做的就是引用的复制操作,并没有再复制一份a的值。
那对字符串来说会怎样呢?我们改一下上面的示例。
fn main() { let s1 = String::from("I am a superman."); let s2 = &s1; let s3 = &&&&&s1; let s4 = &s2; let s5 = s2; println!("{s1}"); println!("{s2}"); println!("{s3}"); println!("{s4}"); println!("{s5}"); } // 输出 I am a superman. I am a superman. I am a superman. I am a superman. I am a superman.
结果符合我们的期望。同样,这些引用都没有导致堆中的字符串资源被复制一份或多份。字符串的所有权仍然在s1那里,s2、s3、s4、s5都是对这个所有权变量的引用。从这里开始,我们可以将变量按一个新的维度划分为 所有权型变量 和 引用型变量。
也可以看出,在Rust中,一个所有权型变量(如 s1)带有值和类型的信息,一个引用型变量(如 s2、s3、s4、s5)也带有值和类型的信息,不然它没法正确回溯到最终的值。这些信息是Rust编译器帮我们维护的。
不可变引用、可变引用
上一节课,我们看到Rust的变量具有可变性。那么同样的规则,是不是可以施加到引用上来呢?当然可以。这正是Rust语言设计一致性的体现。
实际上默认 &x 指的是不可变引用。而要获取到可变引用,需要使用 &mut 符号,如 &mut x。
好家伙,我们一下子又引入了两个新概念:不可变引用和可变引用。让我们好好来消化一下它们。
- 引用分成不可变引用和可变引用。
&x是对变量x的不可变引用。&mut x是对变量x的可变引用。
你应该发现了,这里mut和x中间有个空格,为什么呢?很简单,就是为了避免和 &mutx 混淆。
不可变引用和可变引用对应的现实概念也是很容易理解的。比如,你把你的书借给别人,并且嘱咐,只能阅读,不能在书上记笔记。这就相当于不可变引用。如果你允许他在书上面写写划划,那就相当于可变引用。
为什么会有可变引用的存在呢?这个事情是这样的。到目前为止,如果要对一个变量内容进行修改,我们必须拥有所有权型变量才行。而很多时候,我们没法拥有那个资源的所有权,比如你引用一个别人的库,它没有把所有权类型暴露出来,但是确实又有更新其内部状态的需求。因此需要一个东西,它既是一种引用,又能够修改指向资源的内容。于是就引入了 可变引用。
我们前面举的引用的例子,实际只是访问(打印)变量的值,没有修改它们,所以没问题。现在我们再来看一下,如果要使用引用修改变量的值,应该怎么做。
fn main() { let a = 10u32; let b = &mut a; *b = 20; println!("{b}"); }
提示:
error[E0596]: cannot borrow `a` as mutable, as it is not declared as mutable
--> src/main.rs:19:13
|
19 | let b = &mut a;
| ^^^^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
18 | let mut a = 10u32;
| +++
报错了。怎么回事呢?
前面我们说过,要修改一个变量的值,变量名前要加 mut 修饰符,我们忘加了(不要害羞,这是很正常的事情),Rust编译器给我们指出来了。
现在我们加上。
fn main() { let mut a = 10u32; let b = &mut a; *b = 20; println!("{b}"); } // 输出 20
接下来改动一下例子。
fn main() { let mut a = 10u32; let b = &mut a; *b = 20; println!("{b}"); println!("{a}"); // 这里多打印了一行a } // 输出 20 20
正确输出了修改后的值。
我们再换一下两个打印语句的位置试试。
fn main() { let mut a = 10u32; let b = &mut a; *b = 20; println!("{a}"); // 这一句移到前面来 println!("{b}"); }
编译居然报错了!
Compiling playground v0.0.1 (/playground)
error[E0502]: cannot borrow `a` as immutable because it is also borrowed as mutable
--> src/main.rs:6:15
|
3 | let b = &mut a;
| ------ mutable borrow occurs here
...
6 | println!("{a}"); // 这一句移到的前面来
| ^^^ immutable borrow occurs here
// 提示说这里发生了不可变借用
7 | println!("{b}");
| --- mutable borrow later used here
// 在这后面使用了可变借用
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
只是移动了一下打印语句,就会导致程序编译不通过。什么道理!我能充分理解你初学Rust的心情。
那这到底是为什么呢?我们先总结一下观察到的事情。
- 打印语句
println!中,不管是传所有权型变量还是引用型变量,都能打印出预期的值。实际上println!中默认会对所有权变量做不可变借用操作(对应代码里的第6行)。 - 可变引用调用的时机(对应代码里的第7行)和不可变引用调用的时机(对应代码里的第6行),好像有顺序要求。目前我们尚不清楚这种机制是什么。
为了让问题暴露得更加明显,我又设计了另外一个例子。
fn main() { let mut a = 10u32; let b = &mut a; *b = 20; let c = &a; // 在利用b更新了a的值后,c再次借用a }
这个代码是可以顺利编译的。但是加了一句打印就又不行了!
fn main() { let mut a = 10u32; let b = &mut a; *b = 20; let c = &a; // 在利用b更新了a的值后,c再次借用a println!("{b}"); // 加了一句打印语句 }
提示:
Compiling playground v0.0.1 (/playground)
error[E0502]: cannot borrow `a` as immutable because it is also borrowed as mutable
// 不能将a借用为不可变的,因为它已经被可变借用了
--> src/main.rs:5:13
|
3 | let b = &mut a;
| ------ mutable borrow occurs here
// 可变借用发生在这里
4 | *b = 20;
5 | let c = &a;
| ^^ immutable borrow occurs here
// 不可变借用发生在这里
6 |
7 | println!("{b}"); // 加了一句打印语句
| --- mutable borrow later used here
// 可变借用在这里使用了
怎么回事呢?
我们试着改一下打印语句。
fn main() { let mut a = 10u32; let b = &mut a; *b = 20; let c = &a; println!("{c}"); // 不打印b了,换成打印c } // 输出 20
这下编译通过了,打印出 20。
我们尝试一下把变量c的定义移到前面一些,结果又不能编译了。
fn main() { let mut a = 10u32; let c = &a; // c的定义移到这里来了 let b = &mut a; *b = 20; println!("{c}"); }
提示:
Compiling playground v0.0.1 (/playground)
error[E0502]: cannot borrow `a` as mutable because it is also borrowed as immutable
--> src/main.rs:4:13
|
3 | let c = &a; // c的定义移到这里来了
| -- immutable borrow occurs here
4 | let b = &mut a;
| ^^^^^^ mutable borrow occurs here
...
7 | println!("{c}");
| --- immutable borrow later used here
你有没有感觉Rust就像一头发疯的野牛!不听使唤。而我们现在要做的就是摸清它的脾气,驯服它!
再尝试修改代码,又编译通过了。
fn main() { let mut a = 10u32; let c = &a; // c的定义移到这里来了 let b = &mut a; *b = 20; println!("{b}"); // 这里打印的变量换成b }
到这里为止,我们已经积累了不少素材了,从这些素材中你有没有发现什么规律? 引用的最后一次调用时机很关键。
前面我们讲过,一个所有权型变量的作用域是从它定义时开始到花括号结束。而引用型变量的作用域不是这样, 引用型变量的作用域是从它定义起到它最后一次使用时结束。 比如上面的示例中,所有权型变量a的作用域是2~8行;不可变引用c的作用域只有第3行,它定义了,但并没有被使用,所以它的作用域就只有那一行;可变引用b的作用域是4~7行。
同时,我们发现还存在一条规则: 一个所有权型变量的可变引用与不可变引用的作用域不能交叠,也可以说不能同时存在。我们用这条规则分析前面的示例。
fn main() { let mut a = 10u32; let c = &a; let b = &mut a; *b = 20; println!("{c}"); }
所有权型变量a的作用域是2~8行,不可变引用c的作用域是3~7行,可变引用b的作用域是4~5行。b和c的作用域交叠了,因此无法编译通过。
后面你可以采用我的这种分析方法来分析每一个例子。
接下来我们再看一个例子。
fn main() { let mut a = 10u32; let b = &mut a; *b = 20; let d = &mut a; println!("{d}"); // 打印d } // 输出 20
这个例子打印出 20。那我们尝试打印b试试。
fn main() { let mut a = 10u32; let b = &mut a; *b = 20; let d = &mut a; println!("{b}"); // 打印b }
编译不通过,提示:
Compiling playground v0.0.1 (/playground)
error[E0499]: cannot borrow `a` as mutable more than once at a time
// 在一个时刻不能把`a`以可变借用形式借用超过一次
--> src/main.rs:5:13
|
3 | let b = &mut a;
| ------ first mutable borrow occurs here
4 | *b = 20;
5 | let d = &mut a;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{b}");
| --- first borrow later used here
编译器抱怨:“在一个时刻不能把a以可变借用形式借用超过一次”。分析代码后,我们发现确实这两个可变借用的作用域交叠了!b的作用域是3~7行,d的作用域是第5行,难怪会报错。于是我们又学到了一条经验: 同一个所有权型变量的可变借用之间的作用域也不能交叠。
然后,让我们继续看。
fn main() { let mut a = 10u32; let r1 = &a; a = 20; println!("{r1}"); }
编译报错:
Compiling playground v0.0.1 (/playground)
error[E0506]: cannot assign to `a` because it is borrowed
// 不能给a赋值,因为它被借用了
--> src/main.rs:4:5
|
3 | let r1 = &a;
| -- `a` is borrowed here
4 | a = 20;
| ^^^^^^ `a` is assigned to here but it was already borrowed
5 |
6 | println!("{r1}");
| ---- borrow later used here
提示在有借用的情况下,不能对所有权变量进行更改值的操作(写操作)。
有可变借用存在的情况下也一样。
fn main() { let mut a = 10u32; let r1 = &mut a; a = 20; println!("{r1}"); }
编译报错:
Compiling playground v0.0.1 (/playground)
error[E0506]: cannot assign to `a` because it is borrowed
--> src/main.rs:4:5
|
3 | let r1 = &mut a;
| ------ `a` is borrowed here
4 | a = 20;
| ^^^^^^ `a` is assigned to here but it was already borrowed
5 |
6 | println!("{r1}");
| ---- borrow later used here
提示在有借用的情况下,不能对所有权变量进行更改值的操作(写操作)。
通过前面这么多例子的摸索,你是不是找到了一些规律?到此为止,我们可以做一下阶段性的总结,得出关于引用(借用)的一些规则。
- 所有权型变量的作用域是从它定义时开始到所属那层花括号结束。
- 引用型变量的作用域是从它定义起到它最后一次使用时结束。
- 引用(不可变引用和可变引用)型变量的作用域不会长于所有权变量的作用域。这是肯定的,不然就会出现悬锤引用,这是典型的内存安全问题。
- 一个所有权型变量的不可变引用可以同时存在多个,可以复制多份。
- 一个所有权型变量的可变引用与不可变引用的作用域不能交叠,也可以说不能同时存在。
- 某个时刻对某个所有权型变量只能存在一个可变引用,不能有超过一个可变借用同时存在,也可以说,对同一个所有权型变量的可变借用之间的作用域不能交叠。
- 在有借用存在的情况下,不能通过原所有权型变量对值进行更新。当借用完成后(借用的作用域结束后),物归原主,又可以使用所有权型变量对值做更新操作了。
下面我们再来试试可变引用能否被复制。
fn main() { let mut a = 10u32; let r1 = &mut a; let r2 = r1; println!("{r1}") }
出错了,提示:
error[E0382]: borrow of moved value: `r1`
--> src/main.rs:6:16
|
3 | let r1 = &mut a;
| -- move occurs because `r1` has type `&mut u32`, which does not implement the `Copy` trait
4 | let r2 = r1;
| -- value moved here
5 |
6 | println!("{r1}")
| ^^ value borrowed here after move
它说r1的值移动给了r2,因此r1不能再被使用了。
我们修改一下例子。
fn main() { let mut a = 10u32; let r1 = &mut a; let r2 = r1; println!("{r2}"); // 打印r2 } // 输出 10
成功打印。
从这个例子可以看出,可变引用的再赋值,会执行移动操作。赋值后,原来的那个可变引用变量就不能用了。这有点类似于所有权的转移,因此 一个所有权型变量的可变引用也具有所有权特征,它可以被理解为那个所有权变量的独家代理,具有 排它性。
多级引用
我们来看剩下的一些语言细节。下面这段代码展示了 mut 修饰符, &mut 和 & 同时出现的情况。
fn main() { let mut a1 = 10u32; let mut a2 = 15u32; let mut b = &mut a1; b = &mut a2; let mut c = &a1; c = &a2; }
下面我们再来看一个多级可变引用的例子。
fn main() { let mut a1 = 10u32; let mut b = &mut a1; *b = 20; let c = &mut b; **c = 30; // 多级解引用操作 println!("{c}"); } // 输出 30
假如我们解引用错误会怎样,来看看。
fn main() { let mut a1 = 10u32; let mut b = &mut a1; *b = 20; let c = &mut b; *c = 30; // 这里对二级可变引用只使用一级解引用操作 println!("{c}"); }
哦!会报错。
Compiling playground v0.0.1 (/playground)
error[E0308]: mismatched types
--> src/main.rs:7:10
|
7 | *c = 30;
| -- ^^ expected `&mut u32`, found integer
| |
| expected due to the type of this binding
|
help: consider dereferencing here to assign to the mutably borrowed value
|
7 | **c = 30;
| +
它正确识别到了中间引用的类型为 &mut u32,而我们却要给它赋值为 u32,一定是代码写错了,然后还给我们建议了正确的写法。强大!
我们再来看一个例子。
fn main() { let mut a1 = 10u32; let b = &mut a1; let mut c = &b; let d = &mut c; ***d = 30; println!("{d}"); }
提示:
error[E0594]: cannot assign to `***d`, which is behind a `&` reference
--> src/main.rs:21:5
|
21 | ***d = 30;
| ^^^^^^^^^ cannot assign
For more information about this error, try `rustc --explain E0594`.
提示:不能这样更新目标的值,因为目标躲在一个 & 引用后面。
这里,我们又可以发现Rust中三条关于引用的知识点。
- 对于多级可变引用,要利用可变引用去修改目标资源的值的时候,需要做正确的多级解引用操作,比如例子中的
**c,做了两级解引用。 - 只有全是多级可变引用的情况下,才能修改到目标资源的值。
- 对于多级引用(包含可变和不可变),打印语句中,可以自动为我们解引用正确的层数,直到访问到目标资源的值,这很符合人的直觉和业务的需求。
用引用改进函数的定义
有了引用这个设施,我们可以改进前面将字符串所有权传进函数,然后又传出来的例子。第一个例子是将字符串的不可变引用传进函数参数。
fn foo(s: &String) { println!("in fn foo: {s}"); } fn main() { let s1 = String::from("I am a superman."); foo(&s1); // 注意这里传的是字符串的引用 &s1 println!("{s1}"); // 这里可以打印s1的值了 }
可以看到,打印出了正确的结果。
in fn foo: I am a superman.
I am a superman.
然后我们试试将字符串的可变引用传进函数,并修改字符串的内容。
fn foo(s: &mut String) { s.push_str(" You are batman."); } fn main() { let mut s1 = String::from("I am a superman."); println!("{s1}"); foo(&mut s1); // 注意这里传的是字符串的可变引用 &mut s1 println!("{s1}"); }
输出:
I am a superman.
I am a superman. You are batman.
与我们的期望一致。我们成功地使用引用,来改进函数的传参过程以及函数的定义,我们这里的 foo 函数,不再需要费力地把所有权再传回来了。
从代码中可以看到,这里Rust的代码 &s1 和 &mut s1 留下了清晰的足迹。如果一个函数参数接受的是可变引用或所有权参数,那么它里面的逻辑一般都会对其引用的资源进行修改。如果一个函数参数只接受不可变引用,那么它里面的逻辑,就一定不会修改被引用的资源。简单的一个参数的签名形式,就将函数的意图初步划分出来了。就是这么清晰,非常利于代码的阅读。
小结
这节课我带着你摸了一遍Rust这头野牛的怪脾气,现在已经大致清楚了。下面我们一起来总结一下这节课的主要内容。
在同一时刻,同一个所有权变量的不可变引用和可变引用两者不能同时存在,不可变引用可以同时存在多个。可变引用具有排它性,只能同时存在一个。
借用结束后,原本的所有权变量会重新恢复可读可写的状态。不可变引用可以被任意复制多份,但是可变引用不能被复制,只能转移,这也体现了 可变引用具有一定的所有权特征。所有权和引用模型是Rust语言编写高可靠和高性能代码的基础,理解这些模型有助于优化程序的效率,提高代码质量。
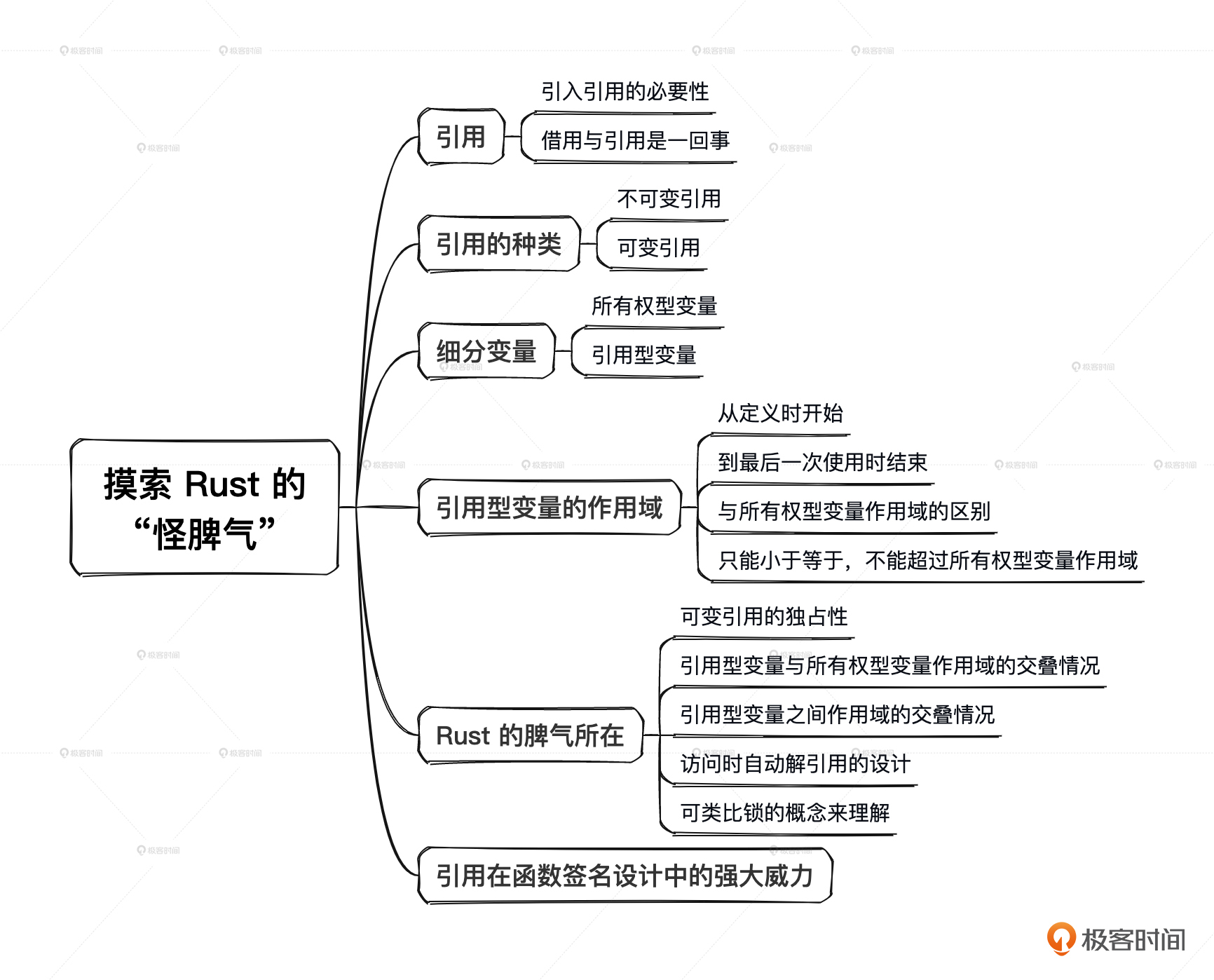
本文通过探索性的方式尝试遍历不可变引用与可变引用的各种形式和可能的组合,由此揭开了Rust中引用的各种性质以及同所有权的关系,并总结出了多条相关规则。看起来略显繁琐,但每个示例其实非常简单,理解起来并不困难。请一定记住, 不要死记硬背那些条条框框,请你亲自敲上面的代码示例,编译并运行它,在实践中去理解它们。久而久之,就会形成一种思维习惯,觉得Rust中的这种设计是理所当然的了。
思考题
- 请思考,为何在不可变引用存在的情况下(只是读操作),原所有权变量也无法写入?
fn main() { let mut a: u32 = 10; let b = &a; a = 20; println!("{}", b); }
- 请回答,可变引用复制的时候,为什么不允许copy,而是move?
欢迎你把你思考后的答案分享到评论区,和我一起讨论,也欢迎你把这节课分享给需要的朋友,邀他一起学习,我们下节课再见!
字符串:对号入座,字符串其实没那么可怕!
你好,我是Mike,今天我们来认识一下Rust中和我们打交道最频繁的朋友——字符串。
这节课我们把字符串单独拿出来讲,是因为字符串太常见了,甚至有些应用的主要工作就是处理字符串。比如 Web开发、解析器等。而Rust里的字符串内容相比于其他语言来说还要多一些。是否熟练掌握Rust的字符串的使用,对Rust代码开发效率有很大影响,所以这节课我们就来重点攻克它。
可怕的字符串?
我们在Rust里常常会见到一些字符串相关的内容,比如下面这些。
String, &String,
str, &str, &'static str
[u8], &[u8], &[u8; N], Vec<u8>
as_str(), as_bytes()
OsStr, OsString
Path, PathBuf
CStr, CString
我们用一张图形象地表达Rust语言里字符串的复杂性。
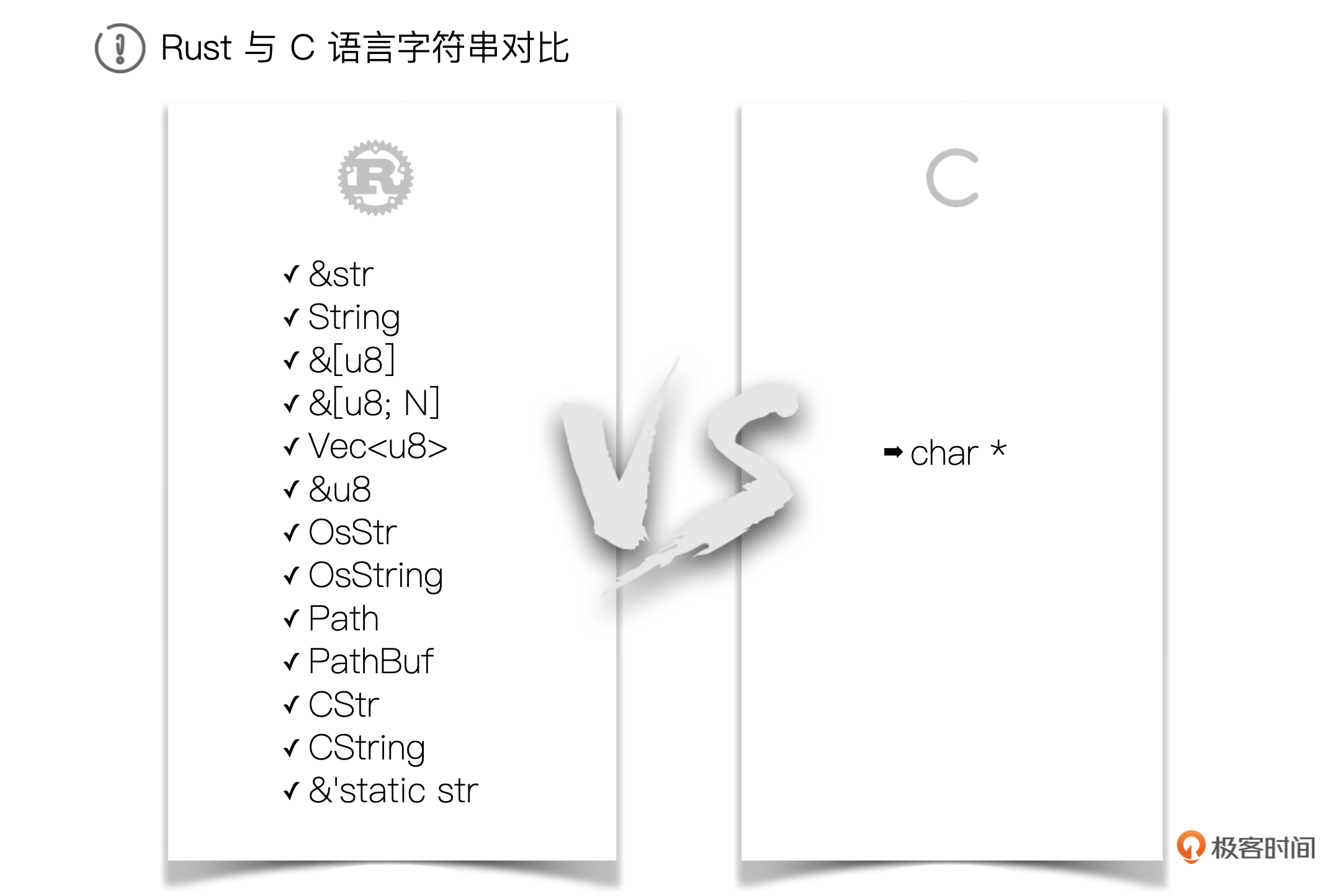
有没有被吓到?顿时不想学了,Rust从入门到放弃,第一次Rust旅程到此结束。
且慢且慢,先不要盖棺定论。仔细想一想Rust中的字符串真的有这么复杂吗?这些眼花缭乱的符号到底是什么?我来给你好好分析一下。
首先,我们来看C语言里的字符串。图里显示,C中的字符串统一叫做 char *,这确实很简洁,相当于是统一的抽象。但是这个统一的抽象也付出了代价,就是 丢失了很多额外的信息。
为什么会这样呢?我们从计算机结构说起。我们都知道,计算机CPU执行的指令都是二进制序列,所有语言写的程序最后执行时都会归结为二进制序列来执行。但是为什么不直接写二进制打孔开发,而是出现了几百上千种计算机语言呢?没错,就是因为 抽象。
抽象是用来解决现实问题建模的工具。在Rust里也一样,之所以Rust有那么多看上去都是字符串的类型,就是因为 Rust把字符串在各种场景下的使用给模型化、抽象化了。相比C语言的 char *,多了建模的过程,在这个模型里面多了很多额外的信息。
下面我们就来看看前面提到的那些字符串类型各自有什么具体含义。
不同类型的字符串
示例:
fn main() { let s1: &'static str = "I am a superman."; let s2: String = s1.to_string(); let s3: &String = &s2; let s4: &str = &s2[..]; let s5: &str = &s2[..6]; }
上述示例中,s1、s2、s3、s4、s5 看起来好像是4种不同类型的字符串表示。为了让你更容易理解,我画出它们在内存中的结构图。
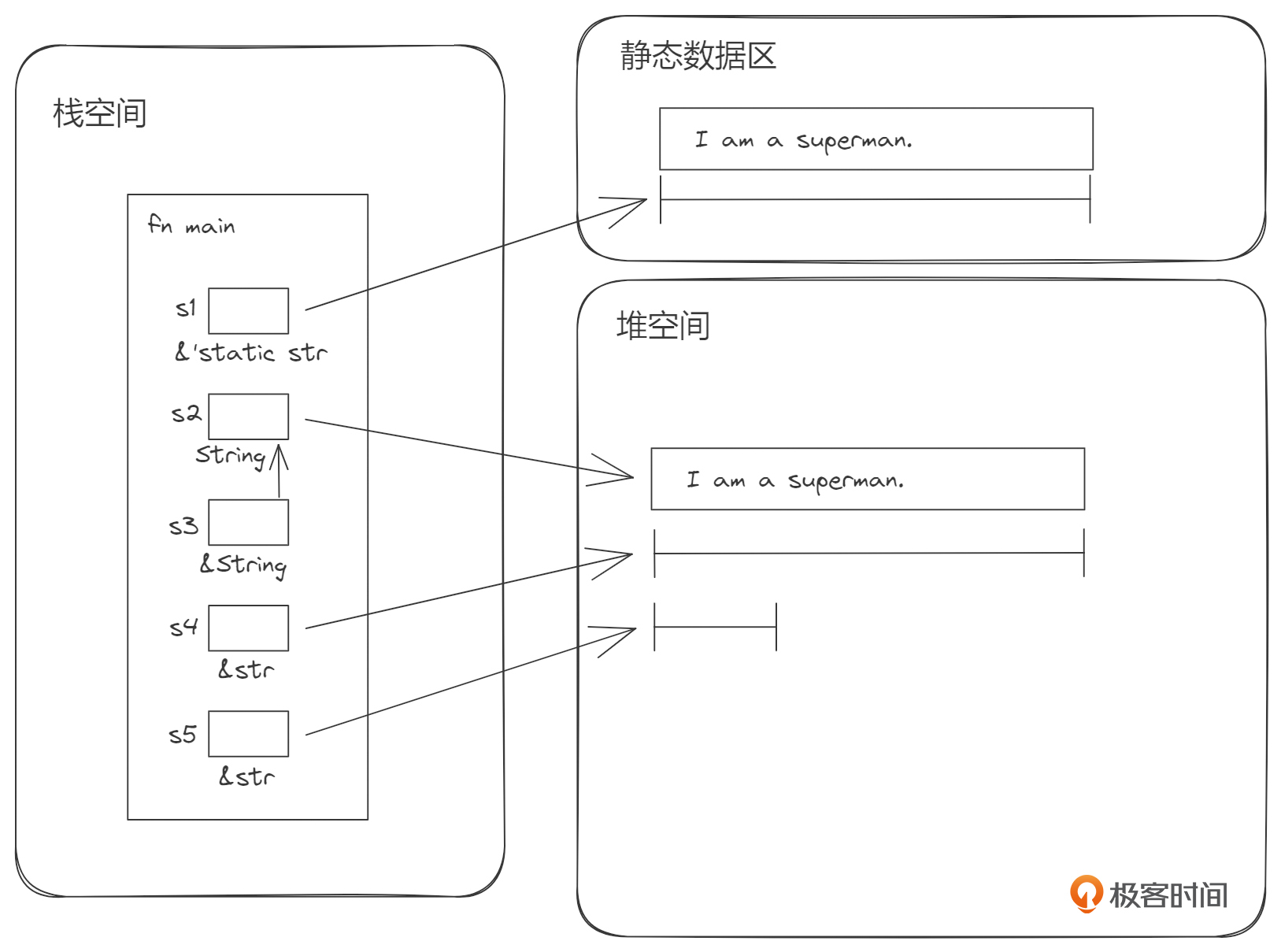
我来详细解释一下这张图片的意思。
"I am a superman." 这个用双引号括起来的部分是字符串的字面量,存放在静态数据区。而 s1 是指向静态数据区中的这个字符串的切片引用,形式是 &'static str,这是静态数据区中的字符串的表示方法。
通过执行 s1.to_string(),Rust将静态数据区中的字符串字面量拷贝了一份到堆内存中,通过s2指向,s2具有这个堆内存字符串的所有权, String 在Rust中就代表具有所有权的字符串。
s3就是对s2的不可变引用,因此类型为 &String。
s4是对s2的切片引用,类型是 &str。切片就是一块连续内存的某种视图,它可以提取目标对象的全部或一部分。这里s4就是取的目标对象字符串的全部。
s5是对s2的另一个切片引用,类型也是 &str。与s4不同的是,s5是s2的部分视图。具体来说,就是 "I am a" 这一部分。
相信你通过上面的例子对这几种不同类型的字符串已经有了一个简单直观的认识了,下面我来给你详细解释下。
String 是字符串的所有权形式,常常在堆中分配。 String 字符串的内容大小是可以动态变化的。而 str 是字符串的切片类型,通常以切片引用 &str 形式出现,是字符串的视图的借用形式。
字符串字面量默认会存放在静态数据区里,而静态数据区中的字符串总是贯穿程序运行的整个生命期,直到程序结束的时候才会被释放。因此不需要某一个变量对其拥有所有权,也没有哪个变量能够拥有这个字符串的所有权(也就是这个资源的分配责任)。因此对于字符串字面量这种数据类型,我们只能拿到它的借用形式 &'static str。这里 'static 表示这个引用可以贯穿整个程序的生命期,直到这个程序运行结束。
&String 仅仅是对 String 类型的字符串的普通引用。
对 String 做字符串切片操作后,可以得到 &str。这里这个 &str 就是指向由 String 管理的内存资源的切片引用,是目标字符串资源的借用形式,不会再把字符串内容复制一份。
从上面的图示里可以看到, &str 既可以引用堆中的字符串,也可以引用静态数据区中的字符串( &'static str 是 &str 的一种特殊形式)。其实内存本来就是一个线性空间,一个指针(引用是指针的一种)理论上来说可以指向这个线性空间中的任何地址。
&str 也可转换为 String。你可以通过示例,看一下它们之间是如何转换的。
let s: String = "I am a superman.".to_string();
let a_slice: &str = &s[..];
let another_String: String = a_slice.to_string();
切片
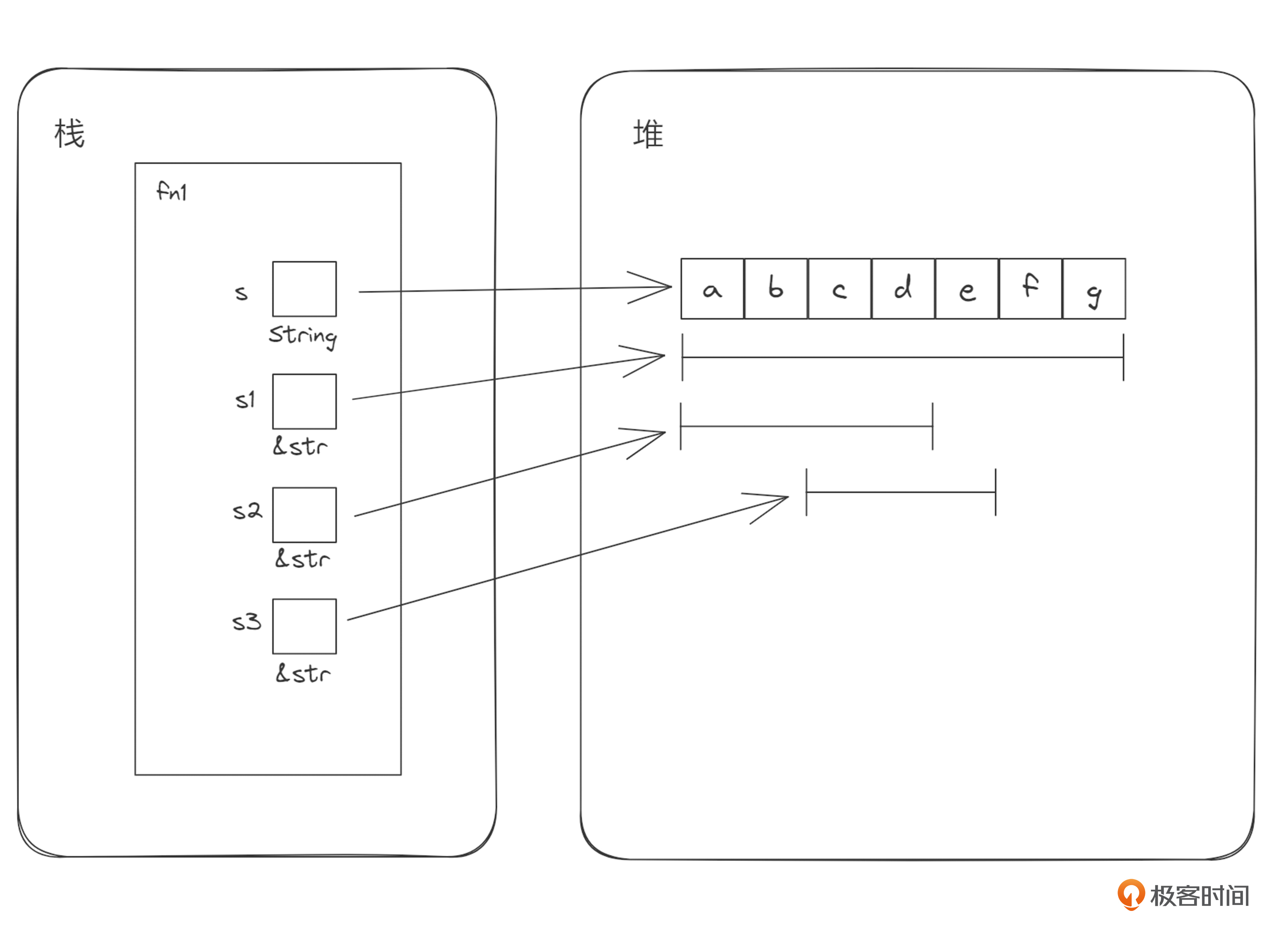
上面提到了切片,这里我再补充一点关于切片(slice)的背景知识。切片是一段连续内存的一个视图(view),在Rust中由 [T] 表示,T为元素类型。这个视图可以是这块连续内存的全部或一部分。切片一般通过切片的引用来访问,你可以看一下我给出的这个字符串示例。
let s = String::from("abcdefg");
let s1 = &s[..]; // s1 内容是 "abcdefg"
let s2 = &s[0..4]; // s2 内容是 "abcd"
let s3 = &s[2..5]; // s3 内容是 "cde"
上面示例中,s是堆内存中所有权型字符串类型。s1作为s的一个切片引用,它也指向堆内存中那个字符串的头部,表示s的完整内容。s2与s1指向的堆内存地址是相同的,但是内容不同,s2是 "abcd",而s1是 "abcdefg"。s3则是s的中间位置的一段切片引用,内容是 "cde"。s3指向的地址与s、s1、s2 不同。我画了一张图来表示它们之间的关系。
如果你拿到的是一个字符串切片引用,那么如何转换成所有权型字符串呢?有几种方法。
let s: &str = "I am a superman.";
let s1: String = String::from(s); // 使用 String 的from构造器
let s2: String = s.to_string(); // 使用 to_string() 方法
let s3: String = s.to_owned(); // 使用 to_owned() 方法
[u8]、 &[u8]、 &[u8; N]、 Vec<u8>
这一块儿内容虽然不是直接与字符串相关,但具有类比性。有了前面的背景知识,我们可以轻松辨析这几种类型。
[u8]是字节串切片,大小是可以动态变化的。&[u8]是对字节串切片的引用,即切片引用,与&str是类似的。&[u8; N]是对u8数组(其长度为N)的引用。Vec<u8>是u8类型的动态数组。与String类似,这是一种具有所有权的类型。
Vec<u8> 与 &[u8] 的关系如下:
let a_vec: Vec<u8> = vec![1,2,3,4,5,6,7,8];
// a_slice 是 [1,2,3,4,5]
let a_slice: &[u8] = &a_vec[0..5];
// 用 .to_vec() 方法将切片转换成Vec
let another_vec = a_slice.to_vec();
// 或者用 .to_owned() 方法
let another_vec = a_slice.to_owned();
我们可以整理出一个对比表格。
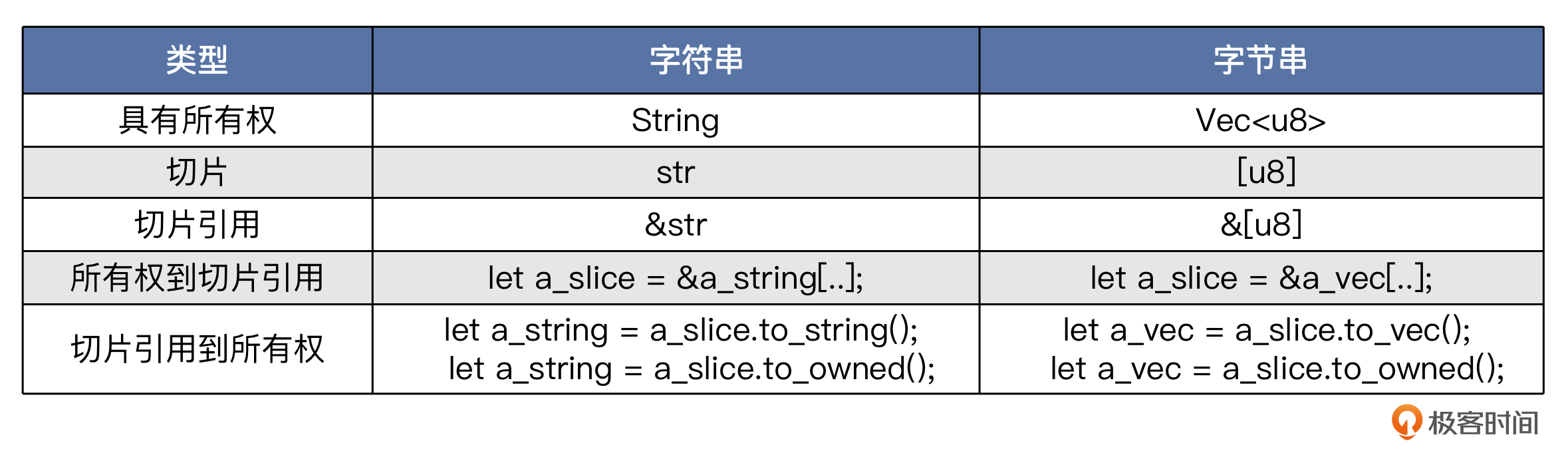
as_str()、 as_bytes()、 as_slice()
String 类型上有个方法是 as_str()。它返回 &str 类型。这个方法效果其实等价于 &a_string[..],也就是包含完整的字符串内容的切片。
let s = String::from("foo");
assert_eq!("foo", s.as_str());
String 类型上还有个方法是 as_bytes(),它返回 &[u8] 类型。
let s = String::from("hello");
assert_eq!(&[104, 101, 108, 108, 111], s.as_bytes());
通过上面两个示例可以对比这两个方法的不同之处。 可以猜想 &str 其实也是可以转成 &[u8] 的,我们查询 标准库文档 发现,用的正是同名方法。
let bytes = "bors".as_bytes();
assert_eq!(b"bors", bytes);
Vec上有个 as_slice() 函数,与 String 上的 as_str() 对应,把完整内容转换成切片引用 &[T],等价于 &a_vec[..]。
let a_vec = vec![1, 2, 3, 5, 8];
assert_eq!(&[1, 2, 3, 5, 8], a_vec.as_slice());
隐式引用类型转换
前面我们看到,Rust中 &String 与 &str 其实是不同的。这种细节的区分,在某些情况下,会造成一些不方便,而且这些情况还比较常见。比如:
fn foo(s: &String) { } fn main() { let s = String::from("I am a superman."); foo(&s); let s1 = "I am a superman."; foo(s1); }
上面示例中,函数的参数类型我们定义成 &String。那么在函数调用时,这个函数只接受 &String 类型的参数传入。如果我们定义一个字符串字面量变量,想传进 foo 函数中,就发现不行。
error[E0308]: mismatched types
--> src/main.rs:8:7
|
8 | foo(s1); // error on this line
| --- ^^ expected `&String`, found `&str`
| |
| arguments to this function are incorrect
|
= note: expected reference `&String`
found reference `&str`
这里体现了Rust严格的一面。
但是很明显,这种严格也导致了平时使用不方便,它强迫我们必须注意字符串处理时的各种细节问题,有时显得过于迂腐了。但是Rust也并不是那么死板,它在保持严格性的同时,通过一些精妙的机制,也可以实现一定程度上的灵活性。我们可以更改上述示例来体会一下。
fn foo(s: &str) { // 只需要把这里的参数改为 &str 类型 } fn main() { let s = String::from("I am a superman."); foo(&s); let s1 = "I am a superman."; foo(s1); }
把 foo 参数的类型由 &String 改为 &str,上述示例就编译通过了。为什么呢?
实际上,在Rust中对 String 做引用操作时,可以告诉Rust编译器,我想把 &String 直接转换到 &str 类型。只需要在代码中明确指定目标类型就可以了。
let s = String::from("I am a superman.");
let s1 = &s;
let s2: &str = &s;
上述代码,s1不指定具体类型,对所有权字符串s的引用操作,只转换成 &String 类型。而如果指定了目标类型为&str,那么对所有权字符串s的引用操作,就进一步转换成了 &str 类型。
于是在上面的 foo() 函数中,我们只定义一种参数,就可以接收两种入参类型: &String 和 &str。这让函数的调用更符合直觉,使用更方便了。
具体是怎么做到的呢?需要用到后面的知识点:Deref。你可以查阅 链接,学习 Deref 相关知识,在这里我们暂时先跳过,不做过多展开。
同样的原理,不仅可以作用在 String 上,也可以作用在 Vec<u8> 上 ,更进一步的话,还可以作用在 Vec<T> 上。我们可以总结出一张表格。

下面的示例表示同一个函数可以接受 &Vec<u32> 和 &[u32] 两种类型的传入。
fn foo(s: &[u32]) { } fn main() { let v: Vec<u32> = vec![1,2,3,4,5]; foo(&v); let a_slice = v.as_slice(); foo(a_slice); }
字节串转换成字符串
前面我们看到可以通过 as_bytes() 方法将字符串转换成 &[u8]。相反的操作也是有的,就是把 &[u8] 转换成字符串。
前面我们讲过,Rust中的字符串实际是一个UTF-8序列,因此转换的过程也是与UTF-8编码相关的。哪些函数可用于转换呢?
- String::from_utf8() 可以把
Vec<u8>转换成String,转换不一定成功,因为一个字节序列不一定是有效的UTF-8编码序列。它返回的是Result(关于Result,我们后面会专题讲解,这里仅做了解),需要自行做错误处理。 - String::from_utf8_unchecked() 可以把
Vec<u8>转换成String。不检查字节序列是不是无效的UTF-8编码,直接返回String类型。但是这个函数是unsafe的,一般不推荐使用。 - str::from_utf8() 可以将
&[u8]转换成&str。它返回的是Result,需要自行做错误处理。 - str::from_utf8_unchecked()可以把
&[u8]转换成&str。它直接返回&str类型。但是这个函数是unsafe的,一般不推荐使用。
注意 from_utf8 系列函数,返回的是Result。有时候会让人觉得很繁琐,但是 这种繁琐实际是客观复杂性的体现,Rust的严谨性要求对这种转换不成功的情况做严肃的自定义处理。 反观其他语言,对于这种转换不成功的情况往往用一种内置的策略做处理,而无法自定义。
字符串切割成字符数组
&str 类型有个 chars() 函数,可以用来把字符串转换为一个迭代器,迭代器是一种通用的抽象,就是用来按顺序安全迭代的,我们后面也会讲到这个概念。通过这个迭代器,就可以取出 char。你可以先了解它的用法。
fn main() { let s = String::from("中国你好"); let char_vec: Vec<char> = s.chars().collect(); println!("{:?}", char_vec); for ch in s.chars() { println!("{:?}", ch); } }
输出:
['中', '国', '你', '好']
'中'
'国'
'你'
'好'
其他字符串相关类型
有了前面的知识背景。我们现在来看这些与字符串相关的类型: Path、 PathBuf、 OsStr、 OsString、 CStr、 CString。
前面我们讲过其实它们只是具体场景下的字符串而已。相对于普通的 String 或 &str,它们只是 包含了更多的特定场景的信息。比如 Path 类型,它就要处理跨平台的目录分隔符(Unix下是/,Windows下是\),以及一些其他信息。而 PathBuf 与 Path 的区别就对应于 String 与 str 的区别。
OsStr 的存在是因为各个操作系统平台上的原生字符串定义其实是不同的。比如Unix系统,原生字符串是任意非0字节序列,不过常常解释为UTF-8编码;而在Windows上,原生字符串定义为任意非0字节16位序列,正常情况下解释为UTF-16编码序列。而Rust自带的标准 str 定义和它们都不同,它是一个可以包含0这个字节的严格UTF-8编码序列。在开发平台相关的应用时,往往需要处理这种类型转换的细节,于是就有了 OsStr 类型。而 OsString 与 OsStr 的关系对应于 String 与 str 的关系。
CStr 是C语言风格的字符串,字符串以0这个字节作结束符,在字符串中不能包含0。因为Rust要无缝集成C的能力。所以这些类型出现在Rust中就很合理了。而 CString 与 CStr 的关系就对应于 String 与 str 的关系。
这些平台细节的处理相当繁琐和专业,Rust把已处理好这些细节的类型提供给我们,我们直接使用就好了。理解了这一点,你是否还觉得C语言中唯一的 char * 是更好的设计吗?
这些字符串类型你不一定要在现阶段全部掌握,这里你只需要理解Rust中为什么存在这些类型,还有这些类型之间的关系就可以了。后面我们在用到具体某个类型的时候再深入研究,那个时候相信你会掌握得更快、更透彻。
Parse方法
str 有一个 parse() 方法 非常强大,可以从字符串转换到任意Rust类型,只要这个类型实现了 FromStr 这个Trait(Trait是Rust中一个极其重要的概念,后面我们会讲述)即可。把字符串解析成Rust类型,肯定有不成功的可能,所以这个方法返回的是一个Result,需要自行处理解析错误的情况。下面的代码示例展示了字符串如何转换到各种类型,我们先了解,知道形式是怎样的就可以了。
fn main() { let a = "10".parse::<u32>(); let aa: u32 = "10".parse().unwrap(); // 这种写法也很常见 println!("{:?}", a); let a = "10".parse::<f32>(); println!("{:?}", a); let a = "4.2".parse::<f32>(); println!("{:?}", a); let a = "true".parse::<bool>(); println!("{:?}", a); let a = "a".parse::<char>(); println!("{:?}", a); let a = "192.168.1.100".parse::<std::net::IpAddr>(); println!("{:?}", a); }
你可以看看哪些标准库类型已实现了 FromStr trait。
parse() 函数就相当于Rust语言内置的统一的解析器接口,如果你自己实现的类型需要与字符串互相转换,就可以考虑实现这个接口,这样的话就比较能被整个Rust社区接受,这就是所谓的Rust地道风格的体现。
而对于更复杂和更通用的与字符串转换的场景,我们可能会更倾向于序列化和反序列化的方案。这块在Rust生态中也有标准的方案—— serde,它作为序列化框架,可以支持各种数据格式协议,功能非常强大、统一。我们目前仅做了解。
小结
学习完这节课的内容,你有没有觉得Rust语言中的字符串内容确实很丰富?相比于C语言中的字符串,Rust把字符串按场景划分成了不同的类型,每种类型都包含有不同的额外信息。通过将研究目标(字符串)按场景类型化,在代码中加入了更多的信息,给Rust编译器这个AI助手喂了更多的料,从而可以让编译器为我们做更多的校验和推导的事情,来确保我们程序的正确性,并尽可能做性能优化。
这节课我们提到了一些新的概念,比如迭代器、Trait等,你不需要现在就掌握,先知道有这么个东西就可以了,这节课你的主要任务有三个。
- 熟悉Rust语言中的字符串的各种类型形式,以及它们之间的区别。
- 知道Rust语言中字符串相关类型的基本转换方式有哪些。
- 体会地道的Rust代码风格以及对称性。
字符串在Rust代码中使用广泛,几乎会贯穿整个课程。请你一定多加练习,牢牢掌握字符串相关类型在不同场景下的转换以及一些常用的方法。
思考题
chars 函数是定义在 str 上的,为什么 String 类型能直接调用 str 上定义的方法?实际上 str 上的所有方法, String 都能调用,请问这是为什么呢?
欢迎你把思考后的结果分享到评论区,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!
复合类型(上):结构体与面向对象特性
你好,我是 Mike。今天我们来学习 Rust 中的复合类型——结构体。
结构体是由其他的基础类型或复合类型组成的,当它所有字段同时实例化后,就生成了这个结构体的实例。在 Rust 中,结构体使用 struct 关键字进行定义。
这节课我们会通过各种各样的示例来了解结构体,其中有部分示例来自于官方 The Book。我们一起来看一下。
结构体示例
下面我们先来看一下结构体示例,定义一个 User 结构体。
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
示例中的 User 结构体由 4 个字段组成。
- active 字段:bool 类型,表示这个用户是否是激活状态。
- username 字段:字符串类型,表示这个用户的名字。
- email 字段:字符串类型,表示这个用户的邮箱名。
- sign_in_count 字段:u64 类型,用来记录这个用户登录了多少次。
User 完全由 4 个基础类型的字段组合而成。User 的实例化需要这 4 个字段同时起作用,缺一不可。比如:
fn main() { let user1 = User { active: true, username: String::from("someusername123"), email: String::from("someone@example.com"), sign_in_count: 1, }; }
结构体类型也可以参与更复杂结构体的构建。
struct Class {
serial_number: u32,
grade_number: u32,
entry_year: String,
members: Vec<User>,
}
代码里的 Class 表示班级,serial_number 表示几班,grade_number 表示几年级,entry_year 表示起始年份,members 是一个 User 的动态数组。
从这里,我们已经可以想象出,结构体类型可以不断往上一层一层地套。而在实际应用中, 结构体往往是一个程序的骨干,用来承载对目标问题进行建模和描述的重任。
结构体的形式
结构体有三种形式,分别是命名结构体、元组结构体和单元结构体,下面我们一个一个看。
命名结构体
命名结构体是指每个字段都有名字的结构体,比如前面提到的 User 结构体,它的每个字段都有明确的名字和类型。
如果在实例化结构体之前,命名了结构体字段名的同名变量,那么用下面这种写法可以偷懒少写几个字符。
fn main() { let active = true; let username = String::from("someusername123"); let email = String::from("someone@example.com"); let user1 = User { active, // 这里本来应该是 active: active, username, // 这里本来应该是 username: username, email, // 这里本来应该是 email: email, sign_in_count: 1, }; }
这样会显得代码更简洁,同时也没有歧义。
结构体创建好之后,可以更新结构体的部分字段。下面的示例里就单独更新了 email 字段。
fn main() { let mut user1 = User { active: true, username: String::from("someusername123"), email: String::from("someone@example.com"), sign_in_count: 1, }; user1.email = String::from("anotheremail@example.com"); }
注意 user1 前面的 mut 修饰符,不加的话就没办法修改这个结构体里的字段。
而如果我们已经有了一个 User 的实例 user1,想再创建一个新的 user2,而两个实例之间只有部分字段不同。这时,Rust 也提供了偷懒的办法,比如:
fn main() { let active = true; let username = String::from("someusername123"); let email = String::from("someone@example.com"); let user1 = User { active, username, email, sign_in_count: 1, }; let user2 = User { email: String::from("another@example.com"), ..user1 // 注意这里,直接用 ..user1 }; }
用这种写法可以帮助我们少写很多重复代码。特别是当这个结构体比较大的时候,比如有几十个字段,而我们只想更新其中的一两个字段的时候,就显得特别有用了,这能够让我们的代码保持干净清爽。
比如有一个场景就正好符合这个语法特性。用户的信息存在数据库里,当我们要更新一个用户的一个字段的信息时,首先需要从数据库里把这个用户的信息取出来,做一些基本的校验,然后把要更新的字段替换成新的内容,再把这个新的用户实例存回数据库。
这个过程可以这样写:
// 这个示例是伪代码
let user_id = get_id_from_request;
let new_user_name = get_name_from_request();
let old_user: User = get_from_db(user_id);
let new_user: User = User {
username: new_user_name,
..old_user // 注意这里的写法
}
new_user.save()
有了这些语法糖,用 Rust 写业务代码是非常清爽的。
元组结构体
除了前面那种最普通的命名结构体形式,Rust 中也支持一种匿名结构体的形式,也叫做元组结构体。所谓元组结构体,也就是 元组和结构体的结合体。
元组结构体长什么样子呢?你可以看一下示例。
struct Color(i32, i32, i32); struct Point(i32, i32, i32); fn main() { let black = Color(0, 0, 0); let origin = Point(0, 0, 0); }
可以看到,元组结构体有类型名,但是无字段名,也就是说字段是匿名的。在有些情况下这很有用,因为想名字是一件很头痛的事情。并且某些场景下用元组结构体表达会更有效。比如对于 RGB 颜色对、三维坐标这种各分量之间有对称性,又总是一起出现的情景,直接用元组结构体表达会显得更紧凑。
上述示例中,我们看到,Color 类型和 Point 类型的元组部分其实是一样的,都是 (i32, i32, i32),但是由于类型名不同,它们就是不同的类型,因此上面的 black 实例和 origin 实例就是两个完全不同的东西,前者表示黑色,后者表示原点。
单元结构体
Rust 还支持单元结构体。单元结构体就是只有一个类型名字,没有任何字段的结构体。单元结构体在定义和创建实例的时候,连后面的花括号都可以省略。比如:
struct ArticleModule; fn main() { let module = ArticleModule; // 请注意这一句,也做了实例化操作 }
可以看到,这个示例中结构体 ArticleModule 类型实际创建了一个实例,ArticleModule 的定义和实例化都没有使用花括号。这种写法非常紧凑,所以要注意分辨,不然会疑惑:类型为什么能直接赋给一个变量。
那没有字段的结构体有什么用呢?其实它就相当于定义了一种类型,它的名字就是一种信息,有类型名就可以进行实例化,承载很多东西。后面我们在代码中会经常看到单元结构体。
结构体中的所有权问题
部分移动
Rust 的结构体有一种与所有权相关的特性,叫做部分移动(Partial Move)。就是说结构体中的部分字段是可以被移出去的,我们来看下示例。
#[derive(Debug)] struct User { active: bool, username: String, email: String, sign_in_count: u32, } fn main() { let active = true; let username = String::from("someusername123"); let email = String::from("someone@example.com"); let user1 = User { active, username, email, sign_in_count: 1, }; let email = user1.email; // 在这里发生了partially moved println!("{:?}", user1) // 这一句无法通过编译 }
提示:
error[E0382]: borrow of partially moved value: `user1`
--> src/main.rs:22:22
|
20 | let email = user1.email;
| ----------- value partially moved here
21 |
22 | println!("{:?}", user1)
| ^^^^^ value borrowed here after partial move
下面这句对于我们习惯的编程的人来说,其实是非常普通的一行,就是将结构体的一个字段值赋值给一个新的变量。
let email = user1.email;
但这里就发生了一件很奇妙的事情,因为 email 字段是 String 类型,是一种所有权类型,于是 email 字段的值被移动了。移动后,email 变量拥有了那个值的所有权。而 user1 中的 email 字段就被标记无法访问了。
我们稍微改一下这段代码,不直接打印 user1 实例整体,而是分别打印 email 之外的另外三个字段。
let email = user1.email;
println!("{}", user1.username); // 分别打印另外3个字段
println!("{}", user1.active);
println!("{}", user1.sign_in_count);
这时可以得到正确的输出。而如果单独打印 email 字段,也是不行的,你可以自己试试。这就是结构体中所有权字段被部分移动的情景。
字段是引用类型
还是用前面我们定义的 User 类型,它里面的所有字段都是带所有权的字段。而在赋值行为上,bool 和 u32 会默认复制一份新的所有权,而 String 会移动之前那份所有权到新的变量。全部定义带所有权的字段,是我们定义结构体类型的主要方式。
但是既然都是类型,Rust 的结构体没有理由不能支持借用类型。比如:
struct User {
active: &bool, // 这里换成了 &bool
username: &str, // 这里换成了 &str
email: &str, // 这里换成了 &str
sign_in_count: &u32, // 这里换成了 &u32
}
我们把 4 个字段都换成了对应的引用形式。
这种写法当然是可以的,不过上面的代码暂时还没办法通过 Rust 的编译,我们需要加一些额外的标注才能让其通过,这个我们在这里不展开讲解,后面第 20 讲我会针对这个问题展开描述。我这里把这种写法提出来是为了让你意识到,几乎所有的地方,Rust 都会把问题一分为二,一是所有权形式的表示,二是借用形式的表示。借用形式的表示又可进一步细分为不可变借用的表示和可变借用的表示。
一般来说,对于业务系统我们用的几乎都是所有权形式的结构体,而这就已经够用了。对于初学者来说,切忌贪图所有语言特性,应该以实用为主。
给结构体添加标注
在 Rust 中,我们可以给类型添加标注。
#[derive(Debug)] // 这里,在结构体上面添加了一种标注
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u32,
}
这样标注后,就可以在打印语句的时候把整个结构体打印出来了。
println!("{:?}", user1); // 注意这里的 :? 符号
这种 #[derive(Debug)] 语法在 Rust 中叫 属性标注,具体来说这里用的是 派生宏属性, 派生宏作用在下面紧接着的结构体类型上,可以为结构体自动添加一些功能。这些知识我们后面会讲解。目前为止你只需要知道它起什么作用就可以了。比如,派生 Debug 这个宏可以让我们在 println! 中用 {:?} 格式把结构体打印出来,这对于调试是非常方便的。
如果你学过 Java,可能会非常眼熟,这跟 Java 中的标注语法非常像,功能也是类似的,都会对原代码的元素产生作用。不过,Rust 这个特性作为一套完整的宏机制,要强大得多。它让 Rust 的语言表达能力又上了一个台阶。
后面我们会经常看到各种派生宏,到时候我们再做讲解。
面向对象特性
Rust 不是一门面向对象的语言,但是它确实有部分面向对象的特性。 而 Rust 承载面向对象特性的主要类型就是结构体。Rust 有个关键字 impl 可以用来给结构体或其他类型实现方法,也就是关联在某个类型上的函数。
方法(实例方法)
使用 impl 关键字为结构体实现方法,可以像下面这样:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { // 就像这样去实现 fn area(self) -> u32 { // area就是方法,被放在impl实现体中 self.width * self.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!( "The area of the rectangle is {} square pixels.", rect1.area() // 使用点号操作符调用area方法 ); } // 输出 The area of the rectangle is 1500 square pixels.
上面示例中,我们给 Rectangle 类型实现了 area 方法,并在 Rectangle 的实例 rect1 上使用点号(.)操作符调用了这个方法。
Self
请注意看 area 方法的签名。
fn area(self) -> u32
你会发现,这个参数好像有点特殊,是一个单 self,不太像标准的参数定义语法。
实际上这里是 Rust 的一个语法糖,self 的完整写法是 self: Self,而 Self 是 Rust 里一个特殊的类型名,它表示正在被实现(impl)的那个类型。
前面我们说过,Rust 中所有权形式和借用形式总是成对出现,在 impl 的时候也是如此。方法的签名中也会对应三种参数形式。我们扩展一下上面的例子。
impl Rectangle {
fn area1(self) -> u32 {
self.width * self.height
}
fn area2(&self) -> u32 {
self.width * self.height
}
fn area3(&mut self) -> u32 {
self.width * self.height
}
}
3 种形式都是可以的。
方法是实现在类型上的特殊函数,它的第一个参数是 Self 类型,包含 3 种形式。
- self: Self:传入实例的所有权。
- self: &Self:传入实例的不可变引用。
- self: &mut Self:传入实例的可变引用。
因为是标准用法,所以 Rust 帮我们简写成了 self、&self、&mut self。这种简写并不会产生歧义。
上述代码展开后是这样的:
impl Rectangle {
fn area1(self: Self) -> u32 {
self.width * self.height
}
fn area2(self: &Self) -> u32 {
self.width * self.height
}
fn area3(self: &mut Self) -> u32 {
self.width * self.height
}
}
方法调用的时候,直接在实例上使用 . 操作符调用,然后第一个参数是实例自身,会默认传进去,因此不需要单独写出来。
rect1.area1(); // 传入rect1
rect1.area2(); // 传入&rect1
rect1.area3(); // 传入&mut rect1
看到这里,你是不是感觉很熟悉,有没有 C++、Java 等方法的 this 指针的既视感?不过,在 Rust 中,基本上一切都是显式化的,不存在隐藏提供一个参数给你的情况。这样就会少很多坑,如果你是 JavaScript 开发者,在这一点上应该深有体会。
实例的引用也是可以直接调用方法的。比如,对于不可变引用,可以像下面这样调用。Rust 会自动做正确的多级解引用操作。
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; // 在这里,取了实例的引用 let r1 = &rect1; let r2 = &&rect1; let r3 = &&&&&&&&&&&&&&&&&&&&&&rect1; // 不管有多少层 let r4 = &&r1; // 以下4行都能打印出正确的结果 r1.area(); r2.area(); r3.area(); r4.area(); }
对同一个类型,impl 可以分开写多次。这在组织代码的时候比较方便。
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
关联函数(静态方法)
前面我们讲过,方法的第一个参数为 self,从函数参数定义上来说,第一个参数当然也可以不是 self。如果实现在类型上的函数,它的第一个参数不是 self 参数,那么它就叫做此类型的关联函数。
impl Rectangle {
fn numbers(rows: u32, cols: u32) -> u32 {
rows * cols
}
}
调用时,关联函数使用类型配合路径符 :: 来调用。注意这里与实例用点运算符调用方法的区别。
Rectangle::numbers(10, 10);
你有没有感觉,Rust 中的关联函数跟 C++、Java 里的静态方法起着类似的作用?确实差不多。但是 Rust 这里不需要额外引入一个 static 修饰符去定义,因为靠是否有 Self 参数就已经能明确地区分实例方法与关联函数了。
构造函数
不像 C++、Java 等语言,Rust 中没有专门的构造函数,但是用于构造实例的需求是不会变的。那 Rust 中一般是怎么处理的呢?
首先,Rust 中结构体可以直接实例化,比如前面定义的 Rectangle。
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; }
基于这一点,Rust 社区一般约定使用 new() 这个名字的关联函数,像下面这样把类型的实例化包起来。
impl Rectangle {
pub fn new(width: u32, height: u32) -> Self {
Rectangle {
width,
height,
}
}
}
然后,使用下面这行代码创建新实例。
let rect1 = Rectangle::new(30, 50);
但是 new 这个名字并不是强制的。所以你在社区的很多库里还会看到 from()、 from_xxx() 等其他名字起构造函数的功能。Rust 在这块儿并没有强制要求,多熟悉社区中的惯用法,能写出更地道的 Rust 代码。
Default
在对结构体做实例化的时候,Rust 又给我们提供了一个便利的设施,Default。
我们可以像下面这样使用:
#[derive(Debug, Default)] // 这里加了一个Default派生宏 struct Rectangle { width: u32, height: u32, } fn main() { let rect1: Rectangle = Default::default(); // 使用方式1 let rect2 = Rectangle::default(); // 使用方式2 println!("{:?}", rect1); println!("{:?}", rect2); } // 打印出如下: Rectangle { width: 0, height: 0 } Rectangle { width: 0, height: 0 }
Default 有两种使用方式,一种是直接用 Default::default(),第二种是用类型名 ::default(),它们的实例化效果是一样的。
可以看到,打出来的实例字段值都 0,是因为 u32 类型默认值就是 0。对于通用类型,比如 u32 这种类型来说,取 0 是最适合的值了,想一想取其他值是不是没办法被大多数人接受?
但是,对于我们特定场景的 Rectangle 这种,我们可能希望给它赋一个初始的非 0 值。在 Rust 中,这可以做到,但是需要用到后面的知识。目前我们就可以先用约定的 new 关联函数+参数来达到我们的目的。
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { pub fn new(width: u32, height: u32) -> Self { Rectangle { width, height, } } } const INITWIDTH: u32 = 50; const INITHEIGHT: u32 = 30; fn main() { // 创建默认初始化值的Rectangle实例 let rect1 = Rectangle::new(INITWIDTH , INITHEIGHT); }
小结
这节课我们详细讨论了 Rust 中结构体相关的知识,现在来复习一下。
结构体中有命名结构体、元组结构体、单元结构体几种表现形式,除此之外,结构体中的所有权问题也是需要重点关注的,尤其是部分移动的概念。然后我们介绍了如何通过在结构体上添加标注来增强结构体的能力。
我们还进一步了解了如何利用 impl 关键字为结构体实现面向对象特性。不过需要注意的是, Rust 语言本身并不是一门完整的面向对象语言,比如它缺乏继承等机制。但是这并不重要,OOP 不是编程语言的全部,Rust 语言从设计之初就没有走向 OOP 的方向。后面我们会看到,Rust 利用 trait 等机制,能够提供比 OOP 语言更解耦的抽象、更灵活的配置。
结构体是用户自定义类型的主要实现者,你要熟练掌握。除了具体的语法知识点之外,我建议你用所有权和借用的思路去贯穿 Rust 整个知识体系。
思考题
可以给 i8 类型做 impl 吗?
欢迎你把思考后的结果分享到评论区,也欢迎你把这节课分享给需要的朋友,我们下节课再见!
复合类型(下):枚举与模式匹配
你好,我是Mike。今天我们一起来学习Rust中的枚举(enum)和模式匹配(pattern matching)。
枚举是Rust中非常重要的复合类型,也是最强大的复合类型之一,广泛用于属性配置、错误处理、分支流程、类型聚合等场景中。学习完这节课后,你会对Rust的地道风格有新的认识。
枚举:强大的复合类型
枚举是这样一种类型,它容纳选项的可能性,每一种可能的选项都是一个变体(variant)。Rust中的枚举使用关键字 enum 定义,这点与Java、C++都是一样的。与它们不同的是,Rust中的枚举具有更强大的表达能力。
在Rust中,枚举中的所有条目被叫做这个枚举的变体。比如:
enum Shape {
Rectangle,
Triangle,
Circle,
}
定义了一个形状(Shape)枚举,它有三个变体:长方形Rectangle、三角形Triangle和圆形Circle。
枚举与结构体不同, 结构体的实例化需要所有字段一起起作用,而枚举的实例化只需要且只能是其中一个变体起作用。
负载
Rust中枚举的强大之处在于,enum中的变体可以挂载各种形式的类型。所有其他类型,比如字符串、元组、结构体等等,都可以作为enum的负载(payload)被挂载到其中一个变体上。比如,扩展一下上面的代码示例。
enum Shape {
Rectangle { width: u32, height: u32},
Triangle((u32, u32), (u32, u32), (u32, u32)),
Circle { origin: (u32, u32), radius: u32 },
}
我们给Shape枚举的三个变体都挂载了不同的负载。Rectangle挂载了一个结构体负载表示宽和高的属性。
{width: u32, height: u32}
为了看得更清楚,你也可以单独定义一个结构体,然后把它挂载到Rectangle变体上。
struct Rectangle {
width: u32,
height: u32
}
enum Shape {
Rectangle(Rectangle),
// ...
}
Triangle变体挂载了一个元组负载 ((u32, u32), (u32, u32), (u32, u32)),表示三个顶点。
Circle变体挂载了一个结构体负载 { origin: (u32, u32), radius: u32 },表示一个原点加半径长度。
枚举的变体能够挂载各种类型的负载,是Rust中的枚举超强能力的来源,你可以通过上面例子来细细品味Rust的这种表达力。enum就像一个筐,什么都能往里面装。
为了让你更熟悉Rust的枚举表达形式,我再举一个例子。下面的示例中WebEvent表示浏览器里面的Web事件。
enum WebEvent {
PageLoad,
PageUnload,
KeyPress(char),
Paste(String),
Click { x: i64, y: i64 },
}
你可以表述出不同变体的意义,还有每个变体所挂载的负载类型吗?期待看到你的答案。
枚举的实例化
枚举的实例化实际是枚举变体的实例化。比如:
let a = WebEvent::PageLoad;
let b = WebEvent::PageUnload;
let c = WebEvent::KeyPress('c');
let d = WebEvent::Paste(String::from("batman"));
let e = WebEvent::Click { x: 320, y: 240 };
可以看到,不带负载的变体实例化和带负载的变体实例化不一样。带负载的变体实例化要根据不同变体附带的类型做特定的实例化。
类C枚举
Rust中也可以定义类似C语言中的枚举。
示例:
// 给枚举变体一个起始数字值 enum Number { Zero = 0, One, Two, } // 给枚举每个变体赋予不同的值 enum Color { Red = 0xff0000, Green = 0x00ff00, Blue = 0x0000ff, } fn main() { // 使用 as 进行类型的转化 println!("zero is {}", Number::Zero as i32); println!("one is {}", Number::One as i32); println!("roses are #{:06x}", Color::Red as i32); println!("violets are #{:06x}", Color::Blue as i32); } // 输出 zero is 0 one is 1 roses are #ff0000 violets are #0000ff
可以看到,我们能够像C语言那样,在定义枚举变体的时候,指定具体的值。这在底层系统级开发、协议栈开发、嵌入式开发的场景会经常用到。
打印的时候,只需要使用 as 操作符将变体转换为具体的数值类型即可。
代码中的 println! 里的 {:06x} 是格式化参数,这里表示打印出值的16进制形式,占位6个宽度,不足的用0补齐。你可以顺便了解一下 println 打印语句中 格式化参数 的详细内容。格式化参数相当丰富,我们可以在以后不断地实践中去熟悉和掌握它。
空枚举
Rust中也可以定义空枚举。比如 enum MyEnum {};。它其实与单元结构体一样,都表示一个类型。但是它不能被实例化。目前看起来好像没什么作用,我们只需要了解这种表示形式就可以了。
enum Foo {}
let a = Foo {}; // 错误的
// 提示
expected struct, variant or union type, found enum `Foo`
not a struct, variant or union type
impl 枚举
Rust有个关键字 impl 可以用来给结构体或其他类型实现方法,也就是关联在某个类型上的函数。——第5讲
枚举同样能够被 impl。比如:
enum MyEnum { Add, Subtract, } impl MyEnum { fn run(&self, x: i32, y: i32) -> i32 { match self { // match 语句 Self::Add => x + y, Self::Subtract => x - y, } } } fn main() { // 实例化枚举 let add = MyEnum::Add; // 实例化后执行枚举的方法 add.run(100, 200); }
但是不能对枚举的变体直接 impl。
enum Foo {
AAA,
BBB,
CCC
}
impl Foo::AAA { // 错误的
}
一般情况下,枚举会用来做配置,并结合 match 语句使用来做分支管理。 如果要定义一个新类型,在Rust中主要还是使用结构体。
match
接下来我们开始学习和枚举搭配使用的match语句。
match + 枚举
其实在上面的示例中,就已经出现 match 关键字了。它的作用是判断或匹配值是哪一个枚举的变体。下面我们看一个例子。
#[derive(Debug)] enum Shape { Rectangle, Triangle, Circle, } fn main() { let shape_a = Shape::Rectangle; // 创建实例 match shape_a { // 匹配实例 Shape::Rectangle => { println!("{:?}", Shape::Rectangle); // 进了这个分支 } Shape::Triangle => { println!("{:?}", Shape::Triangle); } Shape::Circle => { println!("{:?}", Shape::Circle); } } } // 输出 Rectangle
你可以试着改变实例为另外两种变体,看看打印出的信息有没有变化,然后判断上面的代码走了哪个分支。
match可返回值
就像大多数Rust语法一样,match 语法也是可以有返回值的,所以也叫做match表达式,我们来看一下示例。
#[derive(Debug)] enum Shape { Rectangle, Triangle, Circle, } fn main() { let shape_a = Shape::Rectangle; // 创建实例 let ret = match shape_a { // 匹配实例,并返回结果给ret Shape::Rectangle => { 1 } Shape::Triangle => { 2 } Shape::Circle => { 3 } }; println!("{}", ret); } // 输出 1
因为 shape_a 被赋值为 Shape::Rectangle,所以程序匹配到第一个分支并返回 1,变量ret的值为 1。
let ret = match shape_a {
这种写法就是比较地道的Rust写法,可以让代码显得更紧凑。
注意, match表达式中各个分支返回的值的类型必须相同。
所有分支都必须处理
match表达式里所有的分支都必须处理,不然Rustc小助手会拦住你,不让你通过。这是怎么回事呢?你可以看一下示例代码。
#[derive(Debug)] enum Shape { Rectangle, Triangle, Circle, } fn main() { let shape_a = Shape::Rectangle; // 创建实例 let ret = match shape_a { // 匹配实例 Shape::Rectangle => { 1 } Shape::Triangle => { 2 } // Shape::Circle => { // 3 // } }; println!("{}", ret); }
上面这段代码在编译的时候会出错。
error[E0004]: non-exhaustive patterns: `Shape::Circle` not covered
--> src/main.rs:10:19
|
10 | let ret = match shape_a { // 匹配实例
| ^^^^^^^ pattern `Shape::Circle` not covered
|
note: `Shape` defined here
--> src/main.rs:5:3
|
2 | enum Shape {
| -----
...
5 | Circle,
| ^^^^^^ not covered
= note: the matched value is of type `Shape`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
16 ~ },
17 + Shape::Circle => todo!()
|
小助手提示说, Shape::Circle 分支没有覆盖到,不允许通过,然后直接贴心地给出了修改建议!Rustc小助手如此贴心,这种保姆级服务是你在Java、C++等其他语言中感受不到的。
_ 占位符
有时,你确实想测试一些东西,或者就是不想处理一些分支,可以用 _ 偷懒。
比如上面代码可以修改成这样:
#[derive(Debug)] enum Shape { Rectangle, Triangle, Circle, } fn main() { let shape_a = Shape::Rectangle; let ret = match shape_a { Shape::Rectangle => { 1 } _ => { 10 } }; println!("{}", ret); }
相当于除 Shape::Rectangle 之外的分支我们都统一用 _ 占位符进行处理了。
更广泛的分支
match除了配合枚举进行分支管理外,还可以与其他基础类型结合进行分支分派。我们可以看一个 The Book里的示例。
fn main() { let number = 13; // 你可以试着修改上面的数字值,看看下面走哪个分支 println!("Tell me about {}", number); match number { // 匹配单个数字 1 => println!("One!"), // 匹配几个数字 2 | 3 | 5 | 7 | 11 => println!("This is a prime"), // 匹配一个范围,左闭右闭区间 13..=19 => println!("A teen"), // 处理剩下的情况 _ => println!("Ain't special"), } }
可以看到,match可以用来匹配一个具体的数字、一个数字的列表,或者一个数字的区间等等,非常灵活。在这点上,可比C、C++,或者Java 的 switch .. case 灵活多了。
模式匹配
match实际是模式匹配的入口,从match表达式我们可引出模式匹配的概念。模式匹配就是 按对象值的结构 进行匹配,并且可以取出符合模式的值。下面我们通过一些示例来解释这句话。
模式匹配不限于在 match 中使用。除了match外,Rust还给模式匹配提供了其他一些语法层面的设施。
if let
当要匹配的分支只有两个或者在这个位置只想先处理一个分支的时候,可以直接用 if let。
比如下面这段代码就可以使用 if let。
let shape_a = Shape::Rectangle;
match shape_a {
Shape::Rectangle => {
println!("1");
}
_ => {
println!("10");
}
};
改写为:
let shape_a = Shape::Rectangle;
if let Shape::Rectangle = shape_a {
println!("1");
} else {
println!("10");
}
是不是相比于match,使用 if let 的代码量有所简化?
while let
while 后面也可以跟 let,实现模式匹配。比如:
#[derive(Debug)] enum Shape { Rectangle, Triangle, Circle, } fn main() { let mut shape_a = Shape::Rectangle; let mut i = 0; while let Shape::Rectangle = shape_a { // 注意这一句 if i > 9 { println!("Greater than 9, quit!"); shape_a = Shape::Circle; } else { println!("`i` is `{:?}`. Try again.", i); i += 1; } } } // 输出 `i` is `0`. Try again. `i` is `1`. Try again. `i` is `2`. Try again. `i` is `3`. Try again. `i` is `4`. Try again. `i` is `5`. Try again. `i` is `6`. Try again. `i` is `7`. Try again. `i` is `8`. Try again. `i` is `9`. Try again. Greater than 9, quit!
上面示例构造了一个while循环,手动维护计数器 i,递增到9之后,退出循环。
看起来,在条件判断语句那里用 while Shape::Rectangle == shape_a 也行,好像用 while let 的意义不大。我们来试一下,编译之后,报错了。
error[E0369]: binary operation `==` cannot be applied to type `Shape`
说 == 号不能作用在类型 Shape 上,你可以思考一下为什么。
如果一个枚举变体带负载,使用模式匹配可以把这个负载取出来,这点就比较方便了,下面我们使用带负载的枚举来举例。
let
let本身就支持模式匹配。其实前面的 if let、while let 本身使用的就是 let 模式匹配的能力。
#[derive(Debug)] enum Shape { Rectangle {width: u32, height: u32}, Triangle, Circle, } fn main() { // 创建实例 let shape_a = Shape::Rectangle {width: 10, height: 20}; // 模式匹配出负载内容 let Shape::Rectangle {width, height} = shape_a else { panic!("Can't extract rectangle."); }; println!("width: {}, height: {}", width, height); } // 输出 width: 10, height: 20
在这个示例中,我们利用模式匹配解开了shape_a 中带的负载(结构体负载),同时定义了 width 和 height 两个局部变量,并初始化为枚举变体的实例负载的值。这两个局部变量在后续的代码块中可以使用。
注意第12行代码。
let Shape::Rectangle {width, height} = shape_a else {
这种语法是匹配结构体负载,获取字段值的方式。
匹配元组
元组也可以被匹配,比如下面这个例子。
fn main() { let a = (1,2,'a'); let (b,c,d) = a; println!("{:?}", a); println!("{}", b); println!("{}", c); println!("{}", d); }
这种用法叫做元组的析构,常用来从函数的多个返回值里取出数据。
fn foo() -> (u32, u32, char) { (1,2,'a') } fn main() { let (b,c,d) = foo(); println!("{}", b); println!("{}", c); println!("{}", d); }
匹配枚举
前面已经讲过如何使用 let 把枚举里变体的负载解出来,这里我们再来看一个例子。
struct Rectangle { width: u32, height: u32 } enum Shape { Rectangle(Rectangle), Triangle((u32, u32), (u32, u32), (u32, u32)), Circle { origin: (u32, u32), radius: u32 }, } fn main() { let a_rec = Rectangle { width: 10, height: 20, }; // 请打开下面这一行进行实验 //let shape_a = Shape::Rectangle(a_rec); // 请打开下面这一行进行实验 //let shape_a = Shape::Triangle((0, 1), (3,4), (3, 0)); let shape_a = Shape::Circle { origin: (0, 0), radius: 5 }; // 这里演示了在模式匹配中将枚举的负载解出来的各种形式 match shape_a { Shape::Rectangle(a_rec) => { // 解出一个结构体 println!("Rectangle {}, {}", a_rec.width, a_rec.height); } Shape::Triangle(x, y, z) => { // 解出一个元组 println!("Triangle {:?}, {:?}, {:?}", x, y, z); } Shape::Circle {origin, radius} => { // 解出一个结构体的字段 println!("Circle {:?}, {:?}", origin, radius); } } } // 输出 Circle (0, 0), 5
这个示例展示了如何将变体中的结构体整体、元组各部分、结构体各字段解析出来的方式。
用这种方式,我们可以在做分支处理的时候,顺便处理携带的信息,让代码变得相当紧凑而有意义(高内聚)。你需要熟悉并掌握这些写法,这样写起Rust代码来才会更加顺手。
匹配结构体
下面我们再看一个例子,了解结构体字段匹配过程中的一个细节。
#[derive(Debug)] struct User { name: String, age: u32, student: bool } fn main() { let a = User { name: String::from("mike"), age: 20, student: false, }; let User { name, age, student, } = a; println!("{}", name); println!("{}", age); println!("{}", student); println!("{:?}", a); }
编译输出:
error[E0382]: borrow of partially moved value: `a`
--> src/main.rs:24:22
|
16 | name,
| ---- value partially moved here
...
24 | println!("{:?}", a);
| ^ value borrowed here after partial move
|
= note: partial move occurs because `a.name` has type `String`, which does not implement the `Copy` trait
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: borrow this binding in the pattern to avoid moving the value
|
16 | ref name,
| +++
编译提示出错了,在模式匹配的过程中发生了partially moved。关于partially moved我们在上节课已经讲过。模式匹配过程中新定义的三个变量 name、age、student 分别得到了对应User实例a的三个字段值的所有权。
age 和 student 采用了复制所有权的形式(参考 第 2 讲 移动还是复制部分),而 name 字符串值则是采用了移动所有权的形式。a.name被部分移动到了新的变量 name ,所以接下来 a.name 就无法直接使用了。
这个示例说明 Rust中的模式匹配是一种释放原对象的所有权的方式。
从Rust小助手的建议里我们看到了一个关键字:ref。
ref 关键字
Rustc AI小助手建议我们添加一个关键字ref,我们按它说的改改。
#[derive(Debug)] struct User { name: String, age: u32, student: bool } fn main() { let a = User { name: String::from("mike"), age: 20, student: false, }; let User { ref name, // 这里加了一个ref age, student, } = a; println!("{}", name); println!("{}", age); println!("{}", student); println!("{:?}", a); } // 输出 mike 20 false User { name: "mike", age: 20, student: false }
可以看到,打印出了正确的值。
有些情况下,我们只是需要读取一下字段的值而已,不需要获得它的所有权,这时就可以通过 ref 这个关键字修饰符告诉Rust编译器,我现在只需要获得那个字段的引用,不要给我所有权。这就是 ref 出现的原因,用来 在模式匹配过程中提供一个额外的信息。
使用了ref后,新定义的 name 变量的值其实是 &a.name ,而不是 a.name,Rust就不会再把所有权给move出来了,因此也不会发生partially moved这种事情,原来的User实例a还有效,因此就能被打印出来了。你可以体会一下其中的区别。
相应的,还有 ref mut 的形式。它是用于在模式匹配中获得目标的可变引用。
let User {
ref mut name, // 这里加了一个ref mut
age,
student,
} = a;
你可以做做实验体会一下。
Rust中强大的模式匹配这个概念并不是Rust原创的,它来自于函数式语言。你如果感兴趣的话,可以了解一下Ocaml、Haskell或Scala中模式匹配的相关概念。
函数参数中的模式匹配
函数参数其实就是定义局部变量,因此模式匹配的能力在这里也能得到体现。
示例1:
fn foo((a, b, c): (u32, u32, char)) { // 注意这里的定义 println!("{}", a); println!("{}", b); println!("{}", c); } fn main() { let a = (1,2, 'a'); foo(a); }
上例,我们把元组a传入了函数 foo(), foo() 的参数直接定义成模式匹配,解析出了 a、b、c 三个元组元素的内容,并在函数中使用。
示例2:
#[derive(Debug)] struct User { name: String, age: u32, student: bool } fn foo(User { // 注意这里的定义 name, age, student }: User) { println!("{}", name); println!("{}", age); println!("{}", student); } fn main() { let a = User { name: String::from("mike"), age: 20, student: false, }; foo(a); }
上例,我们把结构体a传入了函数 foo(), foo() 的参数直接定义成对结构体的模式匹配,解析出了 name、age、student 三个字段的内容,并在函数中使用。
小结
枚举是Rust中的重要概念,广泛用于属性配置、错误处理、分支流程、类型聚合等。在实际场景中,我们一般把结构体作为模型的主体承载,把枚举作为周边的辅助配置和逻辑分类。它们经常会搭配使用。
模式匹配是Rust里非常有特色的语言特性,我们在做分支逻辑处理的时候,可以通过模式匹配带上要处理的相关信息,还可以把这些信息解析出来,让代码的逻辑和数据内聚得更加紧密,让程序看起来更加赏心悦目。
思考题
match表达式的各个分支中,如果有不同的返回类型的情况,应该如何处理?欢迎你在评论区留下自己的答案,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
参考资料
- 格式化参数: https://shimo.im/outlink/gray?url=https%3A%2F%2Fdoc.rust-lang.org%2Fstd%2Ffmt%2Findex.html
- match的语法规则: https://doc.rust-lang.org/reference/expressions/match-expr.html
类型与类型参数:给Rust小助手提供更多信息
你好,我是Mike。今天我们一起来学习Rust中类型相关的知识。
这块儿知识在其他大部分语言入门材料中讲得不多,但是对于Rust而言,却是非常重要而有趣的。我们都知道,计算机硬件执行的代码其实是二进制序列。而 对一个二进制值来说,正是类型赋予了它意义。
比如 01100001 这个二进制数字,同样的内存表示,如果是整数,就表示97。如果是字符,就表示 'a' 这个 char。如果没有类型去赋予它额外的信息,当你看到这串二进制编码时,是不知道它代表什么的。
类型
《Programming.with.Types》2019 这本书里对类型做了一个定义,翻译出来是这样的:类型是对数据的分类,这个分类定义了这些数据的意义、被允许的值的集合,还有能在这些数据上执行哪些操作。编译器或运行时会检查类型化过程,以确保数据的完整性,对数据施加访问限制,以及把数据按程序员的意图进行解释。
有些情况下,我们会简化讨论,把操作部分忽略掉,所以我们可以简单地 把类型看作集合,这个集合表达了这个类型的实例能取到的所有可能的值。
类型系统
这本书里还定义了类型系统的概念。
书里是这样说的:类型系统是一套规则集——把类型赋予和施加到编程语言的元素上。这些元素可以是变量、函数和其他高阶结构。类型系统通过你在代码中提供的标注来给元素赋予类型,或者根据它的上下文隐式地推导某个元素的类型。类型系统允许在类型间做各种转换,同时禁止其他的一些转换。
举例来说,刚刚我们提到的类型的标注就像这种 let a: u32 = 10;。我们用 : u32 这种语法对变量a进行了标注,表明变量a的类型是 u32 类型。 u32 可以转换成 u64。
let b = a as u64;
但是 u32 不能直接转换到String上去。
fn main() { let a: u32 = 10; let b = a as String; // 错误的 println!("{b}"); }
类型化的好处
类型化有5大好处:正确性、不可变性、封装性、组合性、可读性。这5大好处中的每一个都是软件工程理论推崇的。
Rust语言非常强调 类型化,它的类型系统非常严格,隐式转换非常少,在某些简单场景下甚至会引起初学者的不适。
比如下面这个代码:
fn main() { let a = 1.0f32; let b = 10; let c = a * b; }
编译错误,提示你不能将一个浮点数和一个整数相乘。
error[E0277]: cannot multiply `f32` by `{integer}`
--> src/main.rs:5:15
|
5 | let c = a * b;
| ^ no implementation for `f32 * {integer}`
|
= help: the trait `Mul<{integer}>` is not implemented for `f32`
= help: the following other types implement trait `Mul<Rhs>`:
<&'a f32 as Mul<f32>>
<&f32 as Mul<&f32>>
<f32 as Mul<&f32>>
<f32 as Mul>
初学者遇到这种情况,往往会觉得Rust过于严苛,一个很自然的操作都不让我通过,烦死了,马上就想放弃了。
当遇到这种基础类型转换错误时,可以尝试使用 as 操作符 显式地将类型转成一致。
修改上述代码如下:
fn main() { let a = 1.0f32; let b = 10 as f32; // 添加了 as f32 let c = a * b; }
这段代码就可以编译通过了。
这里其实展示出Rust的一个非常明显的特点: 尽可能地显式化。显式化包含两层意思。
- 不做自动隐式转换。
- 没有内置转换策略。
不做自动隐式转换,可以这样来理解,比如前面的示例,当别人来看你的代码的时候,多了 as f32 这几个字符,他就明白你是在做类型转换,就会自然地警觉起来,分析上下文,估计出下面算出的结果是什么类型。这相当于由程序员为编译器明确地提供了一些额外的信息。
没有内置转换策略这一点,我们可以拿JavaScript社区中流传的一张梗图来对比说明。
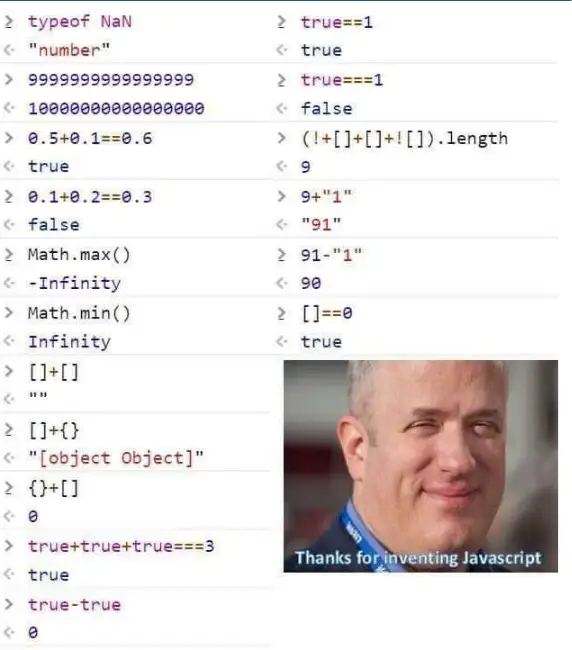
取图里的一个示例,在 JavaScript 里, 9 + "1" 计算出来的结果是 "91"。这其实就涉及两个不同类型之间相加如何处理的问题。在这个问题上,JavaScript 自己内置了策略,把两个不同类型的值加起来,硬生生算出了一个结果。而当遇到 91- "1" 时,策略又变了,算出了数字 90。这些就是内置类型转换策略的体现。
而在Rust中, 9+"1" 是不可能通过编译的,更不要说计算出一个神奇的结果了。如果要写出类似的代码,在Rust中可以这样做。
fn main() { let a = 9 + '1' as u8; let b = 9.to_string() + "1"; }
有没有觉得特别清晰!我们一眼就能推断出 a 和 b 的类型,a为u8类型,b为String类型。
这就是Rust的严谨,它有着严密的类型体系,在类型化上绝不含糊。它从底层到上层构建了一套完整严密的类型大厦。你的项目越大,使用Rust感觉也就越舒服,原因之一就是严谨的类型系统在为你保驾护航。
类型作为一种约束
前面提到,类型是变量所有可能取得的值的集合。换句话说,类型实际上限制或定义了变量的取值空间。因此, 类型对于变量来说,也是一种约束。
实际上,Rust中的 : (冒号)在语法层面上就是约束。
示例:
let a: u8 = 10;
let b: String = "123".to_string();
上述示例中,变量a被限制为只能在u8这个类型的值空间取值,也就是0到255这256个整数里的一个,而10属于这个空间。变量b被限制为只能在字符串值空间内取值。不管字符串的值空间多大(其实是无限),这些值与u8、u32这些类型的值也是不同的。
关于 : 作为约束的体现,我们会在后面的课程中不断看到。
多种类型如何表示?
前面我们讲到了,用一种类型来对变量的取值空间进行约束。这确实非常好,有利于程序的健壮性。但有时也会遇到这种方式不够用的场景。比如在Rust中,我们把整数分成 u8、u16、u32、u64。现在我想写一个函数,它的参数支持整数,也就是说要同时能接受u8、u16、u32、u64这几种类型的值,应该怎么办?如果只是采用前面的理论,这个需求是没法做到的。
再看另外一个实际的例子,我有一个日志函数,可以给这个函数传入数字、字符串等类型。这种需求很常见。如何让这一个日志函数同时支持数字和字符串作为参数呢?这就很头痛了。
这里实际提出了这样一个问题: 在Rust语言中,有没有办法用某种方式来表示多种类型? 答案是有的。
类型参数
在Rust语言中定义类型的时候,可以使用 类型参数。比如标准库里常见的 Vec<T>,就带一个类型参数T,它可以支持不同类型的列表,如 Vec<u8>、 Vec<u32>、 Vec<String> 等。这里这个 T 就表示一个类型参数,在定义时还不知道它具体是什么类型。只有在使用的时候,才会对这个 T 赋予一个具体的类型。
这里这个 Vec<T>,是一个类型整体,单独拆开来讲Vec类型是没有意义的。T是 Vec<T> 中的类型参数,它其实也是信息,提供给Rust编译器使用。而带类型参数的类型整体(比如 Vec<T>)就叫做 泛型(generic type)。
结构体中的类型参数
我们来看一个例子,自定义一个结构体 Point<T>。
struct Point<T> {
x: T,
y: T,
}
这是一个二维平面上的点,由x、y两个坐标轴来定义。因为x、y的取值有可能是整数,也有可能是浮点数,甚至有可能是其他值,比如无穷精度的类型。所以我们定义一个类型参数 T,定义的时候需要把T放在结构体类型名字后面,用 <> 括起来,也就是 struct Point<T>。这里的 Point<T> 整体就成为了泛型。然后,标注 x 和 y 分量的类型都是 T。可以看到,T占据了冒号后面定义类型的位置。所以说它是 占位类型 也没有问题。
对这个结构体的例子来说,其实还隐藏了一个很重要的细节:x和y字段的类型都是T,意味着 x 和 y 两个分量的类型是一样的。
我们来看这个Point结构体类型如何实例化。
struct Point<T> { x: T, y: T, } fn main() { let integer = Point { x: 5, y: 10 }; // 一个整数point let float = Point { x: 1.0, y: 4.0 }; // 一个浮点数point }
符合我们预期,正常编译通过。那如果实例化的时候,给x和y赋予不同的类型值会怎样呢?我们来试试。
struct Point<T> { x: T, y: T, } fn main() { let wont_work = Point { x: 5, y: 4.0 }; } $ cargo run Compiling chapter10 v0.1.0 (file:///projects/chapter10) error[E0308]: mismatched types --> src/main.rs:7:38 | 7 | let wont_work = Point { x: 5, y: 4.0 }; | ^^^ expected integer, found floating-point number
编译器正确地指出了问题,说期望整数却收到了浮点数,所以不通过。
这里有个细节,那就是编译器对 Point<T> 中的T参数进行了推导,因为它首先遇到的是x的值 5,是一个整数类型,因此编译器就把 T 具体化成了整数类型(具体哪一种还没说,不过在这里不重要),当再收到y分量的值的时候,发现是浮点数类型,和刚才的整数类型不一致了。而Point中定义的时候,又要求x和y的类型是相同的,这个时候就产生了冲突,于是报错。
那么,如何解决这个问题呢?Rust并没有限制我们只能定义一个类型参数呀!定义多个就好了,把x分量和y分量定义成不同的参数化类型。
struct Point<T, U> { x: T, y: U, } fn main() { let both_integer = Point { x: 5, y: 10 }; let both_float = Point { x: 1.0, y: 4.0 }; let integer_and_float = Point { x: 5, y: 4.0 }; }
像这样,代码就可以顺利通过编译了。
再次强调,前面两个示例里的 Point<T> 和 Point<T, U> 都是一个类型整体。这个时候,你把 Point 这个符号本身单独拿出来是没有意义的。
在使用的时候,可以用turbofish语法 ::<> 明确地给泛型,或者说是给Rust编译器提供类型参数信息,我们修改一下上面两个示例。
struct Point<T> { x: T, y: T, } fn main() { let integer = Point::<u32> { x: 5, y: 10 }; let float = Point::<f32> { x: 1.0, y: 4.0 }; }
struct Point<T, U> { x: T, y: U, } fn main() { let both_integer = Point::<u32, u32> { x: 5, y: 10 }; let both_float = Point::<f32, f32> { x: 1.0, y: 4.0 }; let integer_and_float = Point::<u32, f32> { x: 5, y: 4.0 }; }
注意,使用时提供类型参数信息用的是 ::<>,而定义类型参数的时候只用到 <>,注意它们的区别。Rust把定义和使用两个地方通过语法明确地区分开了,而有的语言并没有区分这两个地方。
到这里,我们会体会到,类型参数存在两个过程, 一个是定义时,一个是使用时。这两个过程的区分很重要。这里所谓的“使用时”,仍然是在编译期进行分析的,也就是分析你在代码的某个地方用到了这个带类型参数的类型,然后把这个参数具体化,从而形成一个最终的类型版本。
比如 Point<T> 类型的具化类型可能是 Point<u32>、 Point<f32> 等等; Point<T, U> 类型的具化类型可能是 Point<u32, u32>、 Point<u32, f32>、 Point<f32, u32>、 Point<f32, f32> 等等。到底有多少种具化版本,是看你在后面代码使用时,会用到多少种不同的具体类型。这个数目是由编译器自动帮我们计算展开的。
这种在编译期间完成的类型展开成具体版本的过程,被叫做 编译期单态化。 单态化的意思就是把处于混沌未知的状态具体化到一个单一的状态。
在泛型上做impl
当类型是一个泛型时,要对其进行impl的话,需要处理类型参数,形式相比于我们在 第 5 讲 讲到的impl 结构体,有一点变化。这里我们还是用 Point<T> 举例。
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> { // 注意这一行
fn play(n: T) {} // 注意这一行
}
在对 Point<T> 做 impl 的时候,需要在 impl 后面加一个 <T>,表示在impl 的 block 中定义类型参数T,供impl block中的元素使用,这些元素包括: impl<T> Point<T> 里 Point<T> 中的T和整个 impl 的花括号body中的代码,如 play() 函数的参数就用到了这个T。
有一个细节需要注意: struct Point<T> 里 Point<T> 中的 T 是定义类型参数T, impl<T> Point<T> 中的 Point<T> 中的T是使用类型参数T,这个T是在impl后面那个尖括号中定义的。
在对泛型做了 impl 后,对其某一个具化类型继续做 impl 也是可以的,比如:
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn play(n: T) {}
}
impl Point<u32> { // 这里,对具化类型 Point<u32> 继续做 impl
fn doit() {}
}
下面我们来看具体场景中的类型参数的使用。
枚举中的类型参数
前面讲过,枚举的变体可以挂载任意其他类型作为负载。因此每个负载的位置,都可以出现类型参数。比如最常见的两个枚举, Option<T> 与 Result<T, E>,就是泛型。
Option<T> 用来表示有或无。
enum Option<T> {
Some(T),
None,
}
Result<T, E> 用来表示结果,正确或错误。Ok变体带类型参数T,Err变体带类型参数E。
enum Result<T, E> {
Ok(T),
Err(E),
}
我们后面会详细阐述 Option<T> 和 Result<T, E> 的用法。
现在再看一个更复杂的枚举中带类型参数的例子。
struct Point<T> {
x: T,
y: T,
}
enum Aaa<T, U> {
V1(Point<T>),
V2(Vec<U>),
}
我们来解释一下,枚举 Aaa<T, U> 的变体 V1 带了一个 Point<T> 的负载,变体V2带了一个 Vec<U> 的负载。由于出现了两个类型参数T和U,所以需要在Aaa后面的尖括号里定义这两个类型参数。
实际上,类型参数也是一种复用代码的方式,可以让写出的代码更紧凑。下面我们来看具体的应用场景。
函数中的类型参数
需求是这样的:很多不同的类型,其实它们实现某个逻辑时,逻辑是一模一样的。因此如果没有类型参数,就得对每个具体的类型重新实现一次同样的逻辑,这样就显得代码很臃肿。重复的代码也不好维护,容易出错。
示例:
struct PointU32 { x: u32, y: u32, } struct PointF32 { x: f32, y: f32, } fn print_u32(p: PointU32) { println!("Point {}, {}", p.x, p.y); } fn print_f32(p: PointF32) { println!("Point {}, {}", p.x, p.y); } fn main() { let p = PointU32 {x: 10, y: 20}; print_u32(p); let p = PointF32 {x: 10.2, y: 20.4}; print_f32(p); }
上面示例中,因为我们没有使用类型参数,那就得针对不同的字段类型(u32,f32)分别定义结构体(PointU32,PointF32)和对应的打印函数(print_u32,print_f32),并分别调用。
而有了类型参数的话,这样的需求代码只需要写一份,让编译器来帮我们分析到时候要应用到多少种不同的类型上。
上面的代码可以优化成这样:
struct Point<T> { x: T, y: T, } fn print<T: std::fmt::Display>(p: Point<T>) { println!("Point {}, {}", p.x, p.y); } fn main() { let p = Point {x: 10, y: 20}; print(p); let p = Point {x: 10.2, y: 20.4}; print(p); }
是不是清爽多了!
实际上,清爽只是我们看到的样子。在编译的时候,Rust编译器会帮助我们把这种泛型代码展开成前面那个示例的样子。这种脏活累活,Rust编译器帮我们完成了。
细心的你可能发现了,print函数的类型参数在定义的时候,多了一个东西。
fn print<T: std::fmt::Display>(p: Point<T>) {
这里 T: std::fmt::Display 的意思是要求 T 满足某些条件/约束。这里具体来说就是 T 要满足可以被打印的条件。因为我们这个函数的目的是把 x 和 y 分量打印出来,那么它确实要能被打印才行,比如得能转换成人类可见的某种格式。
关于这种约束,我们后面会详细讲述。
方法中的类型参数
结构体中可以有类型参数,函数中也可以有类型参数,它们组合起来,方法上当然也可以有类型参数。
示例:
struct Point<T> { x: T, y: T, } impl<T> Point<T> { // 在impl后定义impl block中要用到的类型参数 fn x(&self) -> &T { // 这里,在方法的返回值上使用了这个类型参数 &self.x } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); } // 输出 p.x = 5
上面的示例中, Point<T> 的方法 x() 的返回值类型就是 &T,使用到了 impl<T> 这里定义的类型参数T。
下面我们继续看更复杂的内容,方法中的类型参数和结构体中的类型参数可以不同。
struct Point<X1, Y1> { x: X1, y: Y1, } // 这里定义了impl block中可以使用的类型参数X3, Y3, impl<X3, Y3> Point<X3, Y3> { // 这里单独为mixup方法定义了两个新的类型参数 X2, Y2 // 于是在mixup方法中,可以使用4个类型参数:X3, Y3, X2, Y2 fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X3, Y2> { Point { x: self.x, y: other.y, } } } fn main() { let p1 = Point { x: 5, y: 10.4 }; let p2 = Point { x: "Hello", y: 'c' }; let p3 = p1.mixup(p2); println!("p3.x = {}, p3.y = {}", p3.x, p3.y); } // 输出 p3.x = 5, p3.y = c
可以看到,我们在 Point<X3, Y3> 的方法 mixup() 上新定义了两个类型参数X2、Y2,于是在 mixup() 方法中,可以同时使用4个类型参数:X2、Y2、X3、Y3。你可以品味一下这个示例,不过这种复杂情况,现在的你只需要了解就可以了。
接下来我们来聊一聊Rust里的类型体系构建方法。
类型体系构建方法
类型体系构建指的是如何从最底层的小砖块开始,通过封装、组合、集成,最后修建成一座类型上的摩天大楼。在Rust里,主要有四大基础设施参与这个搭建的过程。
- struct 结构体
- enum 枚举
- 洋葱结构
- type 关键字
struct和enum
struct是Rust里把简单类型组合起来的主要结构。struct里的字段可以是基础类型,也可以是其他结构体或枚举等复合类型,这样就可以一层一层往上套。结构体struct表达的是一种元素间同时起作用的结构。
而枚举enum表达的是一种元素间在一个时刻只有一种元素起作用的结构。因此枚举类型特别适合做配置和类型聚合之类的工作。
你可以看一下下面的综合示例,它是对某个学校的数学课程建模的层级模型。
struct Point(u32, u32); // 定义点
struct Rectangle { // 长方形由两个点决定
p1: Point,
p2: Point,
}
struct Triangle(Point, Point, Point); // 三角形由三个点组成
struct Circle(Point, u32); // 圆由点和半径组成
enum Shape { // 由枚举把长方形,三角形和圆形聚合在一起
Rectangle(Rectangle),
Triangle(Triangle),
Circle(Circle),
}
struct Axes; // 定义坐标
struct Geometry { // 几何学由形状和坐标组成
shape: Shape,
axes: Axes,
}
struct Algebra; // 定义代数
enum Level { // 定义学校的级别
Elementary, // 小学
Secondary, // 初中
High, // 高中
}
enum Course { // 数学要学习几何和代数,由枚举来聚合
Geometry(Geometry),
Algebra(Algebra),
}
struct MathLesson { // 定义数学课程,包括数学的科目和级别
math: Course,
level: Level,
}
请根据注释认真体会其中类型的层级结构。你甚至可以试着去编译一下上述代码,看看是不是可以编译通过。
偷偷告诉你答案:是可以通过的!
newtype
结构体还有一种常见的封装方法,那就是用单元素的元组结构体。比如定义一个列表类型 struct List(Vec<u8>);。它实际就是 Vec<u8> 类型的一个新封装,相当于给里面原来那种类型取了一个新名字,同时也把原类型的属性和方法等屏蔽起来了。
有时,你还可以看到没有具化类型参数的情形。
struct List<T>(Vec<T>);
这种模式非常常见,于是业界给它取了个名字,叫做 newtype 模式,意思是用新的类型名字替换里面原来那个类型名字。
洋葱结构
Rust中的类型还有另外一种构建方法——洋葱结构。我们来看一个示例,注意代码里的type关键字在这里的作用是把一个类型重命名,取了一个更短的名字。
// 你可以试着编译这段代码
use std::collections::HashMap;
type AAA = HashMap<String, Vec<u8>>;
type BBB = Vec<AAA>;
type CCC = HashMap<String, BBB>;
type DDD = Vec<CCC>;
type EEE = HashMap<String, DDD>;
最后EEE展开就是这样的:
HashMap<String, Vec<HashMap<String, Vec<HashMap<String, Vec<u8>>>>>>;
可以看到,尖括号的层数很多,像洋葱一样一层一层的,因此叫洋葱类型结构。只要你开心,你可以把这个层次无限扩展下去。
我们再来看一个结合 newtype 和 struct 的更复杂的示例。
use std::collections::HashMap;
struct AAA(Vec<u8>);
struct BBB {
hashmap: HashMap<String, AAA>
}
struct CCC(BBB);
type DDD = Vec<CCC>;
type EEE = HashMap<String, Vec<DDD>>;
最后,EEE展开就类似下面这样(仅示意,无法编译通过)
HashMap<String, Vec<Vec<CCC(BBB {hashmap: HashMap<String, AAA<Vec<u8>>>})>>>
可以看到,洋葱结构在嵌套层级多了之后,展开是相当复杂的。
type关键字
type关键字很重要,它的作用是在洋葱结构表示太长了之后,把一大串类型的表达简化成一个简短的名字。在Rust中使用type关键字,可以使类型大厦的构建过程变得清晰可控。
type关键字还可以处理泛型的情况,比如:
type MyType<T> = HashMap<String, Vec<HashMap<String, Vec<HashMap<String, Vec<T>>>>>>;
因为最里面那个是类型 Vec<T>,T 类型参数还在。因此给这个洋葱类型重命名的时候,需要把这个 T 参数带上,于是就变成了 MyType<T>。
这种写法在标准库里很常见,最佳示例就是关于各种 Result* 的定义。
在 std::io 模块里,取了一个与 std::result::Result<T, E> 同名的 Result 类型,把 std::result::Result<T, E> 定义简化了,具化其Error类型为 std::io::Error,同时仍保留了第一个类型参数 T。于是得到了 Result<T>。
pub type Result<T> = Result<T, Error>;
刚开始接触Rust的时候,你可能会对这种表达方式产生疑惑,其实道理就在这里。以后你在阅读Rust生态中各种库的源码时,也会经常遇到这种封装方式,所以我们要习惯它。
关于这种定义更多的资料参见:
https://doc.rust-lang.org/std/result/enum.Result.html
https://doc.rust-lang.org/std/io/type.Result.html
https://doc.rust-lang.org/std/io/struct.Error.html
小结
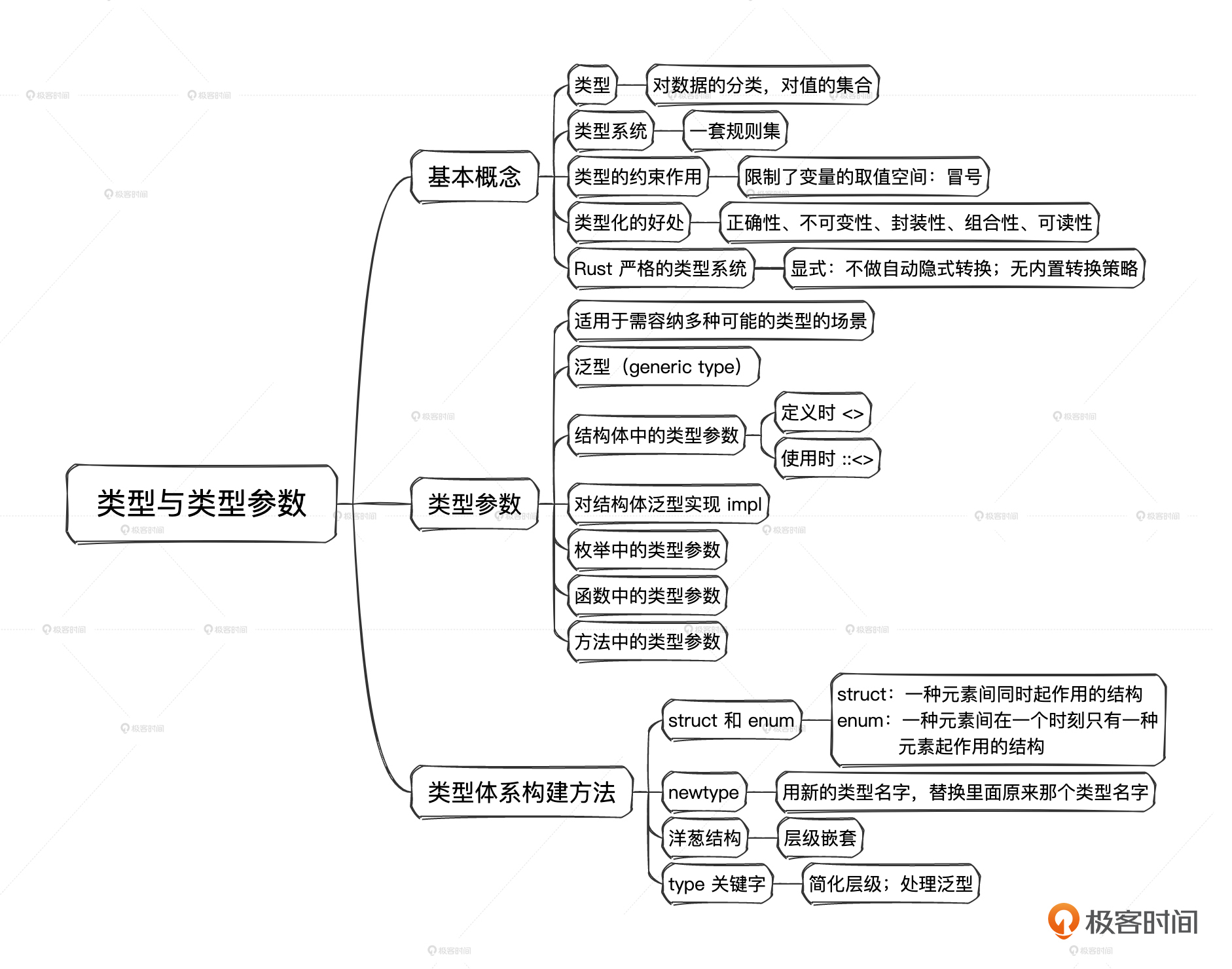
这节课我们对Rust中类型相关的知识做了一个专门的讲解。现代编程语言的趋势是越来越强调类型化,比如 TypeScript、Rust。一个成熟的类型系统对于编写健壮的程序来说至关重要。类型可以看作是对变量取值空间的一种约束。
在Rust中,有很多对多种类型做统一处理的需求,因此引入了类型参数和泛型的概念。它们实际是在类型化道路上的必然选择,因为单一的类型确实不方便,或者不能满足我们的需求。你要先克服对这种参数化设计的畏惧感,只要花一些时间熟悉这节课我们提到的那些形式,这些概念就不难掌握。
然后,这节课我们还讲解了4种类型体系建模方法,你可以在后面的实践过程中慢慢加深理解。
思考题
如果你给某个泛型实现了一个方法,那么,还能为它的一个具化类型再实现同样的方法吗?
欢迎你把思考后的结果分享到评论区,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!
《Programming.with.Types》原文摘录



Option与Result<T, E>、迭代器
你好,我是Mike,今天我们一起来重点学习在Rust中高频使用的 Option<T>、 Result<T, E>、迭代器,通过学习这些内容,我们可以继续夯实集合中所有权相关的知识点。
Option<T> 和 Result<T, E> 并不是Rust的独创设计,在Rust之前,OCaml、Haskell、Scala等已经使用它们很久了。新兴的一批语言Kotlin、Swift 等也和Rust一样引入了这两种类型。而C++17之后也引入了它们。
这其实能说明使用 Option<T> 和 Result<T, E> 逐渐成了编程语言圈子的一种新共识。而迭代器已经是目前几乎所有主流语言的标配了,所以我们也来看看Rust中的迭代器有什么独到的地方。
如果你习惯了命令式编程或OOP编程,那么这节课我们提到各种操作对你来说可能有点陌生,不过也不用担心,这节课我设计了大量示例,你可以通过熟悉这些示例代码,掌握Rust中地道的编程风格。
Option<T> 与 Result<T, E>
Option<T> 与 Result<T, E> 在Rust代码中随处可见,但是我们到现在才开始正式介绍,就是因为它们实际是带类型参数的枚举类型。
Option<T> 的定义
pub enum Option<T> {
None,
Some(T),
}
Option<T> 定义为包含两个变体的枚举。一个是不带负载的None,另一个是带一个类型参数作为其负载的Some。 Option<T> 的实例在Some和None中取值, 表示这个实例有取空值的可能。
你可以把 Option<T> 理解为把空值单独提出来了一个维度。在没有 Option<T> 的语言中,空值是分散在其他类型中的。比如空字符串、空数组、数字0、NULL指针等。并且有的语言还把空值区分为空值和未定义的值,如 nil、undefined等。
Rust做了两件事情来解决这个混乱的场面。第一,Rust中所有的变量定义后使用前都必须初始化,所以不存在未定义值这个情况。第二,Rust把空值单独提出来统一定义成 Option<T>::None,并在标准库层面上就做好了规范,上层的应用在设计时也应该遵循这个规范。
我们来看一个示例。
let s = String::from("");
let a: Option<String> = Some(s);
变量a是携带空字符串的 Option<String> 类型。这里,空字符串""的“空”与None所表示的“无”表达了不同的意义。
如果早点发明Option,Tony Hoare就不会自责了。Tony Hoare在 一次分享 中说,他在1965年发明的空引用(Null references)是一个“十亿美元”的错误。
他是这样说的:我把它叫做我的十亿美元错误。那个时候,我正在为一个面向对象语言中的引用设计第一个全面的类型系统。我的目标是让编译器自动施加检查,来确保对引用的所有使用都是绝对安全的。但是我当时无法抵抗空引用的诱惑,就是因为它非常容易实现。这导致了难以计数的错误、漏洞和系统崩溃,在后续40年里这可能已经导致了十亿美元的痛苦和破坏。
Rust通过所有权并借用检查器、 Option<T>、 Result<T, E> 等一整套机制全面解决了Hoare想解决的问题。
Result<T, E> 的定义
我们先来看一个示例。
pub enum Result<T, E> {
Ok(T),
Err(E),
}
Result<T, E> 被定义为包含两个变体的枚举。这两个变体各自带一个类型参数作为其负载。 Ok(T) 用来表示结果正确, Err(E) 用来表示结果有错误。
对比其他语言函数错误返回的约定,C、CPP、Java语言里有时用返回0来表示函数执行正确,有时又不是这样,你需要根据代码所在的上下文环境来判断返回什么值代表正确,返回什么值代表错误。
而Go语言强制对函数返回值做出了约定。
ret, err := function()
if err != nil {
约定要求函数返回两个值,正确的情况下, ret 存放返回值, err 为 nil。如果函数要返回错误值,那么会给 err 变量填充具体的内容,于是就出现了经典的满屏 if err != nil 代码,成了Go语言圈的一个梗。可以看到,Go语言已经朝着把错误信息和正常返回值类型剥离开来的方向走出了一步。
而Rust没有像Go那样设计,一是因为Rust不存在单独的 nil 这种空值,二是Rust直接用带类型参数的枚举就可以达到这个目的。
一个枚举实例在一个时刻只能是那个枚举类型的某一个变体。所以一个函数的返回值,不论它是正确的情况还是错误的情况,都能用 Result<T, E> 类型统一表达,这样会显得更紧凑。同时还因为 Result<T, E> 是一种类型,我们可以在它之上添加很多操作,用起来很方便。下面我用例子来给你讲解。
let r: Result<String, String> = function();
这个例子表示将函数返回值赋给变量r,返回类型是 Result<String, String>。在正确的情况下,返回内容为String类型;错误的情况下,被返回的错误类型也是String。你是不是在想:两种可以一样?当然可以,这两个类型参数可以被任意类型代入。
Result<T, E> 被用来支撑Rust的错误处理机制,所以非常重要。我们会在第18讲详细讲述基于 Result<T, E> 的错误处理。
解包
现在我们遇到了一个问题,比如 Option<u32>::Some(10) 和 10u32 明显已经不是同一种类型了。我们真正想要的值被“包裹”在了另外一种类型里面。这种“包裹”是通过枚举变体来实现的。那我们想获取被包在里面的值应该怎么做呢?
其实有很多办法,我们先讲一类解包操作。这里我列出了三种方法,分别是 expect()、 unwrap()、 unwrap_or()。我给出了它们解包的具体操作和示例代码,你可以看一下有什么不同。

示例:
// Option
let x = Some("value");
assert_eq!(x.expect("fruits are healthy"), "value");
// Result
let path = std::env::var("IMPORTANT_PATH")
.expect("env variable `IMPORTANT_PATH` should be set by `wrapper_script.sh`");

示例:
// Option
let x = Some("air");
assert_eq!(x.unwrap(), "air");
// Result
let x: Result<u32, &str> = Ok(2);
assert_eq!(x.unwrap(), 2);
示例:
// Option
assert_eq!(Some("car").unwrap_or("bike"), "car");
assert_eq!(None.unwrap_or("bike"), "bike");
// Result
let default = 2;
let x: Result<u32, &str> = Ok(9);
assert_eq!(x.unwrap_or(default), 9);
let x: Result<u32, &str> = Err("error");
assert_eq!(x.unwrap_or(default), default);
示例:
// Option
let x: Option<u32> = None;
let y: Option<u32> = Some(12);
assert_eq!(x.unwrap_or_default(), 0);
assert_eq!(y.unwrap_or_default(), 12);
// Result
let good_year_from_input = "1909";
let bad_year_from_input = "190blarg";
let good_year = good_year_from_input.parse().unwrap_or_default();
let bad_year = bad_year_from_input.parse().unwrap_or_default();
assert_eq!(1909, good_year);
assert_eq!(0, bad_year);
可以看到,解包操作挺费劲的。如果我们总是先用 Option<T> 或 Result<T, E> 把值包裹起来,用的时候再手动解包,那其实说明没有真正抓住到 Option<T> 和 Result<T, E> 的设计要义。在Rust中,很多时候我们不需要解包也能操作里面的值,这样就不用做看起来多此一举的解包操作了。下面我们来看一下在不解包的情况下,我们可以怎样做。
不解包的情况下如何操作?
不解包的情况下如果想要获取被包在里面的值就需要用到 Option<T> 和 Result<T, E> 里的一些常用方法。
Option<T> 上的常用方法和示例:
- map():在 Option 是 Some 的情况下,通过 map 中提供的函数或闭包把 Option 里的类型转换成另一种类型。在 Option 是 None 的情况下,保持 None 不变。map() 会消耗原类型,也就是获取所有权。
let maybe_some_string = Some(String::from("Hello, World!"));
let maybe_some_len = maybe_some_string.map(|s| s.len());
assert_eq!(maybe_some_len, Some(13));
let x: Option<&str> = None;
assert_eq!(x.map(|s| s.len()), None);
- cloned():通过克隆 Option 里面的内容,把
Option<&T>转换成Option<T>。
let x = 12;
let opt_x = Some(&x);
assert_eq!(opt_x, Some(&12));
let cloned = opt_x.cloned();
assert_eq!(cloned, Some(12));
- is_some():如果 Option 是 Some 值,返回 true。
let x: Option<u32> = Some(2);
assert_eq!(x.is_some(), true);
let x: Option<u32> = None;
assert_eq!(x.is_some(), false);
- is_none():如果 Option 是 None 值,返回 true。
let x: Option<u32> = Some(2);
assert_eq!(x.is_none(), false);
let x: Option<u32> = None;
assert_eq!(x.is_none(), true);
- as_ref():把
Option<T>或&Option<T>转换成Option<&T>。创建一个新 Option,里面的类型是原来类型的引用,就是从Option<T>到Option<&T>。原来那个Option<T>实例保持不变。
let text: Option<String> = Some("Hello, world!".to_string());
let text_length: Option<usize> = text.as_ref().map(|s| s.len());
println!("still can print text: {text:?}");
- as_mut():把
Option<T>或&mut Option<T>转换成Option<&mut T>。
let mut x = Some(2);
match x.as_mut() {
Some(v) => *v = 42,
None => {},
}
assert_eq!(x, Some(42));
- take():把 Option 的值拿出去,在原地留下一个 None 值。这个非常有用。相当于把值拿出来用,但是却没有消解原来那个 Option。
let mut x = Some(2);
let y = x.take();
assert_eq!(x, None);
assert_eq!(y, Some(2));
let mut x: Option<u32> = None;
let y = x.take();
assert_eq!(x, None);
assert_eq!(y, None);
- replace():在原地替换新值,同时把原来那个值抛出来。
let mut x = Some(2);
let old = x.replace(5);
assert_eq!(x, Some(5));
assert_eq!(old, Some(2));
let mut x = None;
let old = x.replace(3);
assert_eq!(x, Some(3));
assert_eq!(old, None);
- and_then():如果 Option 是 None,返回 None;如果 Option 是 Some,就把参数里面提供的函数或闭包应用到被包裹的内容上,并返回运算后的结果。
fn sq_then_to_string(x: u32) -> Option<String> {
x.checked_mul(x).map(|sq| sq.to_string())
}
assert_eq!(Some(2).and_then(sq_then_to_string), Some(4.to_string()));
assert_eq!(Some(1_000_000).and_then(sq_then_to_string), None); // overflowed!
assert_eq!(None.and_then(sq_then_to_string), None);
我们再看 Result<T, E> 上的常用方法和示例。
- map():当 Result 是 Ok 的时候,把 Ok 里的类型通过参数里提供的函数运算并且可以转换成另外一种类型。当 Result 是 Err 的时候,原样返回 Err 和它携带的内容。
let line = "1\n2\n3\n4\n";
for num in line.lines() {
match num.parse::<i32>().map(|i| i * 2) {
Ok(n) => println!("{n}"),
Err(..) => {}
}
}
- is_ok():如果 Result 是 Ok,返回 true。
let x: Result<i32, &str> = Ok(-3);
assert_eq!(x.is_ok(), true);
let x: Result<i32, &str> = Err("Some error message");
assert_eq!(x.is_ok(), false);
- is_err():如果 Result 是 Err,返回 true。
let x: Result<i32, &str> = Ok(-3);
assert_eq!(x.is_err(), false);
let x: Result<i32, &str> = Err("Some error message");
assert_eq!(x.is_err(), true);
- as_ref():创建一个新 Result,里面的两种类型分别是原来两种类型的引用,就是从
Result<T, E>到Result<&T, &E>。原来那个Result<T, E>实例保持不变。
let x: Result<u32, &str> = Ok(2);
assert_eq!(x.as_ref(), Ok(&2));
let x: Result<u32, &str> = Err("Error");
assert_eq!(x.as_ref(), Err(&"Error"));
- as_mut():创建一个新 Result,里面的两种类型分别是原来两种类型的可变引用,就是从
Result<T, E>到Result<&mut T, &mut E>。原来那个Result<T, E>实例保持不变。
fn mutate(r: &mut Result<i32, i32>) {
match r.as_mut() {
Ok(v) => *v = 42,
Err(e) => *e = 0,
}
}
let mut x: Result<i32, i32> = Ok(2);
mutate(&mut x);
assert_eq!(x.unwrap(), 42);
let mut x: Result<i32, i32> = Err(13);
mutate(&mut x);
assert_eq!(x.unwrap_err(), 0);
- and_then():当 Result 是 Ok 时,把这个方法提供的函数或闭包应用到 Ok 携带的内容上面,并返回一个新的 Result。当 Result 是 Err 的时候,这个方法直接传递返回这个 Err 和它的负载。这个方法常常用于一路链式操作,前提是过程里的每一步都需要返回 Result。
fn sq_then_to_string(x: u32) -> Result<String, &'static str> {
x.checked_mul(x).map(|sq| sq.to_string()).ok_or("overflowed")
}
assert_eq!(Ok(2).and_then(sq_then_to_string), Ok(4.to_string()));
assert_eq!(Ok(1_000_000).and_then(sq_then_to_string), Err("overflowed"));
assert_eq!(Err("not a number").and_then(sq_then_to_string), Err("not a number"));
- map_err():当 Result 是 Ok 时,传递原样返回。当 Result 是 Err时,对 Err 携带的内容使用这个方法提供的函数或闭包进行运算及类型转换。这个方法常常用于转换 Result 的 Err 的负载的类型,在错误处理流程中大量使用。
fn stringify(x: u32) -> String { format!("error code: {x}") }
let x: Result<u32, u32> = Ok(2);
assert_eq!(x.map_err(stringify), Ok(2));
let x: Result<u32, u32> = Err(13);
assert_eq!(x.map_err(stringify), Err("error code: 13".to_string()));
Option<T> 与 Result<T, E> 的相互转换
Option<T> 与 Result<T, E> 之间是可以互相转换的。转换的时候需要注意, Result<T, E> 比 Option<T> 多一个类型参数,所以它带的信息比 Option<T> 多一份,因此核心要点就是 要注意信息的添加与抛弃。
从Option<T> 到 Result<T, E>:ok_or()
Option<T> 实例如果是 Some,直接把内容重新包在 Result<T, E>::Ok() 里。如果是 None,使用 ok_or() 里提供的参数作为 Err 的内容。
let x = Some("foo");
assert_eq!(x.ok_or(0), Ok("foo"));
let x: Option<&str> = None;
assert_eq!(x.ok_or(0), Err(0));
从 Result<T, E> 到 Option<T>:ok()
如果 Result<T, E> 是 Ok,就把内容重新包在 Some 里。如果 Result<T, E> 是 Err,就直接换成 None,丢弃 Err 里的内容,同时原 Result<T, E> 实例被消费。
let x: Result<u32, &str> = Ok(2);
assert_eq!(x.ok(), Some(2));
let x: Result<u32, &str> = Err("Nothing here");
assert_eq!(x.ok(), None);
从 Result<T, E> 到 Option<T>:err()
如果 Result<T, E> 是 Ok,直接换成 None,丢弃 Ok 里的内容。如果 Result<T, E> 是 Err,把内容重新包在 Some 里,同时原 Result<T, E> 实例被消费。
let x: Result<u32, &str> = Ok(2);
assert_eq!(x.err(), None);
let x: Result<u32, &str> = Err("Nothing here");
assert_eq!(x.err(), Some("Nothing here"));
下面我们讲讲迭代器。
迭代器
迭代器其实很简单,就是对一个集合类型进行遍历。比如对 Vec<T>、对 HashMap<K, V> 等进行遍历。使用迭代器有一些好处,比如:
- 按需使用,不需要把目标集合一次性全部加载到内存,使用一点加载一点。
- 惰性计算,可以用来表达无限区间,比如第一讲我们说的range,可以表达1到无限这个集合,这种在其他有些语言中很难表达。
- 可以安全地访问边界,不需要使用有访问风险的下标操作符。
next() 方法
迭代器上有一个标准方法,叫作 next(),这个方法返回 Option<Item>,其中 Item 就是组成迭代器的元素。这个方法的字面意思就是 迭代出下一个元素。如果这个集合被迭代完成了,那么最后一次执行会返回 None。比如下面的例子,在迭代器上调用 .next() 返回 u32 数字。
fn main() { let a: Vec<u32> = vec![1, 2, 3, 4, 5]; let mut an_iter = a.into_iter(); // 将Vec<u32>转换为迭代器 while let Some(i) = an_iter.next() { // 调用 .next() 方法 println!("{i}"); } } // 输出 1 2 3 4 5
实际上,Rust中不止 into_iter() 这一种将集合转换成迭代器的方法。
iter()、 iter_mut()、 into_iter() 与三种迭代器
Rust中的迭代器根据所有权三态可以分成三种。
- 获取集合元素不可变引用的迭代器,对应方法为
iter()。 - 获取集合元素可变引用的迭代器,对应方法为
iter_mut()。 - 获取集合元素所有权的迭代器,对应方法为
into_iter()。
在Rust标准库约定中,如果你看到一个类型上实现了 iter() 方法,那么它会返回获取集合元素不可变引用的迭代器;如果你看到一个类型上实现了 iter_mut() 方法,那么它会返回获取集合元素可变引用的迭代器;如果你看到一个类型上实现了 into_iter() 方法,那么它会返回获取集合元素所有权的迭代器。调用了这个迭代器后,迭代器的执行会消耗掉原集合。
我们来看这三种不同的迭代器的一个对比。
fn main() { let mut a = [1, 2, 3]; // 一个整数数组 let mut an_iter = a.iter(); // 转换成第一种迭代器 assert_eq!(Some(&1), an_iter.next()); assert_eq!(Some(&2), an_iter.next()); assert_eq!(Some(&3), an_iter.next()); assert_eq!(None, an_iter.next()); let mut an_iter = a.iter_mut(); // 转换成第二种迭代器 assert_eq!(Some(&mut 1), an_iter.next()); assert_eq!(Some(&mut 2), an_iter.next()); assert_eq!(Some(&mut 3), an_iter.next()); assert_eq!(None, an_iter.next()); let mut an_iter = a.into_iter(); // 转换成第三种迭代器,并消耗掉a assert_eq!(Some(1), an_iter.next()); assert_eq!(Some(2), an_iter.next()); assert_eq!(Some(3), an_iter.next()); assert_eq!(None, an_iter.next()); println!("{:?}", a); }
你还可以与字符串数组进行对比加深理解。
fn main() { let mut a = ["1".to_string(), "2".to_string(), "3".to_string()]; let mut an_iter = a.iter(); assert_eq!(Some(&"1".to_string()), an_iter.next()); assert_eq!(Some(&"2".to_string()), an_iter.next()); assert_eq!(Some(&"3".to_string()), an_iter.next()); assert_eq!(None, an_iter.next()); let mut an_iter = a.iter_mut(); assert_eq!(Some(&mut "1".to_string()), an_iter.next()); assert_eq!(Some(&mut "2".to_string()), an_iter.next()); assert_eq!(Some(&mut "3".to_string()), an_iter.next()); assert_eq!(None, an_iter.next()); let mut an_iter = a.into_iter(); assert_eq!(Some("1".to_string()), an_iter.next()); assert_eq!(Some("2".to_string()), an_iter.next()); assert_eq!(Some("3".to_string()), an_iter.next()); assert_eq!(None, an_iter.next()); println!("{:?}", a); // 请你试试这一行有没有问题? }
对于整数数组 [1,2,3] 而言,调用 into_iter() 实际会复制一份这个数组,再将复制后的数组转换成迭代器,并消耗掉这个复制后的数组,因此最后的打印语句能把原来那个a打印出来。对于字符串数组 ["1".to_string(), "2".to_string(), "3".to_string()] 而言,调用 into_iter() 会直接消耗掉这个字符串数组,因此最后的打印语句不能把原来那个a打印出来。
为什么会有这个差异呢?你可以从我们 第 2 讲 所有权相关知识中找到答案。
for 语句的真面目
有了迭代器的背景知识后,我们终于要解开Rust语言里面for语句的真面目了。for语句是一种语法糖。语句 for item in c {} 会展开成下面这样:
let mut tmp_iter = c.into_iter();
while let Some(item) = tmp_iter.next() {}
也就是说,for语句默认使用获取元素所有权的迭代器模式,自动调用了 into_iter() 方法。因此,for语句会消耗集合 c。同时也说明,要将一个类型放在for语句里进行迭代,需要这个类型实现了迭代器 into_iter() 方法。
标准库中常见的 Range、Vec、HashMap、BtreeMap等都实现了 into_iter() 方法,因此它们可以放在for语句里进行迭代。
for语句作为一种基础语法,它会消耗掉原集合。有时候希望不获取原集合元素所有权,比如只是打印一下,这时只需要获取集合元素的引用 ,应该怎么办呢?
Rust中也考虑到了这种需求,提供了配套的辅助语法。
- 用
for in &c {}获取元素的不可变引用,相当于调用c.iter()。 - 用
for in &mut c {}获取元素的可变引用,相当于调用c.iter_mut()。
用这两种形式就不会消耗原集合所有权。
我们来看示例。
fn main() { let mut a = ["1".to_string(), "2".to_string(), "3".to_string()]; for item in &a { println!("{}", item); } for item in &mut a { println!("{}", item); } for item in a { // 请想一想为什么要把这一句放在后面 println!("{}", item); } // println!("{:?}", a); // 你可以试试把这一句打开 } // 输出 1 2 3 1 2 3 1 2 3
因为 into_iter() 会消耗集合所有权,因此在上面示例中我们把它放在最后去展示。
获取集合类型中元素的所有权
我们来看一个简单的例子,一般来说,我们想要获取Vec里的一个元素,只需要下标操作就可以了。
fn main() { let s1 = String::from("aaa"); let s2 = String::from("bbb"); let s3 = String::from("ccc"); let s4 = String::from("ddd"); let v = vec![s1, s2, s3, s4]; let a = v[0]; // 这里,我们想访问 s1 的内容 }
这段代码稀松平常,在Rust中却没办法编译通过。
error[E0507]: cannot move out of index of `Vec<String>`
--> src/main.rs:11:13
|
11 | let a = v[0];
| ^^^^ move occurs because value has type `String`, which does not implement the `Copy` trait
|
help: consider borrowing here
|
11 | let a = &v[0];
| +
提示不能从 Vec<String> 中用下标操作符移出元素。我们改一下代码。
fn main() {
let s1 = String::from("aaa");
let s2 = String::from("bbb");
let s3 = String::from("ccc");
let s4 = String::from("ddd");
let v = vec![s1, s2, s3, s4];
let a = &v[0]; // 明确a只获得v中第一个元素的引用
}
明确a只获得v中第一个元素的引用,这下可以编译通过了。这里,你可以顺便思考一下,对于 Vec<u32> 这种类型的动态数组,let a = v[0]; 这种代码可以编译通过吗?你可以立即动手测试一下。
在上面示例中,你可能为了从集合中获得 s1 的所有权,而不得不使用 let a = v[0].clone()。而根据我们这节课讲的迭代器知识,使用 into_iter() 就可以拿到并操作上述动态数组v中元素的所有权。
fn main() { let s1 = String::from("aaa"); let s2 = String::from("bbb"); let s3 = String::from("ccc"); let s4 = String::from("ddd"); let v = vec![s1, s2, s3, s4]; for s in v { // 这里,s拿到了集合元素的所有权 println!("{}", s); } }
这也体现了Rust对权限有相当细致的管理。对于下标索引这种不安全的操作,禁止获得集合元素所有权;对于迭代器这种安全的操作,允许它获得集合元素所有权。
小结
我们这节课详细探讨了Rust中的 Option<T> 和 Result<T, E> 的定义及常见操作。学习了如何以解包和不解包方式使用它们。内容比较细,风格可能也是你不太熟悉的。不过现在你只需要先了解这种代码风格,以后的项目实践中再慢慢掌握它们。
我们还介绍了迭代器的概念。迭代器的 next() 方法会返回一个 Option<Item> 类型。在所有权三态理论的指导下Rust中的迭代器也划分成了三种,可以通过不同的方法获取到集合元素的不可变引用、可变引用和所有权,这是Rust和其他语言的迭代器很不一样的地方。每种迭代器都有各自适用的场景,正确使用迭代器能提高代码的可靠性和可阅读性。
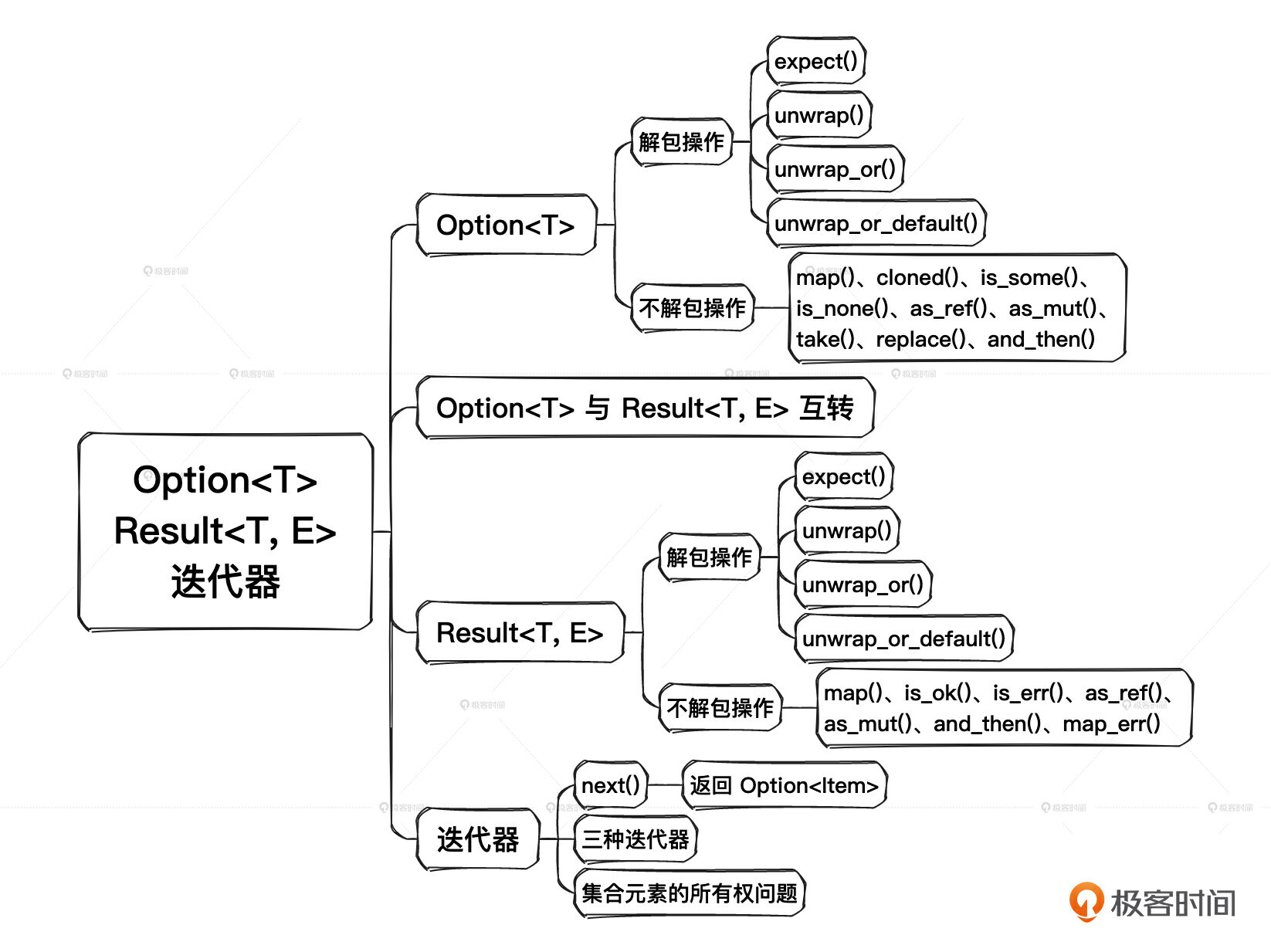
学习完这节课的内容之后,你应该能更深刻地感受到所有权概念在Rust语言中的支配地位。
思考题
你可以用同样的思路去研究一下,看看如何拿到 HashMap 中值的所有权。
https://doc.rust-lang.org/std/collections/struct.HashMap.html
欢迎你把你的成果展示在评论区,也欢迎你把这节课的内容分享给需要的朋友,邀他一起学习,我们下节课再见!
初识trait:协议约束与能力配置
你好,我是Mike。今天我们来一起学习trait。
trait 在Rust中非常重要。如果说所有权是Rust中的九阳神功(内功护体),那么类型系统(types + trait)就是Rust中的降龙十八掌,学好了便如摧枯拉朽般解决问题。另外一方面,如果把Rust比作一个AI人的话,那么所有权相当于Rust的心脏,类型 + trait相当于这个AI人的大脑。

好了,我就不卖关子了。前面我们已经学习了所有权,现在我们来了解一下这个trait到底是什么。
注:所有权是这门课程的主线,会一直贯穿到最后。
trait是什么?
trait用中文来讲就是特征,但是我倾向于不翻译。因为 trait 本身很简单,它就是一个标记(marker 或 tag)而已。比如 trait TraitA {} 就定义了一个trait,TraitA。
只不过这个标记被用在特定的地方,也就是类型参数的后面,用来限定(bound)这个类型参数可能的类型范围。所以trait往往是跟类型参数结合起来使用的。比如 T: TraitA 就是使用 TraitA 对类型参数T进行限制。
这么讲起来比较抽象,我们下面举例说明。
trait是一种约束
我们先回忆一下 第 7 讲 的一个例子。
struct Point<T> { x: T, y: T, } fn print<T: std::fmt::Display>(p: Point<T>) { println!("Point {}, {}", p.x, p.y); } fn main() { let p = Point {x: 10, y: 20}; print(p); let p = Point {x: 10.2, y: 20.4}; print(p); } // 输出 Point 10, 20 Point 10.2, 20.4
注意代码里的第六行。
fn print<T: std::fmt::Display>(p: Point<T>) {
这里的Display就是一个trait,用来对类型参数T进行约束。它表示 必须要实现了Display的类型才能被代入类型参数 T,也就是限定了 T 可能的类型范围。 std::fmt::Display 这个trait 主要是定义成配合格式化参数 "{}" 使用的,和它相对的还有 std::fmt::Debug,用来定义成配合格式化参数 "{:?}" 使用。而例子里的整数和浮点数,都默认实现了这个Display trait,因此整数和浮点数这两种类型能够代入函数 print() 的类型参数 T,从而执行打印的功能。
我们看一下如果一个类型没有实现Display,把它代入 print() 函数,会发生什么。
struct Point<T> { x: T, y: T, } struct Foo; // 新定义了一种类型 fn print<T: std::fmt::Display>(p: Point<T>) { println!("Point {}, {}", p.x, p.y); } fn main() { let p = Point {x: 10, y: 20}; print(p); let p = Point {x: 10.2, y: 20.4}; print(p); let p = Point {x: Foo, y: Foo}; // 初始化一个Point<T> 实例 print(p); }
报编译错误:
error[E0277]: `Foo` doesn't implement `std::fmt::Display`
--> src/main.rs:20:11
|
20 | print(p);
| ----- ^ `Foo` cannot be formatted with the default formatter
| |
| required by a bound introduced by this call
|
= help: the trait `std::fmt::Display` is not implemented for `Foo`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
提示说,Foo 类型没有实现 Display,所以没办法编译通过。
回顾一下我们前面 第 7 讲 里说到的:类型是对变量值空间的约束。结合trait是对类型参数类型空间的约束。我们可以整理出一张图来表达它们之间的关系。
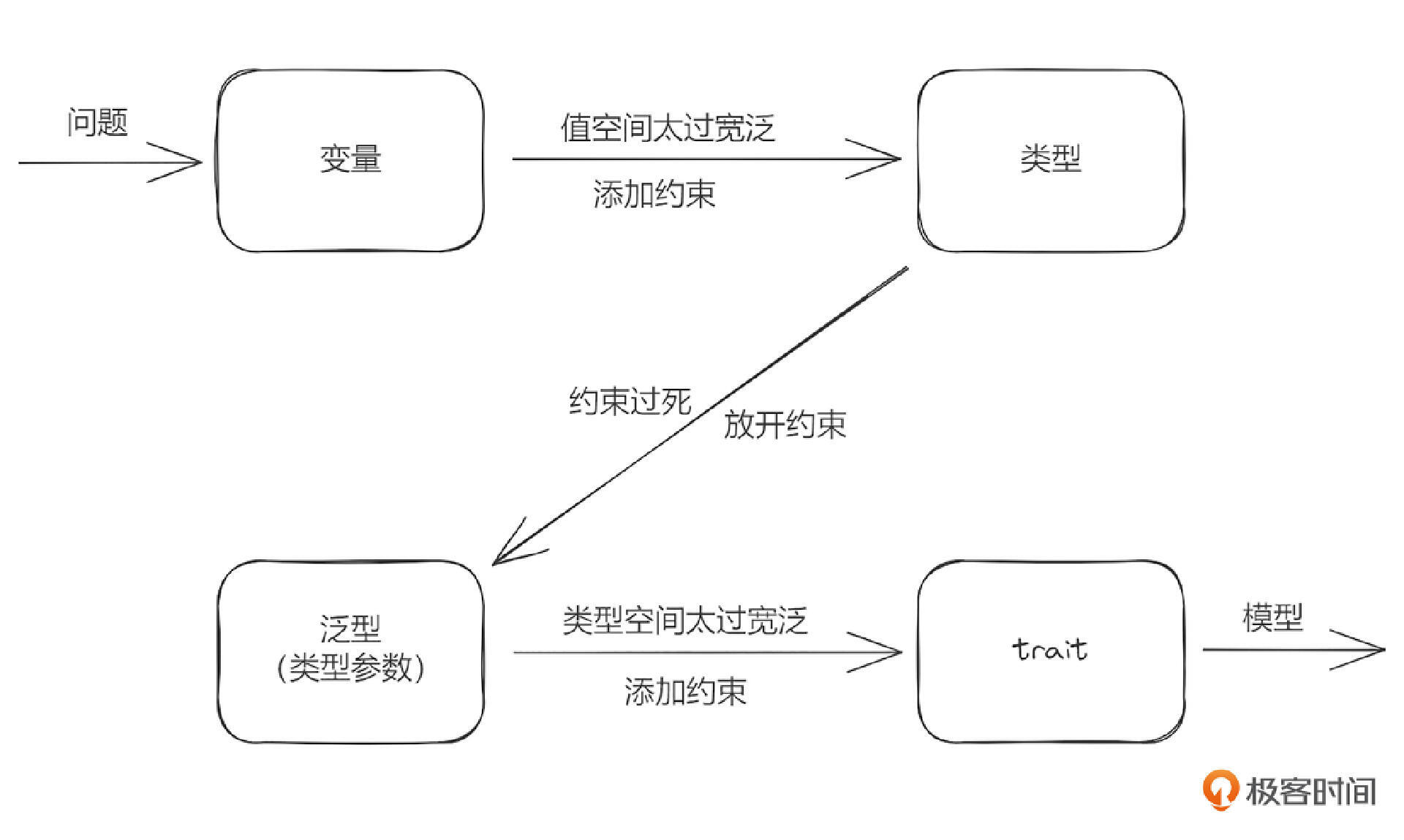
首先,如果我们定义一个变量,这个时候还没有给它指定类型。那么这个时候这个变量的取值空间就是任意的。由于值空间太过宽泛,我们给它指定类型,比如u32或字符串,给这个变量的值空间添加了约束。并且指定了明确的类型后, 这个变量的值空间就被限定为仅这一种类型的值空间。
对于简单的应用,到这一步也够了,但对抽象程度比较高的复杂应用,这种限定就显得太死了。所以又引入了类型参数(泛型)这个机制,用一个类型参数T就可以代表不同的类型。这样,以往为一些特定类型开发的函数等,就可以在不改变逻辑的情况下,扩展到支持多种类型,这样就灵活了很多。
但是,只有一个类型参数T,这个信息还不够,对同一个函数,可能只有少数一些类型适用,而符号 T 本身如果不加任何限制的话,它的内涵(类型空间)就太宽泛了,它可以取任意类型。所以光引入类型参数这个机制还不够,还得配套地引入一个对类型参数进行约束的机制。于是就出现了trait。结合图片,我们可以明白引入trait的原因和trait起的作用。
另一方面,从图片里其实也可以看出用Rust对问题建模的思维方式。当你在头脑中经过这样一个过程后,针对一个问题在Rust中就能建立起对应的模型来,整个过程非常自然。输入问题,输出模型!
语法上, T: TraitA 意思就是我们对类型参数T施加了TraitA这个约束标记。那么,我们怎么给某种具体的类型实现 TraitA,来让那个具体的类型可以代入T呢?具体来说,我们要对某个类型Atype实现某个trait的话,使用语法 impl TraitA for Atype {} 就可以做到。
只需要下面三行代码就可以。
trait TraitA {}
struct Atype;
impl TraitA for Atype {}
这三行代码是可以通过编译的,是不是有点吃惊?
对于某个类型 T (这里指的是某种具体的类型)来说,如果它实现了这个TraitA,我们就说这个类型 满足约束。
T: TraitA
一个trait在一个类型上只能被实现一次。比如:
trait TraitA {}
struct Atype;
impl TraitA for Atype {}
impl TraitA for Atype {}
// 输出,编译错误:
error[E0119]: conflicting implementations of trait `TraitA` for type `Atype`
例子也很好理解,约束声明一次就够了,多次声明就冲突了,不知道哪一个生效。
trait是一种能力配置
如果trait仅仅是一个纯标记名称,而不包含内容的话,那它的作用是非常有限的。
trait TraitA {}
下面我们会知道,这个{}里可以放入一些元素,这些元素属于这个trait。
我们先接着前面那个示例继续讲。
fn print<T: std::fmt::Display>(p: Point<T>) {
Display对类型参数T作了约束,要求将来要代入的具体类型必须实现了Display这个trait。另一方面,也可以说成,Display给将来要代入到这个类型参数里的具体类型提供了一套“能力”,这套能力是在 Display 这个trait中定义和封装的。具体来说,就是能够打印的能力,因为确实有些值是没法打印出来的,比如原始二进制编码,打出来也是乱码。而Display就提供了打印的能力,同时还定义了具体的打印要求。
注:Display是标准库提供的一种常用trait,我们会在第11讲专门讲解标准库里的各种常用trait。
也就是说, trait对类型参数实施约束的同时,也对具体的类型提供了能力。让我们看到类型参数后面的约束,就知道到时候代入这其中的类型会具有哪些能力。比如我们看到了 Display,就知道那些类型具有打印的能力。我们看到了 PartialEq,就知道那些类型具有比较大小的能力等等。
你也可以这样理解,在Rust中 约束和能力就是一体两面,是同一个东西。这样下面的写法是不是就好理解多了?
T: TraitA + TraitB + TraitC + TraitD
这个约束表达式,给某种类型T提供了从TraitA到TraitD这4套能力。我们后面还会看到,基于多trait组合的约束表达式,可以用这种方式提供优美的能力(权限)配置。
那么,一个trait里面具体可以有哪些东西呢?
trait中包含什么?
trait里面可以包含关联函数、关联类型和关联常量。
关联函数
在trait里可以定义关联函数。比如下面Sport这个trait就定义了四个关联函数。
trait Sport {
fn play(&self); // 注意这里直接以分号结尾,表示函数签名
fn play_mut(&mut self);
fn play_own(self);
fn play_some() -> Self;
}
例子里,前3个关联函数都带有Self参数(⚠️ 所有权三态又出现了),它们被实现到具体类型上的时候,就成为那个具体类型的方法。第4个方法, play_some() 函数里第一个参数不是Self类型,也就是说,它不是self、&self、&mut self中的一个,它被实现在具体类型上的时候,就是那个类型的关联函数。
可以看到,在trait中可以使用Rust语言里的标准类型Self,用来指代将要被实现这个trait的那个类型。使用 impl 语法将一个 trait 实现到目标类型上去。
你可以看一下示例。
struct Football;
impl Sport for Football {
fn play(&self) {} // 注意函数后面的花括号,表示实现
fn play_mut(&mut self) {}
fn play_own(self) {}
fn play_some() -> Self { Self }
}
这里这个Self,就指代 Football 这个类型。
trait中也可以定义关联函数的默认实现。
比如:
trait Sport {
fn play(&self) {} // 注意这里一对花括号,就是trait的关联函数的默认实现
fn play_mut(&mut self) {}
fn play_own(self); // 注意这里是以分号结尾,就表示没有默认实现
fn play_some() -> Self;
}
在这个示例里, play() 和 play_mut() 后面定义了函数体,因此实际上提供了默认实现。
有了trait关联函数的默认实现后,具体类型在实现这个trait的时候,就可以“偷懒”,直接利用默认实现。比如:
struct Football;
impl Sport for Football {
fn play_own(self) {}
fn play_some() -> Self { Self }
}
这个跟下面这个例子效果是一样的。
struct Football;
impl Sport for Football {
fn play(&self) {}
fn play_mut(&mut self) {}
fn play_own(self) {}
fn play_some() -> Self { Self }
}
上面的代码相当于 Football 类型重新实现了一次 play() 和 play_mut() 函数,覆盖了trait的这两个函数的默认实现。
在类型上实现了trait后就可以使用这些方法了。
fn main () {
let mut f = Football;
f.play(); // 方法在实例上调用
f.play_mut();
f.play_own();
let _g = Football::play_some(); // 关联函数要在类型上调用
let _g = <Football as Sport>::play_some(); // 注意这样也是可以的
}
关联类型
在trait中,可以带一个或多个关联类型。关联类型起一种类型占位功能,定义trait时声明,在把trait实现到类型上的时候为其指定具体的类型。比如:
pub trait Sport { type SportType; fn play(&self, st: Self::SportType); } struct Football; pub enum SportType { Land, Water, } impl Sport for Football { type SportType = SportType; // 这里故意取相同的名字,不同的名字也是可以的 fn play(&self, st: Self::SportType){} // 方法中用到了关联类型 } fn main() { let f = Football; f.play(SportType::Land); }
解释一下,我们在给Football类型实现Sport trait的时候,指明具体的关联类型SportType为一个枚举类型,用来区分陆地运动与水上运动。注意看trait中的play方法的第二个参数,它就是用的关联类型占位。
在 T 上使用关联类型
我们再来看一个示例,标准库中迭代器 Iterator trait的定义。
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
Iterator定义了一个关联类型Item。注意这里的 Self::Item 实际是 <Self as Iterator>::Item 的简写。一般来说,如果一个类型参数被TraitA约束,而TraitA里有关联类型 MyType,那么可以用 T::Mytype 这种形式来表示路由到这个关联类型。
比如:
trait TraitA { type Mytype; } fn doit<T: TraitA>(a: T::Mytype) {} // 这里在函数中使用了关联类型 struct TypeA; impl TraitA for TypeA { type Mytype = String; // 具化关联类型为String } fn main() { doit::<TypeA>("abc".to_string()); // 给Rustc小助手喂信息:T具化为TypeA }
上面示例在 doit() 函数中使用了TraitA中的关联类型,用的是 T::Mytype 这种路由/路径形式。在 main() 函数中调用 doit() 函数时,手动把类型参数T具化为TypeA。你可以多花一些时间熟悉一下这种表达形式。
在约束中具化关联类型
在指定约束的时候,可以把关联类型具化。你可以看一下我给出的示例。
trait TraitA { type Item; } struct Foo<T: TraitA<Item=String>> { // 这里在约束表达式中对关联类型做了具化 x: T } struct A; impl TraitA for A { type Item = String; } fn main() { let a = Foo { x: A, }; }
上面的代码在约束表达式中对关联类型做了具化,具化为 String 类型。
T: TraitA<Item=String>
这样表达的意思就是限制必须实现了TraitA,而且它的关联类型必须是String才能代入这个T。假如我们稍微改一下,把类型A实现TraitA 时的关联类型Item具化为u32,就会编译报错,你可以试着编译一下看下提示。
trait TraitA { type Item; } struct Foo<T: TraitA<Item=String>> { x: T } struct A; impl TraitA for A { type Item = u32; // 这里类型不匹配 } fn main() { let a = Foo { x: A, // 报错 }; }
慢慢地我们给的示例有些烧脑了,现在你并不需要精通这些用法, 第一步是要认识它们,当你看到别人写这种代码的时候,能基本看懂就可以了。
对关联类型的约束
在定义关联类型的时候,也可以给关联类型添加约束。意思是后面在具化这个类型的时候,那些类型必须要满足于这些约束,或者说实现过这些约束。你可以看我给出的这个例子。
use std::fmt::Debug;
trait TraitA {
type Item: Debug; // 这里对关联类型添加了Debug约束
}
#[derive(Debug)] // 这里在类型A上自动derive Debug约束
struct A;
struct B;
impl TraitA for B {
type Item = A; // 这里这个类型A已满足Debug约束
}
在使用时甚至可以加强对关联类型的约束。比如:
use std::fmt::Debug;
trait TraitA {
type Item: Debug; // 这里对关联类型添加了Debug约束
}
#[derive(Debug)]
struct A;
struct B;
impl TraitA for B {
type Item = A; // 这里这个类型A已满足Debug约束
}
fn doit<T>() // 定义类型参数T
where
T: TraitA, // 使用where语句将T的约束表达放在后面来
T::Item: Debug + PartialEq // 注意这一句,直接对TraitA的关联类型Item添加了更多一个约束 PartialEq
{
}
请注意上面例子里的 doit() 函数。我们使用where语句把类型参数T的约束表达放在后面,同时使用 T::Item: Debug + PartialEq 来加强对 TraitA的关联类型Item 的约束,表示只有实现过 TraitA 且其关联类型 Item 的具化版必须满足 Debug 和 PartialEq 的约束。
这个例子稍微有点复杂,不过理解后,你会感觉到Rust trait的精髓。目前你可以把这个示例当作思维体操来练一练,没事了回来细品一下。另外,你可以自己修改这个例子,看看Rustc小助手会告诉你什么。
关联常量
同样的,trait里也可以携带一些常量信息,表示这个trait的一些内在信息(挂载在trait上的信息)。和关联类型不同的是,关联常量可以在trait定义的时候指定,也可以在给具体的类型实现的时候指定。
你可以看一下这个例子。
trait TraitA { const LEN: u32 = 10; } struct A; impl TraitA for A { const LEN: u32 = 12; } fn main() { println!("{:?}",A::LEN); println!("{:?}",<A as TraitA>::LEN); } //输出 12 12
如果在impl的时候不指定,会有什么效果呢?你可以看看代码运行后的结果。
trait TraitA { const LEN: u32 = 10; } struct A; impl TraitA for A {} fn main() { println!("{:?}",A::LEN); println!("{:?}",<A as TraitA>::LEN); } //输出 10 10
trait 作为一种协议
我们已经看到,trait里有可选的关联函数、关联类型、关联常量这三项内容。一旦trait定义好,它就相当于一条法律或协议,在实现它的各个类型之间,在团队协作中不同的开发者之间,都必须按照它定义的规范实施。这是 强制性 的,而且这种强制性是由Rust编译器来执行的。也就是说, 如果你不想按这套协议来实施,那么你注定无法编译通过。
这个对于团队开发来说非常重要。它相当于在团队中协调的接口协议,强制不同成员之间达成一致。 从这个意义上来讲,Rust非常适合团队开发。
Where
当类型参数后面有多个trait约束的时候,会显得“头重脚轻”,比较难看,所以Rust提供了Where语法来解决这个问题。Where关键字可用来把约束关系统一放在后面表示。
比如这个函数:
fn doit<T: TraitA + TraitB + TraitC + TraitD + TraitE>(t: T) -> i32 {}
这行代码可以写成下面这种形式。
fn doit<T>(t: T) -> i32
where
T: TraitA + TraitB + TraitC + TraitD + TraitE
{}
这样过多的trait约束就不至于太干扰函数签名的视觉完整性。
约束依赖
Rust还提供了一种语法表示约束间的依赖。
trait TraitA: TraitB {}
初看起来,这跟C++等语言的类的继承有点像。实际不是,差异很大。 这个语法的意思是如果某种类型要实现TraitA,那么它也要同时实现TraitB。反过来不成立。
例子:
trait Shape { fn area(&self) -> f64; }
trait Circle : Shape { fn radius(&self) -> f64; }
上面这两行代码其实等价于下面这两行代码。
trait Shape { fn area(&self) -> f64; }
trait Circle where Self: Shape { fn radius(&self) -> f64; }
你也可以看一下使用时的约束表示。
T: Circle
实际上表示:
T: Circle + Shape
在这个约束依赖的限定下,如果你对一个类型实现了Circle trait,却没有实现Shape,那么Rust小助手会提示你这个类型不满足约束Shape。
比如下面代码:
trait Shape {}
trait Circle : Shape {}
struct A;
struct B;
impl Shape for A {}
impl Circle for A {}
impl Circle for B {}
提示出错:
error[E0277]: the trait bound `B: Shape` is not satisfied
--> src/main.rs:7:17
|
7 | impl Circle for B {}
| ^ the trait `Shape` is not implemented for `B`
|
= help: the trait `Shape` is implemented for `A`
note: required by a bound in `Circle`
--> src/main.rs:2:16
|
2 | trait Circle : Shape {}
| ^^^^^ required by this bound in `Circle`
一个trait依赖多个trait也是可以的。
trait TraitA: TraitB + TraitC {}
这个例子里面, T: TraitA 实际表 T: TraitA + TraitB + TraitC。因此可以少写不少代码。
约束之间是完全平等的,理解这一点非常重要,通过刚刚的这些例子可以看到约束依赖是消除约束条件冗余的一种方式。
在约束依赖中,冒号后面的叫 supertrait,冒号前面的叫 subtrait。可以理解为subtrait在supertrait的约束之上,又多了一套新的约束。这些不同约束的地位是平等的。
约束中同名方法的访问
有的时候多个约束上会定义同名方法,像下面这样:
trait Shape { fn play(&self) { // 定义了play()方法 println!("1"); } } trait Circle : Shape { fn play(&self) { // 也定义了play()方法 println!("2"); } } struct A; impl Shape for A {} impl Circle for A {} impl A { fn play(&self) { // 又直接在A上实现了play()方法 println!("3"); } } fn main() { let a = A; a.play(); // 调用类型A上实现的play()方法 <A as Circle>::play(&a); // 调用trait Circle上定义的play()方法 <A as Shape>::play(&a); // 调用trait Shape上定义的play()方法 } //输出 3 2 1
上面示例展示了两个不同的trait定义同名方法,以及在类型自身上再定义同名方法,然后是如何精准地调用到不同的实现的。可以看到,在Rust中,同名方法没有被覆盖,能精准地路由过去。
<A as Circle>::play(&a); 这种语法,叫做 完全限定语法,是调用类型上某一个方法的完整路径表达。如果impl和impl trait时有同名方法,用这个语法就可以明确区分出来。
用trait实现能力配置
trait提供了寻找方法的范围
Rust在一个实例上是怎么检查有没有某个方法的呢?
- 检查有没有直接在这个类型上实现这个方法。
- 检查有没有在这个类型上实现某个trait,trait中有这个方法。
一个类型可能实现了多个trait,不同的trait中各有一套方法,这些不同的方法中可能还会出现同名方法。Rust在这里采用了一种惰性的机制,由开发者指定在当前的mod或scope中使用哪套或哪几套能力。因此,对应地需要开发者手动地将要用到的trait引入当前scope。
比如下面这个例子,我们定义两个隔离的模块,并在module_b里引入module_a中定义的类型A。
mod module_a {
pub trait Shape {
fn play(&self) {
println!("1");
}
}
pub struct A;
impl Shape for A {}
}
mod module_b {
use super::module_a::A; // 这里只引入了另一个模块中的类型
fn doit() {
let a = A;
a.play();
}
}
报错了,怎么办呢?
error[E0599]: no method named `play` found for struct `A` in the current scope
--> src/lib.rs:17:11
|
3 | fn play(&self) {
| ---- the method is available for `A` here
...
8 | pub struct A;
| ------------ method `play` not found for this struct
...
17 | a.play();
| ^^^^ method not found in `A`
|
= help: items from traits can only be used if the trait is in scope
help: the following trait is implemented but not in scope; perhaps add a `use` for it:
|
13 + use crate::module_a::Shape;
引入trait就可以了。
mod module_a {
pub trait Shape {
fn play(&self) {
println!("1");
}
}
pub struct A;
impl Shape for A {}
}
mod module_b {
use super::module_a::Shape; // 引入这个trait
use super::module_a::A;
fn doit() {
let a = A;
a.play();
}
}
也就是说,在当前mod不引入对应的trait,你就得不到相应的能力。因此 Rust 的trait需要引入当前scope才能使用的方式可以看作是能力配置(Capability Configuration)机制。
约束可按需配置
有了trait这种能力配置机制,我们可以在需要的地方按需加载能力。需要什么能力就引入什么能力(提供对应的约束)。不需要一次性限制过死,比如下面的示例就演示了几种约束组合的可能性。
trait TraitA {} trait TraitB {} trait TraitC {} struct A; struct B; struct C; impl TraitA for A {} impl TraitB for A {} impl TraitC for A {} // 对类型A实现了TraitA, TraitB, TraitC impl TraitB for B {} impl TraitC for B {} // 对类型B实现了TraitB, TraitC impl TraitC for C {} // 对类型C实现了TraitC // 7个版本的doit() 函数 fn doit1<T: TraitA + TraitB + TraitC>(t: T) {} fn doit2<T: TraitA + TraitB>(t: T) {} fn doit3<T: TraitA + TraitC>(t: T) {} fn doit4<T: TraitB + TraitC>(t: T) {} fn doit5<T: TraitA>(t: T) {} fn doit6<T: TraitB>(t: T) {} fn doit7<T: TraitC>(t: T) {} fn main() { doit1(A); doit2(A); doit3(A); doit4(A); doit5(A); doit6(A); doit7(A); // A的实例能用在所有7个函数版本中 doit4(B); doit6(B); doit7(B); // B的实例只能用在3个函数版本中 doit7(C); // C的实例只能用在1个函数版本中 }
示例里,A的实例能用在全部的(7个)函数版本中,B的实例只能用在3个函数版本中,C的实例只能用在1个函数版本中。
我们再来看一个示例,这个示例演示了如何对带类型参数的结构体在实现方法的时候,按需求施加约束。
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> { // 第一次 impl
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> { // 第二次 impl
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}
这个示例中,我们对类型 Pair<T> 做了两次impl。可以看到,第二次impl时,添加了约束 T: Display + PartialOrd。
因为我们cmd_display方法需要用到打印能力和元素比大小排序的能力,所以对类型参数T施加了 Display 和 PartialOrd两种约束(两种能力)。而对于new函数来说,它不需要这些能力,因此impl的时候就可以不施加这些约束。我们前面讲过,Rust中对类型是可以多次impl的。
关于trait,你还要了解什么?
孤儿规则
为了不导致混乱,Rust要求在一个模块中,如果要对一个类型实现某个trait,这个类型和这个trait其中必须有一个是在当前模块中定义的。比如下面这两种情况都是可以的。
情况1:
use std::fmt::Display;
struct A;
impl Display for A {}
情况2:
trait TraitA {}
impl TraitA for u32 {}
但是下面这样不可以,会编译报错。
use std::fmt::Display;
impl Display for u32 {}
error[E0117]: only traits defined in the current crate can be implemented for primitive types
--> src/lib.rs:3:1
|
3 | impl Display for u32 {}
| ^^^^^^^^^^^^^^^^^---
| | |
| | `u32` is not defined in the current crate
| impl doesn't use only types from inside the current crate
|
= note: define and implement a trait or new type instead
因为我们想给一个外部类型实现一个外部trait,这是不允许的。Rustc小助手提示我们,如果实在想用的话,可以用Newtype模式。
比如像下面这样:
use std::fmt::Display;
struct MyU32(u32); // 用 MyU32 代替 u32
impl Display for MyU32 {
// 请实现完整
}
impl MyU32 {
fn get(&self) -> u32 { // 需要定义一个获取真实数据的方法
self.0
}
}
Blanket Implementation
Blanket Implementation又叫做统一实现。
方式如下:
trait TraitA {}
trait TraitB {}
impl<T: TraitB> TraitA for T {} // 这里直接对T进行实现TraitA
统一实现后,就不要对某个具体的类型再实现一次了。因为同一个trait只能实现一次到某个类型上。这个不像是对类型做 impl,可以实现多次(函数名要不冲突)。
比如:
trait TraitA {}
trait TraitB {}
impl<T: TraitB> TraitA for T {}
impl TraitB for u32 {}
impl TraitA for u32 {}
这样就会报错。
error[E0119]: conflicting implementations of trait `TraitA` for type `u32`
--> src/lib.rs:10:1
|
6 | impl<T: TraitB> TraitA for T {}
| ---------------------------- first implementation here
...
10 | impl TraitA for u32 {}
| ^^^^^^^^^^^^^^^^^^^ conflicting implementation for `u32`
我们修改一下,这样就不会报错了。
trait TraitA {}
trait TraitB {}
impl<T: TraitB> TraitA for T {}
impl TraitA for u32 {}
因为u32并没有被TraitB约束,所以它不满足第4行的blanket implementation。因此就不算重复实现。
小结
认真学完了这节课的内容之后,你有没有被震撼到?这完全就是一种全新的思维体系,和之前我们熟悉的OOP等方式完全不同了。Rust中trait的概念本身非常简单,但用法又极其灵活。
trait的引入是为了对泛型的类型空间进行约束,进入约束的同时也就提供了能力,约束与能力是一体两面。trait中可以包含关联函数、关联类型和关联常量。其中关联类型的理解难度较大,但是其模式也就那么固定的几种,多花点时间熟悉一般不会有问题。
trait定义好后,可以作为代码与代码之间、代码与开发者之间、开发者与开发者之间的强制性法律协议而存在,而这个法律的仲裁者就是Rustc编译器。
可以说, Rust是一门面向约束编程的语言。面向约束是Rust中非常独特的设计,也是Rust的灵魂。简单地把trait当作其他语言中的class或interface去理解使用,是非常有害的。
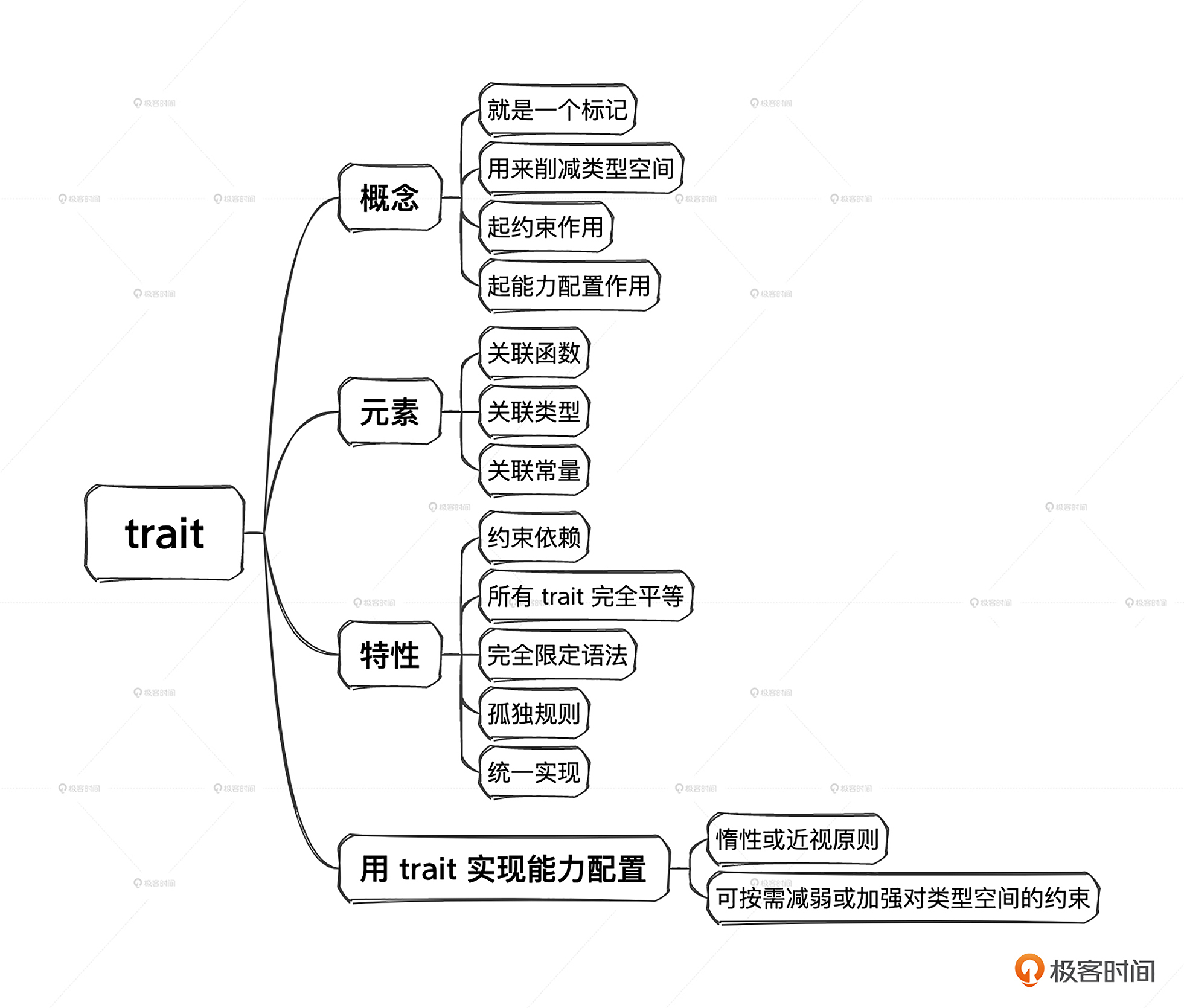
思考题
如果你学习或者了解过Java、C++等面向对象语言的话,可以聊一聊trait的依赖和OOP继承的区别在哪里。
欢迎你把思考后的结果分享到评论区,也欢迎你把这节课的内容分享给对Rust感兴趣的朋友,我们下节课再见!
再探trait:带类型参数的trait及trait object
你好,我是Mike,今天我们继续学习trait相关知识。
回顾一下我们上一节课中类型参数出现的地方。
- 用 trait 对 T 作类型空间的约束,比如
T: TraitA。 - blanket implementation 时的 T,比如
impl<T: TraitB> TraitA for T {}。 - 函数里的 T 参数,比如
fn doit<T>(a: T) {}。
你要注意区分不同位置的 T。它的基础意义都是类型参数,但是放在不同的位置其侧重的意义有所不同。
T: TraitA里的T表示类型参数,强调“参数”,使用TraitA来削减它的类型空间。impl<T: TraitB> TraitA for T {}末尾的T更强调类型参数的“类型”部分,为某些类型实现 TraitA。doit<T>(a: T) {}中第二个T表示某种类型,更强调类型参数的“类型”部分。
这节课我们要讲的是另外一个东西,它里面也带T参数。我们一起来看一下,它与之前这几种形式有什么不同。
trait上带类型参数
trait上也是可以带类型参数的,形式像下面这样:
trait TraitA<T> {}
表示这个trait里面的函数或方法,可能会用到这个类型参数。在定义trait的时候,还没确定这个类型参数的具体类型。要等到impl甚至使用类型方法的时候,才会具体化这个T的具体类型。
注意,这个时候 TraitA<T> 是一个整体,表示一个trait。比如 TraitA<u8> 和 TraitA<u32> 就是两个不同的trait,这里单独把TraitA拿出来说是没有意义的。
实现时需要在impl后面先定义类型参数,比如:
impl<T> TraitA<T> for Atype {}
当然也可以在对类型实现时,将T参数具体化,比如:
impl TraitA<u8> for Atype {}
而如果被实现的类型上自身也带类型参数,那么情况会更复杂。
trait TraitA<T> {}
struct Atype<U> {
a: U,
}
impl<T, U> TraitA<T> for Atype<U> {}
这些类型参数都是可以在impl时被约束的,像下面这样:
use std::fmt::Debug;
trait TraitA<T> {}
struct Atype<U> {
a: U,
}
impl<T, U> TraitA<T> for Atype<U>
where
T: Debug, // 在 impl 时添加了约束
U: PartialEq, // 在 impl 时添加了约束
{}
注:以上代码都是可以放到playground中编译通过的。
impl 示例
下面我们通过一个具体的实例体会一下带类型参数的trait的威力。
我们现在要实现一个模型。
- 平面上的一个点与平面上的另一个点相加,形成一个新的点。算法是两个点的x分量和y分量分别相加。
- 平面上的一个点加一个整数i32,形成一个新的点。算法是分别在x分量和y分量上面加这个i32参数。
代码如下:
// 定义一个带类型参数的trait trait Add<T> { type Output; fn add(self, rhs: T) -> Self::Output; } struct Point { x: i32, y: i32, } // 为 Point 实现 Add<Point> 这个 trait impl Add<Point> for Point { type Output = Self; fn add(self, rhs: Point) -> Self::Output { Point { x: self.x + rhs.x, y: self.y + rhs.y, } } } // 为 Point 实现 Add<i32> 这个 trait impl Add<i32> for Point { type Output = Self; fn add(self, rhs: i32) -> Self::Output { Point { x: self.x + rhs, y: self.y + rhs, } } } fn main() { let p1 = Point { x: 1, y: 1 }; let p2 = Point { x: 2, y: 2 }; let p3 = p1.add(p2); // 两个Point实例相加 assert_eq!(p3.x, 3); assert_eq!(p3.y, 3); let p1 = Point { x: 1, y: 1 }; let delta = 2; let p3 = p1.add(delta); // 一个Point实例加一个i32 assert_eq!(p3.x, 3); assert_eq!(p3.y, 3); }
我们详细解释一下这个示例。 Add<T> 这个trait,带一个类型参数T,还带一个关联类型 Output。
对Point类型,我们实现了两个trait: Add<Point> 和 Add<i32>。注意这已经是两个不同的trait了,所以能对同一个类型实现。前面我们反复强调过,同一个trait只能对一个类型实现一次。
根据需求,运算后的类型也是Point,所以看到两个trait中的关联类型都是 Self。请注意两个trait中实现的不同算法。
通过这种形式,我们在同一个类型上实现了同名方法(add方法)参数类型的多种形态。在这里看起来就是,Point实例的add方法既可以接收Point参数,又可以接收i32参数,Rustc小助手可以根据不同的参数类型自动找到对应的方法调用。在Java、C++这些语言中,有语言层面的函数重载特性来支持这种功能,Rust中自身并不直接支持函数重载特性,但是它用trait就轻松实现了同样的效果,这是一种全新的思路。
trait 类型参数的默认实现
定义带类型参数的trait的时候,可以为类型参数指定一个默认类型,比如 trait TraitA<T = u64> {}。这样使用时, impl TraitA for SomeType {} 就等价于 impl TraitA<u64> for SomeType {}。
我们来看一个完整的例子。
// Self可以用在默认类型位置上
trait TraitA<T = Self> {
fn func(t: T) {}
}
// 这个默认类型为i32
trait TraitB<T = i32> {
fn func2(t: T) {}
}
struct SomeType;
// 这里省略了类型参数,所以这里的T为Self
// 进而T就是SomeType本身
impl TraitA for SomeType {
fn func(t: SomeType) {}
}
// 这里省略了类型参数,使用默认类型i32
impl TraitB for SomeType {
fn func2(t: i32) {}
}
// 这里不省略类型参数,明确指定类型参数为String
impl TraitA<String> for SomeType {
fn func(t: String) {}
}
// 这里不省略类型参数,明确指定类型参数为String
impl TraitB<String> for SomeType {
fn func2(t: String) {}
}
默认参数给表达上带来了一定程度的简洁,但是增加了初学者识别和理解上的困难。
你还记得上一节课讲关联类型时我们提到过在使用约束时可以具化关联类型。那里也是用的=号。比如:
trait TraitA {
type Item;
}
// 这里,定义结构体类型时,用到了TraitA作为约束
struct Foo<T: TraitA<Item=String>> {
x: T
}
初看这里容易混淆。区别在于, 关联类型的具化是在应用约束时,类型参数的默认类型指定是在定义trait时,通过trait出现的场景可以区分它们。
trait中的类型参数与关联类型的区别
现在你可能会有些疑惑:trait上的类型参数和关联类型都具有延迟具化的特点,那么它们的区别是什么呢?为什么要设计两种不同的机制呢?
首先要明确的一点是,Rust本身也在持续演化过程中。有些特性先出现,有些特性是后出现的。最后演化出功能相似但是不完全一样的特性是完全有可能的。
具体到这两者来说,它们主要有两点不同。
- 类型参数可以在impl 类型的时候具化,也可以延迟到使用的时候具化。而关联类型在被impl时就必须具化。
- 由于类型参数和trait名一起组成了完整的trait名字,不同的具化类型会构成不同的trait,所以看起来同一个定义可以在目标类型上实现“多次”。而关联类型没有这个作用。
下面我们分别举例说明。
对于第一点,请看下面的示例:
use std::fmt::Debug; trait TraitA<T> where T: Debug, // 定义TraitA<T>的时候,对T作了约束 { fn play(&self, _t: T) {} } struct Atype; impl<T> TraitA<T> for Atype where T: Debug + PartialEq, // 将TraitA<T>实现到类型Atype上时,加强了约束 {} fn main() { let a = Atype; a.play(10u32); // 在使用时,通过实例方法传入的参数类型具化T }
这个示例展示了几个要点。
- 定义带类型参数的trait时可以用where表达,并提供约束。
- impl trait时可以对类型参数加强约束,对应例子中的 Debug + PartialEq。
- impl trait时可以不具化类型参数。
- 可以在使用方法时具化类型参数。例子里的
a.play(10u32),把T具象化成了u32。
当然,在impl的时候也可以指定成u32类型,所以下面的代码也可以。
use std::fmt::Debug; trait TraitA<T> where T: Debug, { fn play(&self, _t: T) {} } struct Atype; impl TraitA<u32> for Atype {} // 这里具化成了 TraitA<u32> fn main() { let a = Atype; a.play(10u32); }
但是这样就没前面那么灵活了,比如 a.play(10u64) 就不行了。
对应的,对关联类型来说,如果你在impl时不对其具化,就无法编译通过。所以对于第二点,我也给出一个例子来解释。我们把前面对Point类型实现Add的模型尝试用关联类型实现一遍。
trait Add { type ToAdd; // 多定义一个关联类型 type Output; fn add(self, rhs: Self::ToAdd) -> Self::Output; } struct Point { x: i32, y: i32, } impl Add for Point { type ToAdd = Point; type Output = Point; fn add(self, rhs: Point) -> Point { Point { x: self.x + rhs.x, y: self.y + rhs.y, } } } impl Add for Point { // 这里重复impl了同一个trait,无法编译通过 type ToAdd = i32; type Output = Point; fn add(self, rhs: i32) -> Point { Point { x: self.x + rhs, y: self.y + rhs, } } } fn main() { let p1 = Point { x: 1, y: 1 }; let p2 = Point { x: 2, y: 2 }; let p3 = p1.add(p2); assert_eq!(p3.x, 3); assert_eq!(p3.y, 3); let p1 = Point { x: 1, y: 1 }; let delta = 2; let p3 = p1.add(delta); // 这句是错的 assert_eq!(p3.x, 3); assert_eq!(p3.y, 3);
编译器会抱怨:
error[E0119]: conflicting implementations of trait `Add` for type `Point`:
--> src/main.rs:23:1
|
12 | impl Add for Point {
| ------------------ first implementation here
...
23 | impl Add for Point {
| ^^^^^^^^^^^^^^^^^^ conflicting implementation for `Point`
提示说,对Point类型实现了多次Add,导致冲突。编译不通过。所以这个模型仅用关联类型来实现,是写不出来的。
这么看起来,好像带类型参数的trait功能更强大,那用这个不就够了?但关联类型也有它的优点,比如关联类型没有类型参数,不存在多引入了一个参数的问题,而类型参数是具有传染性的,特别是在一个调用层次很深的系统中,增删一个类型参数可能会导致整个项目文件到处都需要改,非常头疼。
而关联类型没有这个问题。在一些场合下,关联类型正好是减少类型参数数量的一种方法。更不要说,有时模型比较简单,不需要多态特性,这时用关联类型就更简洁,代码可读性更好。
trait object
下面我们开始讲trait object。
我们从一个函数要返回不同的类型说起。比如一个常见的需求,要在一个Rust函数中返回可能的多种类型,应该怎么写?
如果我们写成返回固定类型的函数签名,那么它就只能返回那个类型。比如:
struct Atype;
struct Btype;
struct Ctype;
fn doit() -> Atype {
let a = Atype;
a
}
你想到的第一个办法可能是利用enum。
struct Atype;
struct Btype;
struct Ctype;
enum TotalType {
A(Atype), // 用变体把目标类型包起来
B(Btype),
C(Ctype),
}
fn doit(i: u32) -> TotalType { // 返回枚举类型
if i == 0 {
let a = Atype;
TotalType::A(a) // 在这个分支中返回变体A
} else if i == 1 {
let b = Btype;
TotalType::B(b) // 在这个分支中返回变体B
} else {
let c = Ctype;
TotalType::C(c) // 在这个分支中返回变体C
}
}
enum 常用于聚合类型。这些类型之间可以没有任何关系,用enum可以 无脑+强行 把它们揉在一起。enum聚合类型是编码时已知的类型,也就是说在聚合前,需要知道待聚合类型的边界,一旦定义完成,之后运行时就不能改动了,它是 封闭类型集。
第二种办法是利用类型参数,我们试着引入一个类型参数,改写一下。
struct Atype;
struct Btype;
struct Ctype;
fn doit<T>() -> T {
let a = Atype;
a
}
很明显,这种代码无法通过编译。提示:
error[E0308]: mismatched types
--> src/lib.rs:6:3
|
4 | fn doit<T>() -> T {
| - - expected `T` because of return type
| |
| this type parameter
5 | let a = Atype;
6 | a
| ^ expected type parameter `T`, found `Atype`
|
= note: expected type parameter `T`
found struct `Atype`
因为这里这个类型参数T是在这个函数调用时指定,而不是在这个函数定义时指定的。所以针对我们的需求,你没法在这里直接返回一个具体的类型代入T。只能尝试用T来返回,于是我们改出第二个版本。
struct Atype;
struct Btype;
struct Ctype;
impl Atype {
fn new() -> Atype {
Atype
}
}
impl Btype {
fn new() -> Btype {
Btype
}
}
impl Ctype {
fn new() -> Ctype {
Ctype
}
}
fn doit<T>() -> T {
T::new()
}
编译还是报错。
error[E0599]: no function or associated item named `new` found for type parameter `T` in the current scope
--> src/main.rs:24:6
|
23 | fn doit<T>() -> T {
| - function or associated item `new` not found for this type parameter
24 | T::new()
| ^^^ function or associated item not found in `T`
也就是说,Rustc小助手并不知道我们定义这个类型参数T里面有new这个关联函数。联想到我们前面学过的,可以用trait来定义这个协议,让Rust认识它。
第三个版本:
struct Atype; struct Btype; struct Ctype; trait TraitA { fn new() -> Self; // TraitA中定义了new()函数 } impl TraitA for Atype { fn new() -> Atype { Atype } } impl TraitA for Btype { fn new() -> Btype { Btype } } impl TraitA for Ctype { fn new() -> Ctype { Ctype } } fn doit<T: TraitA>() -> T { T::new() } fn main() { let a: Atype = doit::<Atype>(); let b: Btype = doit::<Btype>(); let c: Ctype = doit::<Ctype>(); }
这个版本顺利通过编译。在这个示例中,我们认识到了引入trait的必要性,就是让Rustc小助手知道我们在协议层面有一个new()函数,一旦类型参数被trait约束后,它就可以去trait中寻找协议定义的函数和方法。
为了解决上面那个问题,我们真的是费了不少力气。实际上,Rust提供了更优雅的方案来解决这个需求。Rust利用trait提供了一种特殊语法 impl trait,你可以看一下示例。
struct Atype;
struct Btype;
struct Ctype;
trait TraitA {}
impl TraitA for Atype {}
impl TraitA for Btype {}
impl TraitA for Ctype {}
fn doit() -> impl TraitA { // 注意这一行的函数返回类型
let a = Atype;
a
// 或
// let b = Btype;
// b
// 或
// let c = Ctype;
// c
}
可以看到,这种表达非常简洁,同一个函数签名可以返回多种不同的类型,并且在函数定义时就可以返回具体的类型的实例。更重要的是消除了类型参数T。
上述代码已经很有用了,但是还是不够灵活,比如我们要用if逻辑选择不同的分支返回不同的类型,就会遇到问题。
struct Atype;
struct Btype;
struct Ctype;
trait TraitA {}
impl TraitA for Atype {}
impl TraitA for Btype {}
impl TraitA for Ctype {}
fn doit(i: u32) -> impl TraitA {
if i == 0 {
let a = Atype;
a // 在这个分支中返回类型a
} else if i == 1 {
let b = Btype;
b // 在这个分支中返回类型b
} else {
let c = Ctype;
c // 在这个分支中返回类型c
}
}
提示:
error[E0308]: `if` and `else` have incompatible types
--> src/lib.rs:22:5
|
17 | } else if i == 1 {
| __________-
18 | | let b = Btype;
19 | | b
| | - expected because of this
20 | | } else {
21 | | let c = Ctype;
22 | | c
| | ^ expected `Btype`, found `Ctype`
23 | | }
| |___- `if` and `else` have incompatible types
if else 要求返回同一种类型,Rust检查确实严格。不过我们可以通过加return跳过 if else 的限制。
struct Atype;
struct Btype;
struct Ctype;
trait TraitA {}
impl TraitA for Atype {}
impl TraitA for Btype {}
impl TraitA for Ctype {}
fn doit(i: u32) -> impl TraitA {
if i == 0 {
let a = Atype;
return a; // 这里用return语句直接从函数返回
} else if i == 1 {
let b = Btype;
return b;
} else {
let c = Ctype;
return c;
}
}
但是还是报错。
error[E0308]: mismatched types
--> src/lib.rs:19:12
|
13 | fn doit(i: u32) -> impl TraitA { // 这一行
| ----------- expected `Atype` because of return type
...
19 | return b
| ^ expected `Atype`, found `Btype`
它说期望Atype,却得到了Btype。这个报错其实有点奇怪,它们不是都满足 impl TraitA 吗?
原来问题在于,impl TraitA 作为函数返回值这种语法,其实也只是 指代某一种类型 而已,而这种类型是在函数体中由返回值的类型来自动推导出来的。例子中,Rustc小助手遇到Atype这个分支时,就已经确定了函数返回类型为Atype,因此当它分析到后面的Btype分支时,就发现类型不匹配了。问题就在这里。你可以将条件分支顺序换一下,看一下报错的提示,加深印象。
那我们应该怎么处理这种问题呢?
好在,Rust还给我们提供了进一步的措施: trait object。形式上,就是在trait名前加 dyn 关键字修饰,在这个例子里就是 dyn TraitA。 dyn TraitName 本身就是一种类型,它和 TraitName 这个 trait 相关,但是它们不同,dyn TraitName 是一个独立的类型。
我们使用dyn TraitA改写上面的代码。
struct Atype;
struct Btype;
struct Ctype;
trait TraitA {}
impl TraitA for Atype {}
impl TraitA for Btype {}
impl TraitA for Ctype {}
fn doit(i: u32) -> dyn TraitA { // 注意这里的返回类型换成了 dyn TraitA
if i == 0 {
let a = Atype;
return a
} else if i == 1 {
let b = Btype;
return b
} else {
let c = Ctype;
return c
}
}
但是编译会报错。
error[E0746]: return type cannot have an unboxed trait object
--> src/lib.rs:13:20
|
13 | fn doit(i: u32) -> dyn TraitA {
| ^^^^^^^^^^ doesn't have a size known at compile-time
|
help: return an `impl Trait` instead of a `dyn Trait`, if all returned values are the same type
|
13 | fn doit(i: u32) -> impl TraitA {
| ~~~~
help: box the return type, and wrap all of the returned values in `Box::new`
|
13 ~ fn doit(i: u32) -> Box<dyn TraitA> {
14 | if i == 0 {
15 | let a = Atype;
16 ~ return Box::new(a)
17 | } else if i == 1 {
18 | let b = Btype;
19 ~ return Box::new(b)
20 | } else {
21 | let c = Ctype;
22 ~ return Box::new(c)
这段提示很经典,我们来仔细阅读一下。
它说 dyn TraitA 编译时尺寸未知。dyn trait确实不是一个固定尺寸类型。然后给出了第一个建议:你可以用 impl TraitA 来解决,前提是所有分支返回同一类型。随后给出了第二个建议,你可以用Box把dyn TraitA包起来。
(👨🏫:有没有ChatGPT的即时感,聪明得不太像一个编译器。)
第一个建议我们已经试过了,Pass,我们按照第二种建议改一下试试。
struct Atype;
struct Btype;
struct Ctype;
trait TraitA {}
impl TraitA for Atype {}
impl TraitA for Btype {}
impl TraitA for Ctype {}
fn doit(i: u32) -> Box<dyn TraitA> {
if i == 0 {
let a = Atype;
Box::new(a)
} else if i == 1 {
let b = Btype;
Box::new(b)
} else {
let c = Ctype;
Box::new(c)
}
}
这下完美了,编译通过,达成目标,我们成功地将不同类型的实例在同一个函数中返回了。
这里我们引入了一个新的东西 Box<T>。 Box<T> 的作用是可以保证获得里面值的所有权,必要的时候会进行内存的复制,比如把栈上的值复制到堆中去。一旦值到了堆中,就很容易掌握到它的所有权。
具体到这个示例中,因为a、b、c都是函数中的局部变量,这里如果返回引用 &dyn TraitA 的话是万万不能的,因为违反了所有权规则。而 Box<T> 就能满足这里的要求。后续我们在智能指针一讲中会继续讲解 Box<T>。
这里我们先暂停,我希望你可以用一点时间来回顾一下整个推导过程,这次令人印象深刻的类型“体操”值得我们多品味几次。
利用trait object传参
impl trait 和 dyn trait 也可以用于函数传参。
impl trait的示例:
struct Atype; struct Btype; struct Ctype; trait TraitA {} impl TraitA for Atype {} impl TraitA for Btype {} impl TraitA for Ctype {} fn doit(x: impl TraitA) {} // 等价于 // fn doit<T: TraitA>(x: T) {} fn main() { let a = Atype; doit(a); let b = Btype; doit(b); let c = Ctype; doit(c); }
dyn trait的示例:
struct Atype; struct Btype; struct Ctype; trait TraitA {} impl TraitA for Atype {} impl TraitA for Btype {} impl TraitA for Ctype {} fn doit(x: &dyn TraitA) {} // 注意这里用了引用形式 &dyn TraitA fn main() { let a = Atype; doit(&a); let b = Btype; doit(&b); let c = Ctype; doit(&c); }
两种都可以。那么它们的区别是什么呢?
impl trait用的是编译器静态展开,也就是编译时具化(单态化)。上面那个impl trait示例展开后类似于下面这个样子。
struct Atype; struct Btype; struct Ctype; trait TraitA {} impl TraitA for Atype {} impl TraitA for Btype {} impl TraitA for Ctype {} fn doit_a(x: Atype) {} fn doit_b(x: Btype) {} fn doit_c(x: Ctype) {} fn main() { let a = Atype; doit_a(a); let b = Btype; doit_b(b); let c = Ctype; doit_c(c); }
而 dyn trait的版本不会在编译期间做任何展开,dyn TraitA 自己就是一个类型,这个类型相当于一个代理类型,用于在运行时代理相关类型及调用对应方法。既然是代理,也就是调用方法的时候需要多跳转一次,从性能上来说,当然要比在编译期直接展开一步到位调用对应函数要慢一点。
静态展开也有问题,就是会使编译出来的内容体积增大,而dyn trait就不会。所以它们各有利弊,可以根据需求视情况选择。另外, impl trait和dyn trait都是消除类型参数的办法。
那它们和enum相比呢?
enum是封闭类型集,可以把没有任何关系的任意类型包裹成一个统一的单一类型。后续的任何变动,都需要改这个统一类型,以及基于这个enum的模式匹配等相关代码。而impl trait和dyn trait是开放类型集。只要对新的类型实现trait,就可以传入使用了impl trait或dyn trait的函数,其函数签名不用变。
上述区别对于库的提供者非常重要。如果你提供了一个库,里面的多类型使用的enum包装,那么库的使用者没办法对你的enum进行扩展。因为一般来说,我们不鼓励去修改库里面的代码。而用 impl trait 或 dyn trait 就可以让接口具有可扩展性。用户只需要给他们的类型实现你的库提供的trait,就可以代入库的接口使用了。
而对于impl trait来说,它目前只能用于少数几个地方。一个是函数参数,另一个是函数返回值。其他的静态展开场景就得用类型参数形式了。
dyn trait本身是一种非固定尺寸类型,这就注定了相比于 impl trait 它能应用于更多场合,比如利用trait obj把不同的类型装进集合里。
利用trait obj将不同的类型装进集合里
我们看下面的示例,我们想把三种类型装进一个Vec里面。
struct Atype; struct Btype; struct Ctype; trait TraitA {} impl TraitA for Atype {} impl TraitA for Btype {} impl TraitA for Ctype {} fn main() { let a = Atype; let b = Btype; let c = Ctype; let v = vec![a, b, c]; }
报错:
error[E0308]: mismatched types
--> src/main.rs:19:21
|
19 | let v = vec![a, b, c];
| ^ expected `Atype`, found `Btype`
因为Vec中要求每一个元素是同一种类型,不能将不同的类型实例放入同一个Vec。而利用trait object,我们可以“绕”过这个限制。
请看示例:
struct Atype; struct Btype; struct Ctype; trait TraitA {} impl TraitA for Atype {} impl TraitA for Btype {} impl TraitA for Ctype {} fn main() { let a = Atype; let b = Btype; let c = Ctype; let v: Vec<&dyn TraitA> = vec![&a, &b, &c]; }
成功了,不同类型的实例(实际是实例的引用)竟然被放进了同一个Vec中,强大!你可以自己尝试一下,将不同类型的实例放入HashMap中。
既然trait object这么好用,那是不是可以随便使用呢?不是的。除了前面提到的性能损失之外,还有一个问题,不是所有的trait都可以做dyn化,也就是说,不是所有的trait都能转成trait object使用。
哪些trait能用作trait object?
只有满足对象安全(object safety)的trait才能被用作trait object。Rust参考手册上有关于 object safety 的详细规则,比较复杂。这里我们了解常用的模式就行。
安全的trait object:
trait TraitA {
fn foo(&self) {}
fn foo_mut(&mut self) {}
fn foo_box(self: Box<Self>) {}
}
不安全的trait object:
trait NotObjectSafe {
const CONST: i32 = 1; // 不能包含关联常量
fn foo() {} // 不能包含这样的关联函数
fn selfin(self); // 不能将Self所有权传入
fn returns(&self) -> Self; // 不能返回Self
fn typed<T>(&self, x: T) {} // 方法中不能有类型参数
}
规则确实比较复杂,你可以简单记住几种场景。
- 不要在trait里面定义构造函数,比如new这种返回Self的关联函数。你可以发现,确实在整个Rust生态中都没有将构造函数定义在trait中的习惯。
- trait里面尽量定义传引用 &self 或 &mut self的方法,而不要定义传值 self 的方法。
并不是所有的trait都能以trait object形式(dyn trait)使用,实际上,以dyn trait使用的场景可能是少数。所以你可以在遇到编译器报错的时候再回头来审视trait定义得是否合理。大部分情况下可以放心使用。
小结
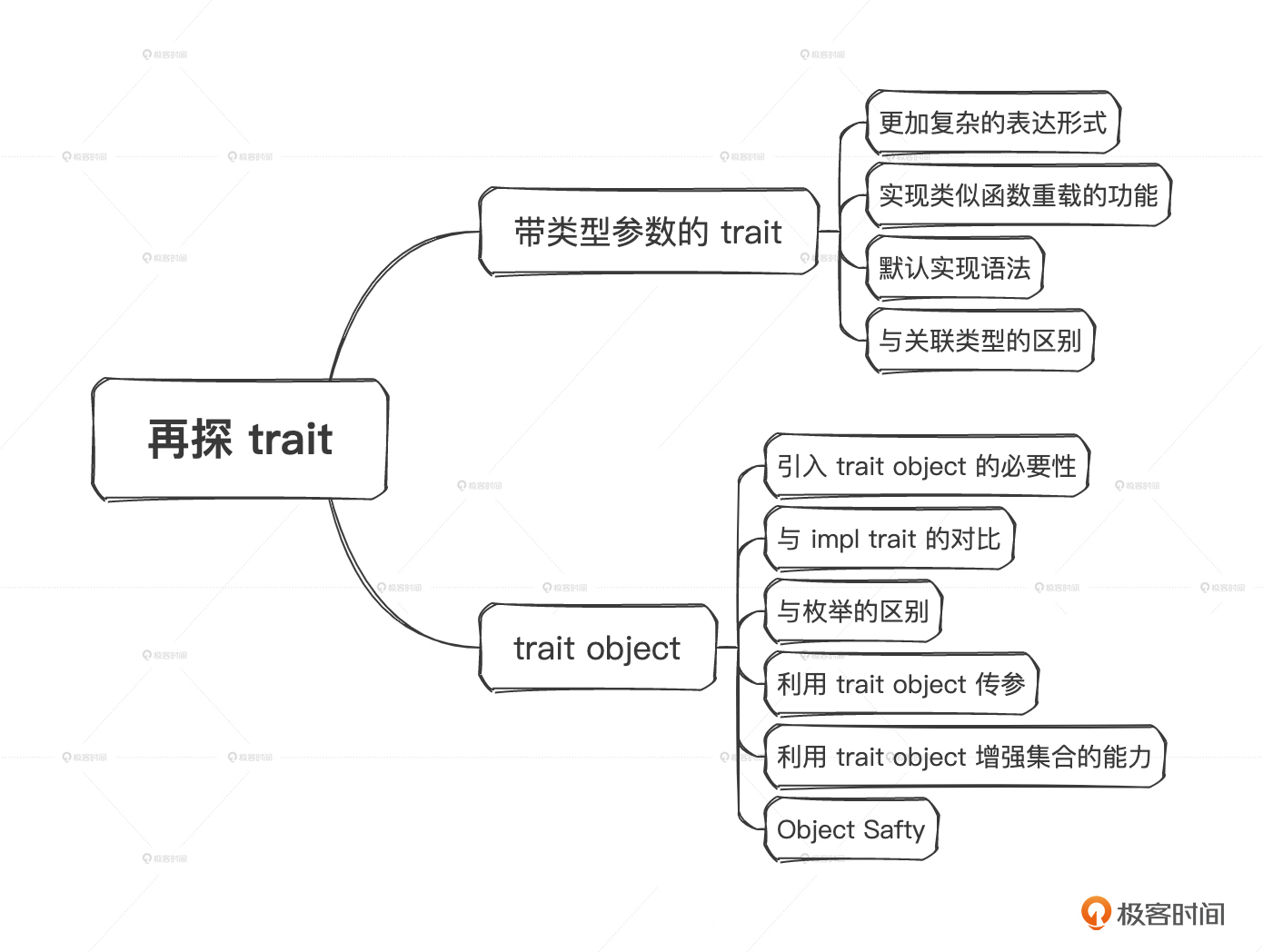
在这节课的前半部分,我们讲解了trait中带类型参数的情况。各种符号组合起来,确实越来越复杂了。不过还是那句话,模式就那几种,只要花点时间熟悉理解,其实并不难。开始的时候能认识就行,后面在实践中再慢慢掌握。
我们使用带类型参数的trait实现了其他语言中函数重载的功能。看起来途径有点曲折,但是带给了我们一条全新的思路:以往的语言必须给自身添加各种特性来满足用户的要求,在Rust中,用好trait就能搞定。这让我们对Rust的未来充满期待,随着时间的发展,它不会像C++、Java那样永不停歇地添加可能会导致组合爆炸的新特性,而让自身越来越臃肿。
我们还讨论了带类型参数的trait与关联类型的区别。它们之间并不存在绝对优势的一方,在合适的场景下选择合适的方案是最重要的。
然后我们通过一个问题:如何让一个Rust函数返回可能的多种类型?推导出了引入trait object方案的必要性。整个推导过程比较曲折,同时也是对Rust类型系统的一次精彩探索。在这个探索过程中,我们和Rustc小助手成为了好朋友,在它的协助下,我们找到了最佳方案。
最后我们了解了trait object的一些用途,并讨论了trait object、impl trait,还有使用枚举对类型进行聚合这三种方式之间的区别。类型系统(类型+ trait)是Rust的大脑,你可以多加练习,熟悉它的形式,掌握它的用法。
思考题
请谈谈在函数参数中传入 &dyn TraitA 与 Box<dyn TraitA> 两种类型的区别。
欢迎你把思考后的结果分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
常见trait解析:标准库中的常见trait应该怎么用?
你好,我是Mike,今天我们一起来学习Rust中的常见trait。
前面两节课我们已经讲过trait在Rust中的重要性了,这节课就是trait在Rust标准库中的应用。Rust标准库中包含大量的trait定义,甚至Rust自身的某些语言特性就是在这些trait的帮助下实现的。这些trait和标准库里的各种类型一起,构成了整个Rust生态的根基,只有了解它们才算真正了解Rust。
注:这节课大量代码来自 Tour of Rust’s Standard Library Traits,我加了必要的注解和分析。
学习完这节课的内容,你会对很多问题都豁然开朗。下面就让我们来学习标准库里一些比较常用的trait。
标准库中的常用trait
Default
我们来看Default trait的定义以及对Default trait的实现和使用。
trait Default {
fn default() -> Self;
}
struct Color(u8, u8, u8); impl Default for Color { // 默认颜色是黑色 (0, 0, 0) fn default() -> Self { Color(0, 0, 0) } } fn main() { let color = Color::default(); // 或 let color: Color = Default::default(); }
还有其他一些地方用到了Default,比如 Option<T> 的 unwrap_or_default(),在类型参数上调用 default() 函数。
fn paint(color: Option<Color>) {
// 如果没有颜色参数传进来,就用默认颜色
let color = color.unwrap_or_default();
// ...
}
// 由于default()是在trait中定义的关联函数,因此可方便的由类型参数调用
fn guarantee_length<T: Default>(mut vec: Vec<T>, min_len: usize) -> Vec<T> {
for _ in 0..min_len.saturating_sub(vec.len()) {
vec.push(T::default()); // 这里用了 T::default() 这种形式
}
vec
}
前面讲过,如果是struct,还可以使用部分更新语法,这个时候其实是Default在发挥作用。
#[derive(Default)]
struct Color {
r: u8,
g: u8,
b: u8,
}
impl Color {
fn new(r: u8, g: u8, b: u8) -> Self {
Color {
r,
g,
b,
}
}
}
impl Color {
fn red(r: u8) -> Self {
Color {
r,
..Color::default() // 注意这一句
}
}
fn green(g: u8) -> Self {
Color {
g,
..Color::default() // 注意这一句
}
}
fn blue(b: u8) -> Self {
Color {
b,
..Color::default() // 注意这一句
}
}
}
Rust标准库实际给我们提供了一个标注,也就是 #[derive()] 里面放 Default,方便我们为结构体自动实现Default trait。
#[derive(Default)]
struct Color {
r: u8,
g: u8,
b: u8
}
#[derive(Default)]
struct Color2(u8, u8, u8);
注意这里的细节,我们用 #[derive()] 在两个结构体上作了标注,这里面出现的这个 Default 不是trait,它是一个同名的派生宏(我们后面会讲到)。这种派生宏标注帮助我们实现了 Default trait。Rustc能正确区分Default到底是宏还是trait,因为它们出现的位置不一样。
为什么可以自动实现Default trait呢?因为Color里面的类型是基础类型u8,而u8是实现了Default trait的,默认值为 0。
Display
我们看Display trait的定义。
trait Display {
fn fmt(&self, f: &mut Formatter<'_>) -> Result;
}
Display trait对应于格式化符号 "{}",比如 println!("{}", s),用于决定一个类型如何显示,其实就是把类型转换成字符串表达。Display需要我们自己手动去实现。
示例:
use std::fmt; #[derive(Default)] struct Point { x: i32, y: i32, } // 为Point实现 Display impl fmt::Display for Point { // 实现唯一的fmt方法,这里定义用户自定义的格式 fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "({}, {})", self.x, self.y) // write!宏向stdout写入 } } fn main() { println!("origin: {}", Point::default()); // 打印出 "origin: (0, 0)" // 在 format! 中用 "{}" 将类型表示/转换为 String let stringified = format!("{}", Point::default()); assert_eq!("(0, 0)", stringified); // ✅ }
ToString
我们来看ToString trait 定义。
trait ToString {
fn to_string(&self) -> String;
}
它提供了一个 to_string() 方法,方便把各种类型实例转换成字符串。但实际上不需要自己去给类型实现ToString trait,因为标准库已经给我们做了总实现( 第 9 讲 提到过),像下面这个样子。
impl<T: Display> ToString for T
也就是说,凡是实现了Display的就实现了ToString。这两个功能本质是一样的,就是把类型转换成字符串表达。只不过Display侧重于展现,ToString侧重于类型转换。下面这个示例证明这两者是等价的。
#[test] // ✅
fn display_point() {
let origin = Point::default();
assert_eq!(format!("{}", origin), "(0, 0)");
}
#[test] // ✅
fn point_to_string() {
let origin = Point::default();
assert_eq!(origin.to_string(), "(0, 0)");
}
#[test] // ✅
fn display_equals_to_string() {
let origin = Point::default();
assert_eq!(format!("{}", origin), origin.to_string());
}
所以把一个符合条件的类型实例转换成字符串有两种常用方法。
let s = format!("{}", obj);
// 或
let s = obj.to_string();
Debug
Debug 跟 Display 很像,也主要是用于调试打印。打印就需要指定格式,区别在于Debug trait 是配对 "{:?}" 格式的,Display是配对 "{}" 的。它们本身都是将类型表示或转换成 String 类型。一般来说,Debug的排版信息比Display要多一点,因为它是给程序员调试用的,不是给最终用户看的。Debug还配套了一个美化版本格式 "{:#?}",用来把类型打印得更具结构化一些,适合调试的时候查看,比如json结构会展开打印。
Rust标准库提供了Debug宏。一般来说,我们都是以这个宏为目标类型自动生成Debug trait,而不是由我们自己手动去实现,这一点和Display正好相对,std标准库里并没有提供一个 Display 宏,来帮助我们自动实现 Display trait,需要我们手动实现它。
再提醒你一下,Rust的类型能够自动被derive的条件是,它里面的每个元素都能被derive,比如下面这个结构体里的每个字段,都是i32类型的,这种基础类型在标准库里已经被实现过Debug trait了,所以可以直接在Point上做derive为Point类型实现Debug trait。这个原则适用于所有trait,后面不再赘述。
#[derive(Debug)]
struct Point {
x: i32,
y: i32,
}
PartialEq和Eq
如果一个类型上实现了PartialEq,那么它就能比较两个值是否相等。这种可比较性满足数学上的对称性和传递性,我们通过两个例子具体来看。
- 对称性(symmetry):
a == b导出b == a。 - 传递性(transitivity):
a == b && b == c导出a == c。
而Eq定义为PartialEq的subtrait,在PartialEq的对称性和传递性的基础上,又添加了自反性,也就是对所有 a 都有 a == a。最典型的就是Rust中的浮点数只实现了PartialEq,没实现Eq,因为根据IEEE的规范,浮点数中存在一个NaN,它不等于自己,也就是 NaN ≠ NaN。而对整数来说,PartialEq和Eq都实现了。
如果一个类型,它的所有字段都实现了PartialEq,那么使用标准库中定义的PartialEq派生宏,我们可以为目标类型自动实现可比较能力,用==号,或者用 assert_eq!() 做判断。
#[derive(PartialEq, Debug)] // 注意这一句
struct Point {
x: i32,
y: i32,
}
fn example_assert(p1: Point, p2: Point) {
assert_eq!(p1, p2); // 比较
}
fn example_compare_collections<T: PartialEq>(vec1: Vec<T>, vec2: Vec<T>) {
if vec1 == vec2 { // 比较
// some code
} else {
// other code
}
}
PartialOrd和Ord
PartialOrd和PartialEq差不多,PartialEq只判断相等或不相等,PartialOrd在这个基础上进一步判断是小于、小于等于、大于还是大于等于。可以看到,它就是为排序功能准备的。
PartialOrd被定义为 PartialEq的subtrait。它们在类型上可以用过程宏一起derive实现。
#[derive(PartialEq, PartialOrd)]
struct Point {
x: i32,
y: i32,
}
#[derive(PartialEq, PartialOrd)]
enum Stoplight {
Red,
Yellow,
Green,
}
类似的,Ord 定义为 Eq + PartialOrd 的 subtrait。如果我们为一个类型实现了 Ord,那么对那个类型的所有值,我们可以做出一个严格的总排序,比如u8,我们可以严格地从0排到255,形成一个确定的从小到大的序列。
同样的,浮点数实现了 PartialOrd,但是没实现 Ord。
由于Ord严格的顺序性,如果一个类型实现了Ord,那么这个类型可以被用作BTreeMap或BTreeSet的key。
BTreeMap、BTreeSet:相对于HashMap和HashSet,是两种可排序结构。
示例:
use std::collections::BTreeSet;
#[derive(Ord, PartialOrd, PartialEq, Eq)] // 注意这一句,4个都写上
struct Point {
x: i32,
y: i32,
}
fn example_btreeset() {
let mut points = BTreeSet::new();
points.insert(Point { x: 0, y: 0 }); // 作key值插入
}
// 实现了Ord trait的类型的集合,可调用 .sort() 排序方法
fn example_sort<T: Ord>(mut sortable: Vec<T>) -> Vec<T> {
sortable.sort();
sortable
}
运算符重载
Rust提供了一个Add trait,用来对加号(+)做自定义,也就是运算符重载。
你可以看一下Add的定义,它带一个类型参数Rhs,这里的类型参数可以是任意名字,默认类型是Self,一个关联类型Output,一个方法add()。
trait Add<Rhs = Self> {
type Output;
fn add(self, rhs: Rhs) -> Self::Output;
}
像下面我给出的这个示例一样去使用它就可以,非常简单。
struct Point { x: i32, y: i32, } // 为 Point 类型实现 Add trait,这样两个Point实例就可以直接相加 impl Add for Point { type Output = Point; fn add(self, rhs: Point) -> Point { Point { x: self.x + rhs.x, y: self.y + rhs.y, } } } fn main() { let p1 = Point { x: 1, y: 2 }; let p2 = Point { x: 3, y: 4 }; let p3 = p1 + p2; // 这里直接用+号作用在两个Point实例上 assert_eq!(p3.x, p1.x + p2.x); // ✅ assert_eq!(p3.y, p1.y + p2.y); // ✅ }
实际上,Rust标准库提供了一套完整的与运算符对应的trait,你在 这里 可以找到可重载的运算符。你可以按类似的方式练习如何自定义各种运算符。
Clone
定义:
trait Clone {
fn clone(&self) -> Self;
}
这个trait给目标类型提供了clone()方法用来完整地克隆实例。使用标准库里面提供的Clone派生宏可以方便地为目标类型实现Clone trait。
比如:
#[derive(Clone)]
struct Point {
x: u32,
y: u32,
}
因为每一个字段(u32类型)都实现了Clone,所以通过derive,自动为Point类型实现了Clone trait。实现后,Point的实例 point 使用 point.clone() 就可以把自己克隆一份了。
通过方法的签名,可以看到方法使用的是实例的不可变引用。
fn clone(&self) -> Self;
这里面有两种情况。
- 第一种是已经拿到实例的所有权,clone一份生成一个新的所有权并被局部变量所持有。
- 第二种是只拿到一个实例的引用,想拿到它的所有权,如果这个类型实现了Clone trait,那么就可以clone一份拿到这个所有权。
clone() 是对象的深度拷贝,可能会有比较大的额外负载,但是就大多数情况来说其实还好。不要担心在Rust中使用clone(),先把程序功能跑通最重要。Rust的代码,性能一般都不会太差,毕竟起点很高。
注:浅拷贝是按值拷贝一块连续的内存,只复制一层,不会去深究这个值里面是否有到其它内存资源的引用。与之相对,深拷贝就会把这些引用对象递归全部拷贝。
在Rust生态的代码中,我们经常看到clone()。为什么呢?因为它把对实例引用的持有转换成了对对象所有权的持有。一旦我们拿到了所有权,很多代码写起来就比较轻松了。
Copy
接下来,我们看Copy trait的定义。
trait Copy: Clone {}
定义为Clone的subtrait,并且不包含任何内容,仅仅是一个标记(marker)。有趣的是,我们不能自己为自定义类型实现这个trait。比如下面这个示例就是不行的。
impl Copy for Point {} // 这是不行的
但是Rust标准库提供了Copy过程宏,可以让我们自动为目标类型实现Copy trait。
#[derive(Copy, Clone)]
struct SomeType;
因为Copy是Clone的subtrait。所以理所当然要把Clone trait也一起实现,我们在这里一次性derive过来。
Copy和Clone的区别是,Copy是浅拷贝只复制一层,不会去深究这个值里面是否有到其他内存资源的引用,比如一个字符串的动态数组。
struct Atype { num: u32, a_vec: Vec<u32>, } fn main() { let a = Atype { num: 100, a_vec: vec![10, 20, 30], }; let b = a; // 这里发生了移动 }
代码第10行的操作是将a的所有权移动给b( 第 2 讲 的内容)。
如果我们给这个结构体实现了Clone trait的话,我们可以调用.clone() 来产生一份新的所有权。
#[derive(Clone, Debug)] struct Atype { num: u32, a_vec: Vec<u32>, // 动态数组资源在堆内存中 } fn main() { let a = Atype { num: 100, a_vec: vec![10, 20, 30], }; let mut b = a.clone(); // 克隆,也将堆内存中的Vec资源部分克隆了一份 b.num = 200; // 更改b的值 b.a_vec[0] = 11; b.a_vec[1] = 21; b.a_vec[2] = 31; println!("{a:?}"); // 对比两份值 println!("{b:?}"); } // 输出 Atype { num: 100, a_vec: [10, 20, 30] } Atype { num: 200, a_vec: [11, 21, 31] }
通过例子可以看到,clone()一份新的所有权出来,b改动的值不影响a的值。
而一旦你想在 Atype 上实现 Copy trait的话,就会报错。
error[E0204]: the trait `Copy` cannot be implemented for this type
--> src/main.rs:1:10
|
1 | #[derive(Copy, Clone, Debug)]
| ^^^^
...
4 | a_vec: Vec<u32>, // 动态数组资源在堆内存中
| --------------- this field does not implement `Copy`
它说动态数组字段 a_vec 没有实现Copy trait,所以你不能对Atype实现Copy trait。原因也好理解,Vec是一种所有权结构,如果你在它上面实现了Copy,那再赋值的时候,就会出现对同一份资源的两个指向,冲突了!
一旦一个类型实现了Copy,它就会具备一个特别重要的特性: 再赋值的时候会复制一份自身。那么就相当于新创建一份所有权。我们来看下面这个值全在栈上的类型。
#[derive(Clone)] struct Point { x: u32, y: u32, } fn main() { let a = Point {x: 10, y: 10}; let b = a; // 这里发生了所有权move,a在后续不能使用了 }
我们对 Point 实现Clone和Copy。
#[derive(Copy, Clone)] struct Point { x: u32, y: u32, } fn main() { let a = Point {x: 10, y: 10}; let b = a; // 这里发生了复制,a在后续可以继续使用 let c = a; // 这里又复制了一份,这下有3份了 }
仔细体会一下,现在你知道我们在第2讲里面讲到的复制与移动的语义区别根源在哪里了吧!
你可能会问,Point结构体里面的字段其实全都是固定尺寸的,并且u32是copy语义的,按理说Point也是编译时已知固定尺寸的,为什么它默认不实现copy语义呢?
这其实是Rust设计者故意这么做的。因为Copy trait其实关联到赋值语法,仅仅从这个语法(let a = b;),很难一下子看出来这到底是copy还是move,它是一种 隐式行为。
而在所有权的第一设计原则框架下,Rust默认选择了move语义。所以方便起见,Rust设计者就只让最基础的那些类型,比如u32、bool等具有copy语义。而用户自定义的类型,一概默认move语义。如果用户想给自定义类型赋予copy语义内涵,那么他需要显式地在那个类型上添加Copy的derive。
我们再回过头来看Clone,一个类型实现了Clone后,需要显式地调用 .clone() 方法才会导致对象克隆,这就在代码里面留下了足迹。而如果一个类型实现了Copy,那么它在用 = 号对实例再赋值的时候就发生了复制,这里缺少了附加的足迹。这就为潜在的Bug以及性能的降低埋下了隐患,并且由于没有附加足迹,导致后面再回头来审查的时候非常困难。
试想,如果是.clone(),那么我们只需要用代码搜索工具搜索代码哪些地方出现了clone函数就可以了。这个设计,在 Option<T> 和 Result<T, E> 的 unwrap() 系列函数上也有体现。
显式地留下足迹,是Rust语言设计重要的哲学之一。
至于Copy为什么要定义成Clone的subtrait,而不是反过来,也是跟这个设计哲学相关。可以这么说,一般情况下,Rust鼓励优先使用Clone而不鼓励使用Copy,于是让开发者在derive Copy的时候,也必须derive Clone,相当于多打了几个字符,多付出了一点代价。也许开发者这时会想,可能Clone就能满足我的要求了,能在结构体上的derive宏里面少打几个字符,也是一件好事儿。
还有一个原因其实是,Clone和Copy在本质上其实是一样的,都是内存的按位复制,只是复制的规则有一些区别。
ToOwned
ToOwned相当于是Clone更宽泛的版本。ToOwned给类型提供了一个 to_owned() 方法,可以将引用转换为所有权实例。
常见的比如:
let a: &str = "123456";
let s: String = a.to_owned();
通过查看标准库和第三方库接口文档,你可以确定有没实现这个trait。
Deref
Deref trait可以用来把一种类型转换成另一种类型,但是要在引用符号&、点号操作符 . 或其他智能指针的触发下才会产生转换。比如标准库里最常见的 &String 可以自动转换到 &str(请回顾 第 4 讲),就是因为String类型实现了Deref trait。

还有 &Vec<T> 可以自动转换为 &[T],也是因为 Vec[T] 实现了Deref。

到这里,Rust里很多魔法就开始揭开神秘面纱了。有了这些trait以及在各种类型上的实现,Rust让我们可以写出顺应直觉、赏心悦目、功能强大的代码。
你还可以在标准库文档中搜索Deref,查阅所有实现了Deref trait的 implementors。
这里需要提醒你一下,有人尝试 用 Deref 机制去实现 OOP 继承,但是那是徒劳和不完整的,有兴趣的话你可以看一下我给出的链接。
Drop
Drop trait用于给类型做自定义垃圾清理(回收)。
trait Drop {
fn drop(&mut self);
}
实现了这个trait的类型的实例在走出作用域的时候,触发调用drop()方法,这个调用发生在这个实例被销毁之前。你可以看一下它的使用方式。
struct A;
impl Drop for A {
fn drop(&mut self){
// 可以尝试在这里打印点东西看看什么时候调用
}
}
一般来说,我们不需要为自己的类型实现这个trait,除非遇到特殊情况,比如我们要调用外部的C库函数,然后在C那边分配了资源,由C库里的函数负责释放,这个时候我们就要在Rust的包装类型(对C库中类型的包装)上实现Drop,并调用那个C库中释放资源的函数。课程最后两讲FFI编程中,你会看到Drop的具体使用。
闭包相关trait
标准库中有3个trait与闭包相关,分别是FnOnce、FnMut、Fn。你可以看一下它们的定义。
trait FnOnce<Args> {
type Output;
fn call_once(self, args: Args) -> Self::Output;
}
trait FnMut<Args>: FnOnce<Args> {
fn call_mut(&mut self, args: Args) -> Self::Output;
}
trait Fn<Args>: FnMut<Args> {
fn call(&self, args: Args) -> Self::Output;
}
前面我们也讲过,闭包就是一种能捕获上下文环境变量的函数。
let range = 0..10;
let get_range_count = || range.count();
代码里的这个 get_range_count 就是闭包,range是被这个闭包捕获的环境变量。
虽然说它是一种函数,但是不通过fn进行定义。在Rust中,并不把这个闭包的类型处理成fn这种函数指针类型,而是有单独的类型定义。
那么,具体是什么类型呢?其实我们也不知道。闭包的类型是由Rust编译器在编译时确定的,并且在确定类型的时候要根据这个闭包捕获上下文环境变量时的行为来确定。
总的来说有三种行为(⚠️ 所有权三态再现)。
- 获取了上下文环境变量的所有权,对应 FnOnce。
- 只获取了上下文环境变量的&mut引用,对应 FnMut。
- 只获取了上下文环境变量的&引用,对应 Fn。
根据这三种不同的行为,Rust编译器在编译时把闭包生成为这三种不同类型中的一种。这三种不同类型的闭包,具体类型形式我们不知道,Rust没有暴露给我们。但是Rust给我们暴露了FnOnce、FnMut、Fn这3个trait,就刚好对应于那三种类型。结合我们前面讲到的trait object,就能在我们的代码中对那些类型进行描述了。
FnOnce代表的闭包类型只能被调用一次,比如;
fn main() { let range = 0..10; let get_range_count = || range.count(); assert_eq!(get_range_count(), 10); // ✅ get_range_count(); // ❌ }
再调用就报错了。
FnMut代表的闭包类型能被调用多次,并且能修改上下文环境变量的值,不过有一些副作用,在某些情况下可能会导致错误或者不可预测的行为。比如:
fn main() { let nums = vec![0, 4, 2, 8, 10, 7, 15, 18, 13]; let mut min = i32::MIN; let ascending = nums.into_iter().filter(|&n| { if n <= min { false } else { min = n; // 这里修改了环境变量min的值 true } }).collect::<Vec<_>>(); assert_eq!(vec![0, 4, 8, 10, 15, 18], ascending); // ✅ }
Fn 代表的这类闭包能被调用多次,但是对上下文环境变量没有副作用。比如:
fn main() { let nums = vec![0, 4, 2, 8, 10, 7, 15, 18, 13]; let min = 9; let greater_than_9 = nums.into_iter().filter(|&n| n > min).collect::<Vec<_>>(); assert_eq!(vec![10, 15, 18, 13], greater_than_9); // ✅ }
另外,fn这种函数指针,用在不需要捕获上下文环境变量的场景,比如:
fn add_one(x: i32) -> i32 { x + 1 } fn main() { let mut fn_ptr: fn(i32) -> i32 = add_one; // 注意这里的类型定义 assert_eq!(fn_ptr(1), 2); // ✅ // 如果一个闭包没有捕捉环境变量,它可以通过类型转换转成 fn 类型 fn_ptr = |x| x + 1; // same as add_one assert_eq!(fn_ptr(1), 2); // ✅ }
From<T> 和 Into<T>
接下来,我们看 Rust 标准库中的两个关联的 trait From<T> 和 Into<T>,它们用于类型转换。 From<T> 可以把类型T转为自己,而 Into<T> 可以把自己转为类型T。
trait From<T> {
fn from(T) -> Self;
}
trait Into<T> {
fn into(self) -> T;
}
可以看到它们是互逆的trait。实际上,Rust只允许我们实现 From<T>,因为实现了From后,自动就实现了Into,请看标准库里的这个实现。
impl<T, U> Into<U> for T
where
U: From<T>,
{
fn into(self) -> U {
U::from(self)
}
}
对一个类型实现了From后,就可以像下面这样约束和使用。
fn function<T>(t: T)
where
// 下面这两种约束是等价的
T: From<i32>,
i32: Into<T>
{
// 等价
let example: T = T::from(0);
let example: T = 0.into();
}
我们来举一个具体的例子。
struct Point {
x: i32,
y: i32,
}
impl From<(i32, i32)> for Point { // 实现从(i32, i32)到Point的转换
fn from((x, y): (i32, i32)) -> Self {
Point { x, y }
}
}
impl From<[i32; 2]> for Point { // 实现从[i32; 2]到Point的转换
fn from([x, y]: [i32; 2]) -> Self {
Point { x, y }
}
}
fn example() {
// 使用from()转换不同类型
let origin = Point::from((0, 0));
let origin = Point::from([0, 0]);
// 使用into()转换不同类型
let origin: Point = (0, 0).into();
let origin: Point = [0, 0].into();
}
其实From是单向的。对于两个类型要互相转的话,是需要互相实现From的。
本身, From<T> 和 Into<T> 都隐含了所有权, From<T> 的Self是具有所有权的, Into<T> 的T也是具有所有权的。 Into<T> 有个常用的比 From<T> 更自然的场景是,如果你已经拿到了一个变量,想把它变成具有所有权的值,Into写起来更顺手。因为 into() 是方法,而 from() 是关联函数。
比如:
struct Person {
name: String,
}
impl Person {
// 这个方法只接收String参数
fn new1(name: String) -> Person {
Person { name }
}
// 这个方法可接收
// - String
// - &String
// - &str
// - Box<str>
// - char
// 这几种参数,因为它们都实现了Into<String>
fn new2<N: Into<String>>(name: N) -> Person {
Person { name: name.into() } // 调用into(),写起来很简洁
}
}
TryFrom TryInto
TryFrom<T> 和 TryInto<T> 是 From<T> 和 Into<T> 的可失败版本。如果你认为转换可能会出现失败的情况,就选择这两个trait来实现。
trait TryFrom<T> {
type Error;
fn try_from(value: T) -> Result<Self, Self::Error>;
}
trait TryInto<T> {
type Error;
fn try_into(self) -> Result<T, Self::Error>;
}
可以看到,调用 try_from() 和 try_into() 后返回的是Result,你需要对Result进行处理。
FromStr
从字符串类型转换到自身。
trait FromStr {
type Err;
fn from_str(s: &str) -> Result<Self, Self::Err>;
}
其实我们前面已经遇到过这个trait,它就是字符串的 parse() 方法背后的trait。
use std::str::FromStr;
fn example<T: FromStr>(s: &str) {
// 下面4种表达等价
let t: Result<T, _> = FromStr::from_str(s);
let t = T::from_str(s);
let t: Result<T, _> = s.parse();
let t = s.parse::<T>(); // 最常用的写法
}
AsRef<T>
AsRef<T> 的定义类似下面这个样子:
trait AsRef<T> {
fn as_ref(&self) -> &T;
}
它把自身的引用转换成目标类型的引用。和Deref的区别是, **deref() 是隐式调用的,而 as_ref() 需要你显式地调用**。所以代码会更清晰,出错的机会也会更少。
AsRef<T> 可以让函数参数中传入的类型更加多样化,不管是引用类型还是具有所有权的类型,都可以传递。比如;
// 使用 &str 作为参数可以接收下面两种类型
// - &str
// - &String
fn takes_str(s: &str) {
// use &str
}
// 使用 AsRef<str> 作为参数可以接受下面三种类型
// - &str
// - &String
// - String
fn takes_asref_str<S: AsRef<str>>(s: S) {
let s: &str = s.as_ref();
// use &str
}
fn example(slice: &str, borrow: &String, owned: String) {
takes_str(slice);
takes_str(borrow);
takes_str(owned); // ❌
takes_asref_str(slice);
takes_asref_str(borrow);
takes_asref_str(owned); // ✅
}
在这个例子里,具有所有权的String字符串也可以直接传入参数中了,相对于 &str 的参数类型表达更加扩展了一步。
你可以把 Deref 看成是隐式化(或自动化)+弱化版本的 AsRef<T>。
小结
这节课我们快速过了一遍标准库里最常见的一些trait,内容比较多。你可以先有个印象,后面遇到的时候再回过头来查阅。
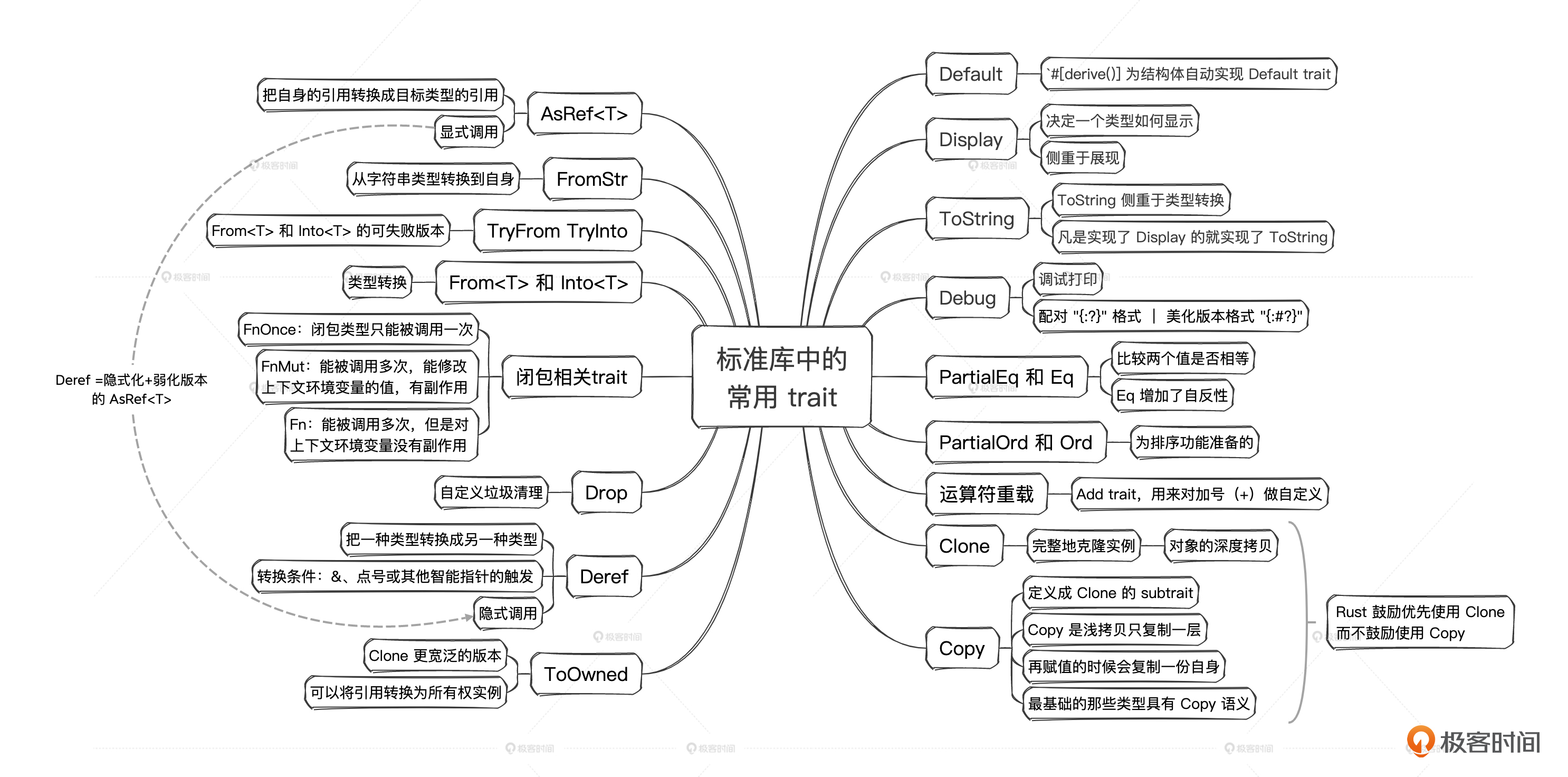
这些trait非常重要,它们一起构成了Rust生态宏伟蓝图的基础。很多前面讲到的一些神奇的“魔法”都在这节课揭开了面纱。trait这种设计真的给Rust带来了强大的表达力和灵活性,对它理解越深刻,越能体会Rust的厉害。trait完全解构了从C++、Java以来编程语言的发展范式,从紧耦合转换成松散的平铺式,让新特性的添加不会对语言本身造成沉重的负担。
到这节课为止,我们的第一阶段基础篇的学习就完成了。我们用11讲的内容详细介绍了Rust语言里最重要的部分,然而还有很多Rust的细节没办法展开,这需要你借助我提供的链接还有已有的资料持续学习。
基础篇相当于苦练内功,从下节课开始我们进入进阶篇,学习Rust语言及生态中面向实际场景的外功招式。
思考题
请举例说明 Deref 与 AsRef<T> 的区别。欢迎你把你思考后的答案分享到评论区,我们一起讨论,也欢迎你把这节课的内容分享给其他朋友,邀他一起学习Rust,我们下节课再见!
智能指针:从所有权看智能指针
你好,我是Mike。从今天开始,我们进入Rust进阶篇。
相对于基础篇,进阶篇更像外功招式,主要是掌握一些实用的基础设施,提高编程效率。这节课我们就在所有权视角下来学习Rust中的智能指针。
智能指针
学习智能指针之前,我们先来了解一下指针是什么。
指针和指针的类型
如果一个变量,里面存的是另一个变量在内存里的地址值,那么这个变量就被叫做 指针。而我们前面讲到的引用(用&号表示)就是一种指针。
引用是必定有效的指针,它一定指向一个目前有效(比如没有被释放掉)的类型实例。而指针不一定是引用。也就是说,在Rust中,还有一些其他类型的指针存在,我们这节课就来学习其中一些。
我们这里要再次明晰一下 引用的类型。引用分为不同的类型,单独的&符号本身没有什么意义,但是它和其他类型组合起来就能形成各种各样的引用类型。比如:
- &str 是字符串切片引用类型。
- &String 是所有权字符串的引用类型。
- &u32 是u32的引用类型。
注:&str、&String、&u32都是一个整体。
这三种都是引用类型,作为引用类型,它们之间是不同的。但是同一种引用类型的实例,比如 &10u32和&20u32,它们的类型是相同的。
那么,指针其实也类似,指向不同类型实例的指针,它的类型也是有区别的,这叫做 指针的类型。
智能指针
Rust中指针的概念非常灵活,比如,它可以是一个结构体类型,只要其中的一个字段存储其他类型实例的地址,然后对这个结构体实现一些Rust标准库里提供的trait,就可以把它变成指针类型。这种指针可以在传统指针的基础上添加一些额外信息,比如放在额外的一些字段中;也可以做一些额外操作,比如管理引用计数,资源自动回收等。从而显得更加智能,所以被叫做 智能指针。
其实,我们前面碰到的 String 和 Vec<T> 就是一种智能指针。我们来看标准库代码中 String 的定义和 Vec<T> 的定义。
pub struct String {
vec: Vec<u8>,
}
pub struct Vec<T, #[unstable(feature = "allocator_api", issue = "32838")] A: Allocator = Global> {
buf: RawVec<T, A>,
len: usize,
}
通过代码我们可以看到,String和 Vec<T> 实际都定义为结构体。
注:Rust中智能指针的概念也直接来自于C++。C++里面有 unique_ptr、 shared_ptr。
智能指针可以让代码的开发相对来说容易一些。经过前面的学习,我们知道Rust基于所有权出发,定义了一套完整的所有权和借用规则。很多我们习以为常的代码写法,在Rust中变成了“违法”,这导致很多人觉得学习Rust的门槛很高。而智能指针可以在某些方面降低这种门槛。
它如何能做到呢?我们稍后揭秘。
前面我们看到过这种代码:
fn foo() -> u32 { let i = 100u32; i } fn main() { let _i = foo(); }
我们看到, foo() 函数将i返回用的不是move行为,而是copy行为,将100u32这个值复制了一份,返回给外面的_i。 foo() 函数调用结束后, foo() 里的局部变量i被销毁。
我们再回忆一下另一段代码。
fn foo() -> String { let s = "abc".to_string(); s } fn main() { let _s = foo(); }
上述代码可以在函数 foo() 里生成一个字符串实例,这个字符串实例资源在堆内存中分配,s是foo函数里的局部变量,拥有字符串资源的所有权。在代码的最后一行,s把所有权返回给外部调用者并传递给_s。 foo() 调用完成后,栈上的局部变量s被销毁。
这种写法可行是因为返回了资源的所有权。如果我们把代码里的String换成&String,把s换成&s就不行了。
fn foo() -> &String { let s = "abc".to_string(); &s } fn main() { let _s = foo(); }
你可能会问,既然String资源本身是在堆中,为什么我们不能拿到这个资源的引用而返回呢?
我们来看看为什么不行。在 foo() 函数里,其实我们返回的并不是那个堆里字符串资源的引用,而是栈上局部变量s的引用。堆里的字符串资源由栈上的变量s管理,而s在 foo() 函数调用完成后,就被销毁了,堆里的字符串资源也一并被回收了,所以刚刚那段代码当然行不通了。
同样的,下面这段代码也是不允许的。
fn foo() -> &u32 { let i = 100u32; &i } fn main() { let _i = foo(); }
那么,我们有什么办法能让这种意图变得可行呢?其实是有的,比如使用 Box<T> 智能指针。
Box<T>
Box<T> 是一个类型整体,作为智能指针 Box<T> 可以把资源强行创建在堆上,并获得资源的所有权,让资源的生命期得以被程序员精确地控制。
注:堆上的资源,默认与整个程序进程的存在时间一样久。
我们来看使用 Box<T> 如何处理前面那个示例。
fn foo() -> Box<u32> { let i = 100u32; Box::new(i) } fn main() { let _i = foo(); }
通过Box,我们把栈上 i 的值,强行copy了一份并放在堆上某个地址,然后Box指针指向这个地址。
返回一个整数 i 的指针确实没多大用,如果我们定义了一个结构体,可以采用类似的办法从函数中返回结构体的Box指针。
struct Point { x: u32, y: u32 } fn foo() -> Box<Point> { let p = Point {x: 10, y: 20}; // 这个结构体的实例创建在栈上 Box::new(p) } fn main() { let _p = foo(); }
这就很有用了。
我们看示例的第7行,Point 的实例 p 实际是创建在栈上的。通过 Box::new(p),把p实例强行按位复制了一份,并且放到了堆上,我们记为 p’。然后 foo() 函数返回,把Box指针实例move给了_p。之后,_p拥有了对 p’ 的所有权。
Box<T> 中的所有权分析
我们继续深入,回顾一下上面示例里讲到的,编译期间已知尺寸的类型实例会默认创建在栈上。Point有两个字段:x、y,它们的尺寸是固定的,都是4个字节,所以Point的尺寸就是8个字节,它的尺寸也是固定的。所以它的实例会被创建在栈上。第7行的 p 拥有这个Point实例的所有权。注意Point并没有默认实现Copy,虽然它的尺寸是固定的。
在创建 Box<Point> 实例的时候会发生所有权转移:资源从栈上move到了堆上,原来栈上的那片资源被置为无效状态,因此下面的代码编译不会通过。
struct Point { x: u32, y: u32 } fn foo() -> Box<Point> { let p = Point {x: 10, y: 20}; let boxed = Box::new(p); // 创建Box实例 let q = p; // 这一句用来检查p有没有被move走 boxed } fn main() { let _p = foo(); }
编译提示:
error[E0382]: use of moved value: `p`
--> src/main.rs:9:13
|
7 | let p = Point {x: 10, y: 20};
| - move occurs because `p` has type `Point`, which does not implement the `Copy` trait
8 | let boxed = Box::new(p); // 创建Box实例
| - value moved here
9 | let q = p; // 这一句用来检查p有没有被move走
| ^ value used here after move
之所以会发生所有权这样的转移,是因为 Point 类型本身就是 move 语义的。作为对照,我们来看一个示例。
fn foo() -> Box<u8> { let i = 5; let boxed = Box::new(i); // 创建Box实例 let q = i; // 这一句用来检查i有没有被move走 boxed } fn main() { let _i = foo(); }
这个示例就可以编译通过。也就是说,在执行 Box::new() 创建 Box 实例时,具有copy语义的整数类型和具有move语义的Point类型行为不一样。整数会copy一份自己,Point实例会把自己move到Box里面去。
一旦创建好Box实例后,这个实例就具有了对里面资源的所有权了,它是move语义的,你可以看一下示例。
fn foo() -> Box<u8> { let i = 5; let boxed = Box::new(i); // 创建Box实例 let q = i; // 这一句用来检查i有没有被move走 let boxed2 = boxed; // 这一句检查boxed实例是不是move语义 boxed } fn main() { let _i = foo(); }
不能编译通过,提示:
error[E0382]: use of moved value: `boxed`
--> src/main.rs:6:5
|
3 | let boxed = Box::new(i); // 创建Box实例
| ----- move occurs because `boxed` has type `Box<u8>`, which does not implement the `Copy` trait
4 | let q = i; // 这一句用来检查i有没有被move走
5 | let boxed2 = boxed; // 这一句检查boxed实例是不是move语义
| ----- value moved here
6 | boxed
| ^^^^^ value used here after move
这个示例就验证了我们刚才的说法。
Box<T> 的解引用
前面我们讲过,创建一个Box实例把栈上的内容包起来,可以把栈上的值移动到堆上,比如:
let val: u8 = 5;
let boxed: Box<u8> = Box::new(val); // 这里 boxed 里面那个u8就是堆上的值
还可以在Box实例上使用 解引用符号*,把里面的堆上的值再次移动回栈上,比如:
let boxed: Box<u8> = Box::new(5);
let val: u8 = *boxed; // 这里这个val整数实例就是在栈上的值
解引用是 Box::new() 的 逆操作,可以看到整个过程是相反的。
对于具有copy语义的u8类型来说,解引用回来后,boxed还能使用,我们看下示例。
fn main() { let boxed: Box<u8> = Box::new(5); let val: u8 = *boxed; println!("{:?}", val); println!("{:?}", boxed); // 用于u8类型,解引用后,boxed实例还能用 } // 输出 5 5
而对于具有move语义的类型来说,情况就不一样了,会发生所有权的转移。比如:
#[derive(Debug)] struct Point { x: u32, y: u32 } fn main() { let p = Point {x: 10, y: 20}; let boxed: Box<Point> = Box::new(p); let val: Point = *boxed; // 这里做了解引用,Point实例回到栈上 println!("{:?}", val); println!("{:?}", boxed); // 解引用后想把boxed再打印出来 }
编译出错,提示 *boxed 已经 move了。
error[E0382]: borrow of moved value: `boxed`
--> src/main.rs:13:22
|
10 | let val: Point = *boxed;
| ------ value moved here
...
13 | println!("{:?}", boxed);
| ^^^^^ value borrowed here after move
因此 boxed 不能再使用。也就是说,如果 Box<T> 的 T 是 move 语义的,那么对这个Box实例做解引用操作,会把这个Box实例的所有权释放。
关于这些细节,其实你不用太担心能不能一次性掌握好,因为你用错的时候,Rustc小助手会贴心地准确提示你,所以不要有心理负担。
Box<T> 实现了trait
Box<T> 的好处在于它的明确性,它里面的资源一定在堆上,所以我们就不用再去关心资源是在栈上还是堆上这种细节问题了。一种类型,被 Box<> 包起来的过程就叫作这个类型的 盒化(boxed)。
Rust在标准库里为 Box<T> 实现了 Deref、 Drop、 AsRef<T> 等trait,所以 Box<T> 可以直接调用T实例的方法,访问T实例的值。
#[derive(Debug)] struct Point { x: u32, y: u32, } impl Point { fn play(&self) { println!("I'am a method of Point."); } } fn main() { let boxed: Box<Point> = Box::new(Point{x: 10, y: 20}); boxed.play(); // 点操作符触发deref println!("{:?}", boxed); } // 输出 I'am a method of Point. Point { x: 10, y: 20 }
Box<T> 拥有对T实例的所有权,所以可以对T实例进行写操作。
#[derive(Debug)] struct Point { x: u32, y: u32, } fn main() { let mut boxed: Box<Point> = Box::new(Point{x: 10, y: 20}); *boxed = Point { // 这一行,使用解引用操作更新值 x: 100, y: 200 }; println!("{:?}", boxed); } // 输出 Point { x: 100, y: 200 }
Box<T> 的Clone
Box<T> 能否Clone,需要看 T 是否实现了 Clone,因为我们也需要把 T 的资源克隆一份。你可以看一下我给出的示例。
#[derive(Debug, Clone)] struct Point { x: u32, y: u32, } impl Point { fn play(&self) { println!("I'am a method of Point."); } } fn main() { let mut boxed: Box<Point> = Box::new(Point{x: 10, y: 20}); let mut another_boxed = boxed.clone(); // 克隆 *another_boxed = Point{x: 100, y: 200}; // 修改新的一份值 println!("{:?}", boxed); // 打印原来一份值 println!("{:?}", another_boxed); // 打印新的一份值 } // 输出 Point { x: 10, y: 20 } Point { x: 100, y: 200 }
Box<T> 作为函数参数
我们可以把 Box<T> 作为参数传入函数,这个我们前面已经见过了。
#[derive(Debug)] struct Point { x: u32, y: u32, } fn foo(p: Box<Point>) { // 这里参数类型是 Box<Point> println!("{:?}", p); } fn main() { foo(Box::new(Point {x: 10, y: 20})); } // 输出 Point { x: 10, y: 20 }
&Box<T>
Box<T> 本身作为一种类型,对它做引用操作当然是可以的。
#[derive(Debug)] struct Point { x: u32, y: u32, } impl Point { fn play(&self) { println!("I'am a method of Point."); } } fn main() { let boxed: Box<Point> = Box::new(Point{x: 10, y: 20}); boxed.play(); // 调用类型方法 let y = &boxed; // 取boxed实例的引用 y.play(); // 调用类型方法 println!("{:?}", y); } // 输出 I'am a method of Point. I'am a method of Point. Point { x: 10, y: 20 }
在示例中,boxed是一个所有权型变量,y是一个引用型变量。它们都能调用到Point类型上的方法。
对Box实例做可变引用(&mut)也是可以的,你可以看一下示例。
#[derive(Debug)] struct Point { x: u32, y: u32, } impl Point { fn play(&self) { println!("I'am a method of Point."); } } fn main() { let mut boxed: Box<Point> = Box::new(Point{x: 10, y: 20}); let y = &mut boxed; // 这里&mut Box<Point> y.play(); // 调用类型方法 println!("{:?}", y); // 修改前的值 **y = Point {x: 100, y: 200}; // 注意这里用了二级解引用 println!("{:?}", y); // 修改后的值 } // 输出 I'am a method of Point. Point { x: 10, y: 20 } Point { x: 100, y: 200 }
这个示例里值得注意的是第18行,做了两次解引用,第一次是对&mut 做的,第二次是对 Box<T> 做的。
Box<Self>
前面我们讲过,类型的方法可以用 self、&self、&mut self 三种形态传入Self参数。其中第一种self形态还有一种变体 Box<Self>,你可以看一下示例。
#[derive(Debug)] struct Point { x: u32, y: u32, } impl Point { fn play_ref(&self) { println!("I'am play_ref of Point."); } fn play_mutref(&mut self) { println!("I'am play_mutref of Point."); } fn play_own(self) { println!("I'am play_own of Point."); } fn play_boxown(self: Box<Self>) { // 注意这里 println!("I'am play_boxown of Point."); } } fn main() { let mut boxed: Box<Point> = Box::new(Point{x: 10, y: 20}); boxed.play_ref(); boxed.play_mutref(); boxed.play_boxown(); // boxed.play_own(); // play_boxown()和 play_own() 只能同时打开一个 }
注意示例中, play_boxown() 和 play_own() 只能同时打开一个,这是为什么呢?你思考一下。
结构体中的Box
Box<T> 作为类型,当然是可以出现在struct里的,你可以看一下示例。
struct Point { x: u32, y: u32, } struct Triangle { one: Box<Point>, // 三个字段类型都是 Box<Point> two: Box<Point>, three: Box<Point>, } fn main() { let t = Triangle { one: Box::new(Point { x: 10, y: 10, }), two: Box::new(Point { x: 20, y: 20, }), three: Box::new(Point { x: 10, y: 20, }), }; }
Box<dyn trait>
回忆 第 10 讲 的trait object,它代表一种类型,这种类型可以代理一批其他的类型。但是 dyn trait 本身的尺寸在编译期是未知的,所以 dyn trait 的出现总是要借助于引用或智能指针。而 Box<dyn trait> 是最常见的,甚至比 &dyn trait 更常见。原因就是 Box<dyn Trait> 拥有所有权,这就是 Box<T> 方便的地方,而 &dyn Trait 不拥有所有权,有的时候就没那么方便。
我们来看使用 Box<dyn trait> 做函数参数的一个示例。
struct Atype; struct Btype; struct Ctype; trait TraitA {} impl TraitA for Atype {} impl TraitA for Btype {} impl TraitA for Ctype {} fn doit(x: Box<dyn TraitA>) {} fn main() { let a = Atype; doit(Box::new(a)); let b = Btype; doit(Box::new(b)); let c = Ctype; doit(Box::new(c)); }
这个示例里的 doit() 函数能接收 Atype、Btype、Ctype 三种不同类型的实例。
如果 dyn trait 出现在结构体里,那么 Box<dyn trait> 形式就比 &dyn trait 形式要方便得多。比如,下面示例里的结构体字段类型是 Box<dyn TraitA>,能正常编译。
struct Atype; struct Btype; struct Ctype; trait TraitA {} impl TraitA for Atype {} impl TraitA for Btype {} impl TraitA for Ctype {} struct MyStruct { x: Box<dyn TraitA> // 结构体的字段类型是 Box<dyn TraitA> } fn main() { let a = Atype; let t1 = MyStruct {x: Box::new(a)}; let b = Btype; let t2 = MyStruct {x: Box::new(b)}; let c = Ctype; let t3 = MyStruct {x: Box::new(c)}; }
而下面这个示例,结构体字段类型是 &dyn TraitA,就没办法通过编译。
struct Atype;
struct Btype;
struct Ctype;
trait TraitA {}
impl TraitA for Atype {}
impl TraitA for Btype {}
impl TraitA for Ctype {}
struct MyStruct {
x: &dyn TraitA // 结构体字段类型是 &dyn TraitA
}
报错如下:
error[E0106]: missing lifetime specifier
--> src/lib.rs:12:8
|
12 | x: &dyn TraitA
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
11 ~ struct MyStruct<'a> {
12 ~ x: &'a dyn TraitA
|
这个错误涉及到第20讲引用的生命期的概念,现在我们不去深究。
Box<T> 智能指针的内容就讲到这里,下面我们看另一种智能指针 Arc<T>。
Arc<T>
Box<T> 是单所有权或独占所有权模型的智能指针,而 Arc<T> 是共享所有权模型的智能指针,也就是多个变量可以同时拥有一个资源的所有权。和 Box<T> 一样, Arc<T> 也会保证被包装的内容被分配在堆上。
clone
Arc的主要功能是和 clone() 配合使用。在Arc实例上每一次新的 clone() 操作,总是会将资源的引用数+1,而保持原来那一份资源不动,这个信息记录在Arc实例里面。每一个指向同一个资源的Arc实例走出作用域,就会给这个引用计数-1。直到最后一个Arc实例消失,目标资源才会被销毁释放。你可以看一下示例。
use std::sync::Arc; #[derive(Debug)] // 这里不需要目标type实现Clone trait struct Point { x: u32, y: u32, } impl Point { fn play(&self) { println!("I'am a method of Point."); } } fn main() { let arced: Arc<Point> = Arc::new(Point{x: 10, y: 20}); let another_arced = arced.clone(); // 克隆引用 println!("{:?}", arced); // 打印一份值 println!("{:?}", another_arced); // 打印同一份值 arced.play(); another_arced.play(); let arc3_ref = &another_arced; arc3_ref.play(); } // 输出 Point { x: 10, y: 20 } Point { x: 10, y: 20 } I'am a method of Point. I'am a method of Point. I'am a method of Point.
我们可以看到,相比于 Box<T>, Arc<T> 的clone不要求T实现了Clone trait。 Arc<T> 的克隆行为只会改变Arc的引用计数,而不会克隆里面的内容。由于不需要克隆原始资源,所以性能是很高的。
类似于 Box<T>, Arc<T> 也实现了Deref、Drop、Clone等trait。因此, Arc<T> 也可以符合人类的习惯,访问到里面类型T的方法。 Arc<T> 的不可变引用 &Arc<> 也可以顺利调用到T上的方法。
Arc
和 Box<T> 一样,Arc也可以用在方法中的self参数上面,作为所有权self的一个变体形式。
我们继续扩展上面的代码,你可以看一下扩展后的样子。
use std::sync::Arc; #[derive(Debug)] struct Point { x: u32, y: u32, } impl Point { fn play_ref(&self) { println!("I'am play_ref of Point."); } fn play_mutref(&mut self) { println!("I'am play_mutref of Point."); } fn play_own(self) { println!("I'am play_own of Point."); } fn play_boxown(self: Box<Self>) { // 注意这里 println!("I'am play_boxown of Point."); } fn play_arcown(self: Arc<Self>) { // 注意这里 println!("I'am play_arcown of Point."); } } fn main() { let mut boxed: Box<Point> = Box::new(Point{x: 10, y: 20}); boxed.play_ref(); boxed.play_mutref(); boxed.play_boxown(); // boxed.play_own(); // play_boxown()和 play_own() 只能同时打开一个 let arced: Arc<Point> = Arc::new(Point{x: 10, y: 20}); arced.play_ref(); // arced.play_mutref(); // 不能用 // arced.play_own(); // 不能用,Arc<T> 中的T无法被移出 arced.play_arcown(); } // 输出 I'am play_ref of Point. I'am play_mutref of Point. I'am play_boxown of Point. I'am play_ref of Point. I'am play_arcown of Point.
通过这个示例我们可以看到,不能通过 Arc<> 直接修改里面类型的值,也不能像 Box<> 的解引用操作那样,把里面的内容从 Arc<> 中移动出来。你可以试着打开示例里注释掉的几行看看Rustc小助手的提示信息。
Arc<dyn trait>
我们还可以把前面 Box<dyn trait> 的示例改编成 Arc<T> 的。
use std::sync::Arc; struct Atype; struct Btype; struct Ctype; trait TraitA {} impl TraitA for Atype {} impl TraitA for Btype {} impl TraitA for Ctype {} struct MyStruct { x: Arc<dyn TraitA> } fn main() { let a = Atype; let t1 = MyStruct {x: Arc::new(a)}; let b = Btype; let t2 = MyStruct {x: Arc::new(b)}; let c = Ctype; let t3 = MyStruct {x: Arc::new(c)}; }
值的修改
多所有权条件下,怎么修改Arc里面的值呢?答案是不能修改。虽然 Arc<T> 是拥有所有权的,但 Arc<T> 不提供修改T的能力,这也是 Arc<T> 和 Box<T> 不一样的地方。后面我们在并发编程部分会讲到Mutex、RwLock等锁。想要修改Arc里面的内容,必须配合这些锁才能完成,比如 Arc<Mutex<T>>。
其实很好理解,共享所有权的场景下,如果任意一方能随意修改被包裹的值,那就会影响其他所有权的持有者,整个就乱套了。所以要修改的话必须引入锁的机制。
Arc<T> 与不可变引用&的区别
首先,它们都是共享对象的行为,本质上都是指针。但 Arc<T> 是共享了所有权模型,而&只是共享借用模型。共享借用模型就得遵循借用检查器的规则——借用的有效性依赖于被借用资源的scope。对于这个的分析是非常复杂的。而所有权模型是由自己来管理资源的scope,所以处理起来比较方便。
小结
这节课我们一起学习了最常用的两个智能指针: Box<T> 和 Arc<T>。其实Rust里还有很多智能指针,比如 Rc、Cell、RefCell 等等,每一种智能指针类型都有自己的特点。但是不管怎样,学习的方法都是一样的,那就是从所有权的视角去分析研究。你可以在后面遇到那些类型的时候,再根据这节课提供的方法去研究它们。
后面我们会看到,在智能指针的加持下,Rust代码写起来会非常流畅,可以和Java不相上下。再结合Rust强大的类型系统建模能力,等你写得熟练之后,在中大项目中,使用Rust甚至会有超越Python的开发效率。
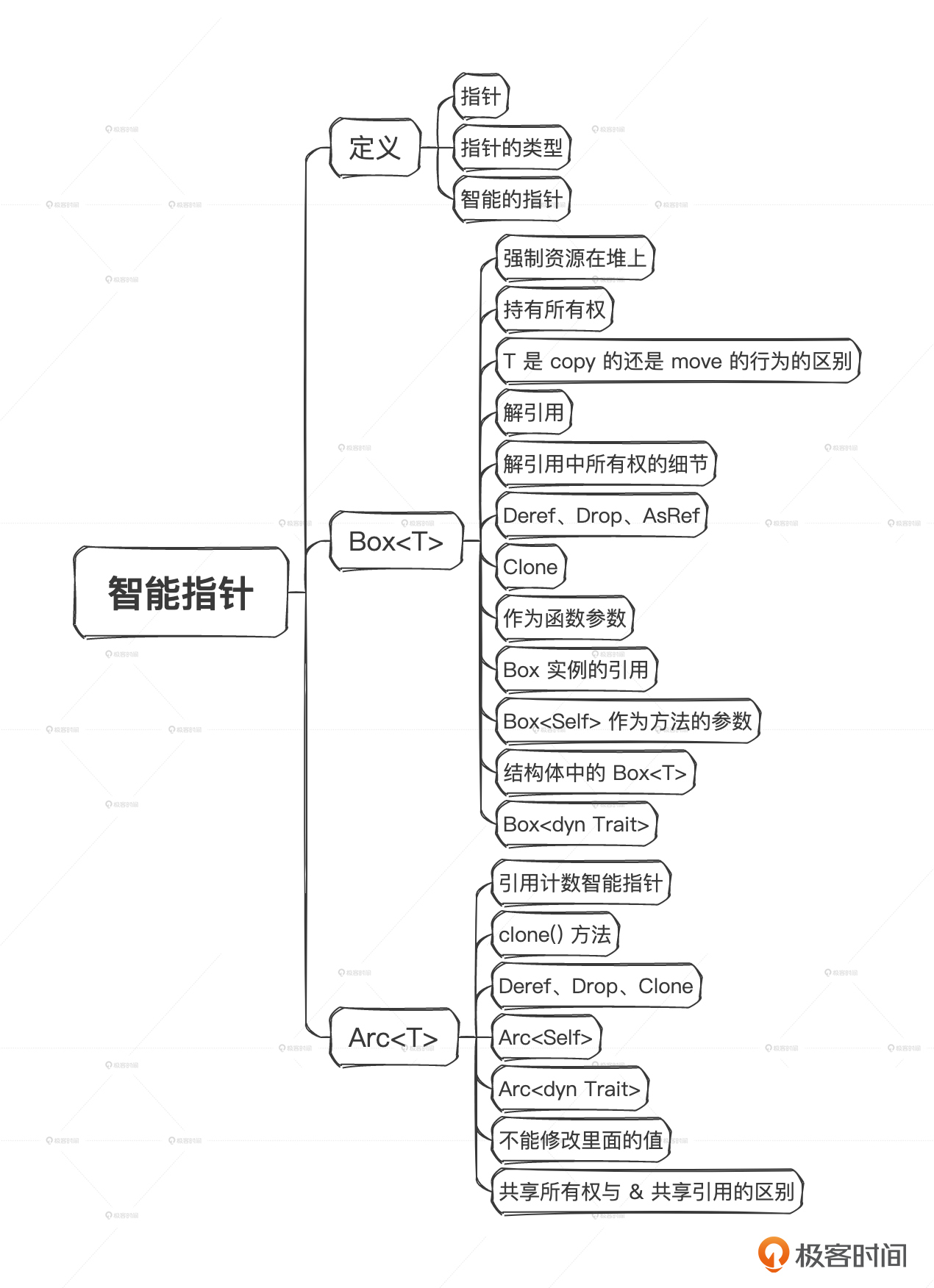
思考题
你试着打开示例中的这两句,看看报错信息,然后分析一下是为什么?
// arced.play_mutref(); // 不能用
// arced.play_own(); // 不能用
欢迎你把自己的分析分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
独立王国:初步了解Rust异步并发编程
你好,我是Mike。从今天开始,我们会用几节课的时间系统学习Rust异步并发编程。
和其他语言不大一样的是,异步 Rust(async Rust)相当于Rust世界里的一块儿新的王国,这个王国有一定的独立性,有它突出的特点。当然,独立并不代表封闭,我们前面所有的知识和经验仍然能顺利地在这个王国里发挥作用。
async rust
从Rust v1.39版本以后,Rust引入了async关键字,用于支持异步编程的工程学体验,使程序员可以用已经习惯了的同步代码书写方式来编写异步代码。
如果你了解过早期的JavaScript语言,你可能会对回调模式以及“回调地狱”有所了解。感兴趣的话,你可以搜索“回调地狱”这个关键词,看看它是如何产生的,以及可以用什么方式去解决。
JavaScript在ECMAScript 2017版本中引入了 async/await 关键字组合,用于改进JavaScript中异步编程体验,从此以后程序员可以用顺序的逻辑书写方式来写出异步执行的代码,而不是那种用回调方式把一段连续的逻辑切割成一小块一小块的。
Rust其实也差不多,它用类似的方式引入了 async/.await 关键字对。如果你对Mozilla公司有所了解的话,就不会感觉奇怪了,Mozilla是互联网标准组织的重要成员,JavaScript之父就在Mozilla公司,参与了JavaScript标准制定的全过程。同时,Mozilla还推出了Rust语言以及WebAssembly字节码规范。
async 函数和块(代码片段)
在Rust中,用上async的函数长这样:
async fn foo() {
}
也就是在原来的fn前加上 async 修饰。另外,还有所谓的 async 块,也就是直接在 async 后面加花括号。
fn foo() {
async {
// 这就是async块
};
}
fn foo() {
async move {
// 加move,类似闭包,明确标识把用到的环境变量移动进来
};
}
上面的函数是可以编译通过的,但是这样写本身会有一些问题。
提示:
futures do nothing unless you `.await` or poll them
翻译出来就是:futures不做任何事情,除非你用 .await 或轮询它们。
Rust中,async函数或块会被视作一个Future对象,类似于JS里的Promise,async 关键字只是用来定义这个Future对象,定义好的这片异步代码并不会自动执行,而是需要和async配对的 .await 去驱动它才会执行。
比如像下面这样:
fn foo() {
let a = async {};
a.await; // 用.await驱动异步块
}
// 或者更紧凑的写法
fn foo() {
async {}.await;
}
但是,上述代码是没办法通过编译的,会报这个错。
error[E0728]: `await` is only allowed inside `async` functions and blocks
它提示说, await 关键字只能在async块或函数里使用。
于是得改成这样才行:
async fn foo() {
let a = async {};
a.await;
}
这里我们看到两条规则。
- 用async定义异步代码,用
.await驱动执行。 - 但是
.await又只能在async块中调用。
细心的你可能一下子就推理出来了,这不就是鸡和蛋的问题吗?那么第一个最外层的 async 代码块或函数如何被调用呢?
我们知道,Rust的程序都是从main函数开始执行的。
fn main() { }
即使是异步代码,也不能破坏这个规则。
我们试着这样写:
async fn main() { // 在main函数前加一个async修饰 let a = async {}; a.await; }
会报错:
error[E0752]: `main` function is not allowed to be `async`
Rust 明确规定了,main函数前不能加async修饰。也就是说,只能写成这种形式。
fn main() { let a = async {}; a.await; }
但是前面又说过了, .await 只能写在async代码块或函数里。我们进入了一个两难的境地。如果就在目前这个体系里面寻找解决方案的话,那只能原地打转。
这里必然要引入一种外部驱动机制。比如,有一个辅助函数,它可以接收Future,并驱动它,而不需要使用 .await。像下面这样就行了。
fn main() { let a = async {}; block_on(a); // 辅助驱动函数 block_on }
那么,这个 block_on() 到底是什么呢?
这个 block_on() 可不是一个普通的函数,它必须是一个运行时(Runtime)的入口。在它下面,蕴藏着一整套运行时机制。
到目前为止,我们已经知道,仅仅利用我们之前学到的Rust知识,还驱动不了异步代码,必须要借助于一种新的叫做运行时(Runtime)的机制才能处理。
目前Rust标准库中还没有内置一个官方的异步Runtime,不过Rust生态中有很多第三方的Runtime实现库,比如tokio、async-std等。而其中tokio应用最为广泛。 通过几年的时间,tokio在第三方异步Runtime的激烈竞争中胜出,可以说它现在已经成为了Rust生态中异步运行时事实上的标准。
我们下面就开始讲解这个运行时机制。
异步运行时是什么?
异步运行时是一个库,这个库包含一个响应器(reactor)和一个或多个执行器(executor)。它需要处理哪些事情呢?
- 执行异步代码。
- 遇到
.await的时候,判断能不能获取到结果。如果不能,CPU不会一直阻塞等,而是缓存当前任务的状态,然后将当前任务挂起,放到内部一个任务池中,同时向OS注册要监听等待的外部事件。 - 询问或执行其他任务。如果所有任务都暂时没有进展,就会进入一个空闲(idle)状态,不会使CPU忙等待。
- 只要某个任务对应所监听到的信号来了,也就是说有结果返回了,就会把对应的任务重新捡起来,并从缓存中恢复暂停前的状态,继续往下执行。从代码上看,就是从上一个
.await后面的代码继续往下执行。 - 遇到下一个
.await,就重复第1步~第4步。 - 直到这个异步代码(函数)执行完毕,完成操作或返回结果。
总结起来,就是这6项任务。
- 异步代码的执行;
- 任务的暂停;
- 状态的缓存;
- 外部事件的监听注册;
- 外部信号来了后,唤醒对应的任务,恢复任务状态;
- 多个任务间的调度。
总之,Rust异步运行时要干的事情还不少。要设计一个高效的异步运行时是一件相当有技术挑战的工作。后面我们会以tokio为例来介绍Rust中的异步编程。
tokio异步编程
下面我们来熟悉一下基于tokio runtime的代码范例。
引入依赖
首先,你得在Cargo.toml中引入tokio依赖。
tokio = { version = "1", features = ["full"] }
main函数
然后,我们把tokio提供的一个属性宏标注在main函数上面,这样main函数前就可以加async修饰了。
像下面这样:
#[tokio::main] // 这个是tokio库里面提供的一个属性宏标注 async fn main() { // 注意 main 函数前面有 async println!("Hello world"); }
这个 #[tokio::main] 做的事情其实就是把用 async 修饰的 main 函数展开,展开会类似下面这个样子:
fn main() { tokio::runtime::Builder::new_multi_thread() .enable_all() .build() .unwrap() .block_on(async { // 注意这里block_on,里面是异步代码 println!("Hello world"); }) }
也就是在main函数里构建一个Runtime实例,第二行代码的意思是 tokio 库下 Runtime 模块的 Builder 类型里的 new_multi_thread() 函数,整个路径用 :: 号连接, :: 也叫路径符。这个函数创建的是多线程版本的 Runtime 实例。
.enable_all() 用于打开默认所有配置, .build() 用于真正创建实例,它返回一个用Result包起来的结果, .unwrap() 把这个 Result 解开,把Runtime实例拿出来,然后在这个实例上调用 .block_on() 函数。整个过程用的是 链式调用风格,这个风格在其他语言中也很普遍,只要遵循前一个函数调用返回自身或者新的对象即可。
block_on() 会执行异步代码,这样就把异步代码给加载到这个Runtime实例上并驱动起来了。
tokio还可以基于当前系统线程创建单线程的Runtime,你可以看一下示例。
#[tokio::main(flavor = "current_thread")] // 属性标注里面配置参数 async fn main() { println!("Hello world"); }
展开后,是这个样子的:
fn main() { tokio::runtime::Builder::new_current_thread() // 注意这一句 .enable_all() .build() .unwrap() .block_on(async { println!("Hello world"); }) }
单线程的Runtime由 Builder::new_current_thread() 函数创建,代码的其他部分和多线程Runtime都一样。
代码示例
这里,我们先看几个例子,来了解一下基于tokio的代码长什么样子。
文件写
下面的例子展示了如何基于tokio做文件的写操作。
use tokio::fs::File; use tokio::io::AsyncWriteExt; // 引入AsyncWriteExt trait async fn doit() -> std::io::Result<()> { let mut file = File::create("foo.txt").await.unwrap(); // 创建文件 file.write_all(b"hello, world!").await.unwrap(); // 写入内容 Ok(()) } #[tokio::main] async fn main() { let result = doit().await; // 注意这里的.await }
文件读
下面的例子展示了如何基于tokio做文件的读操作。
use tokio::fs::File; use tokio::io::AsyncReadExt; // 引入AsyncReadExt trait async fn doit() -> std::io::Result<()> { let mut file = File::open("foo.txt").await.unwrap(); // 打开文件 let mut contents = vec![]; // 将文件内容读到contents动态数组里面,注意传入的是可变引用 file.read_to_end(&mut contents).await.unwrap(); println!("len = {}", contents.len()); Ok(()) } #[tokio::main] async fn main() { let result = doit().await; // 注意这里的.await // process }
可以看到,Rust的异步代码和JavaScript的异步代码非常类似,只不过JavaScript的 await 关键字是放在语句前面的。
定时器操作
下面的例子展示了如何基于tokio做定时器操作。
use tokio::time; use std::time::Duration; #[tokio::main] async fn main() { // 创建Interval实例 let mut interval = time::interval(Duration::from_millis(10)); // 滴答,立即执行 interval.tick().await; // 滴答,这个滴答完成后,10ms过去了 interval.tick().await; // 滴答,这个滴答完成后,20ms过去了 interval.tick().await; }
上面示例里的时间段, Duration::from_millis(10) 表示创建一个10ms的时间段,我们在其他语言中更多是习惯直接传入一个数字,比如传 10000 进去,默认单位是 us。但是前面我们说过,Rust中会尽可能地类型化,因此这里定义了一个Duration类型,它可以接收来自s、ms、us等单位的数值来构造时间段。在这点上,Java和Rust是比较像的。
tokio组件
tokio发展到现在,已经是一个功能丰富、机制完善的Runtime框架了。它针对异步场景把Rust标准库里对应的类型和设施都重新实现了一遍。具体包含6个部分。
- Runtime设施组件:你可以自由地配置创建基于系统单线程的Runtime和多线程的Runtime。
- 轻量级任务 task:你可以把它理解成类似Go语言中的Goroutine这种轻量级线程,而不是操作系统层面的线程。
- 异步输入输出(I/O):网络模块net、文件操作模块fs、signal模块、process模块等。
- 时间模块:定时器Interval等。
- 异步场景下的同步原语:channel、Mutex锁等等。
- 在异步环境下执行计算密集型任务的方案
spawn_blocking等等。
通过对这些基础设施的重新实现,tokio为Rust异步编程的生态打下了坚实的基础,通过几年的发展,一些上层建筑蓬勃发展起来了。比如:
- Hyper:HTTP 协议Server和Client的实现
- Axum:Web开发框架
- async-graphql:GraphQL开发框架
- tonic:gRPC框架的Rust实现
- ……
tokio底层机制
下面我们来看一下tokio的底层魔法到底是什么?
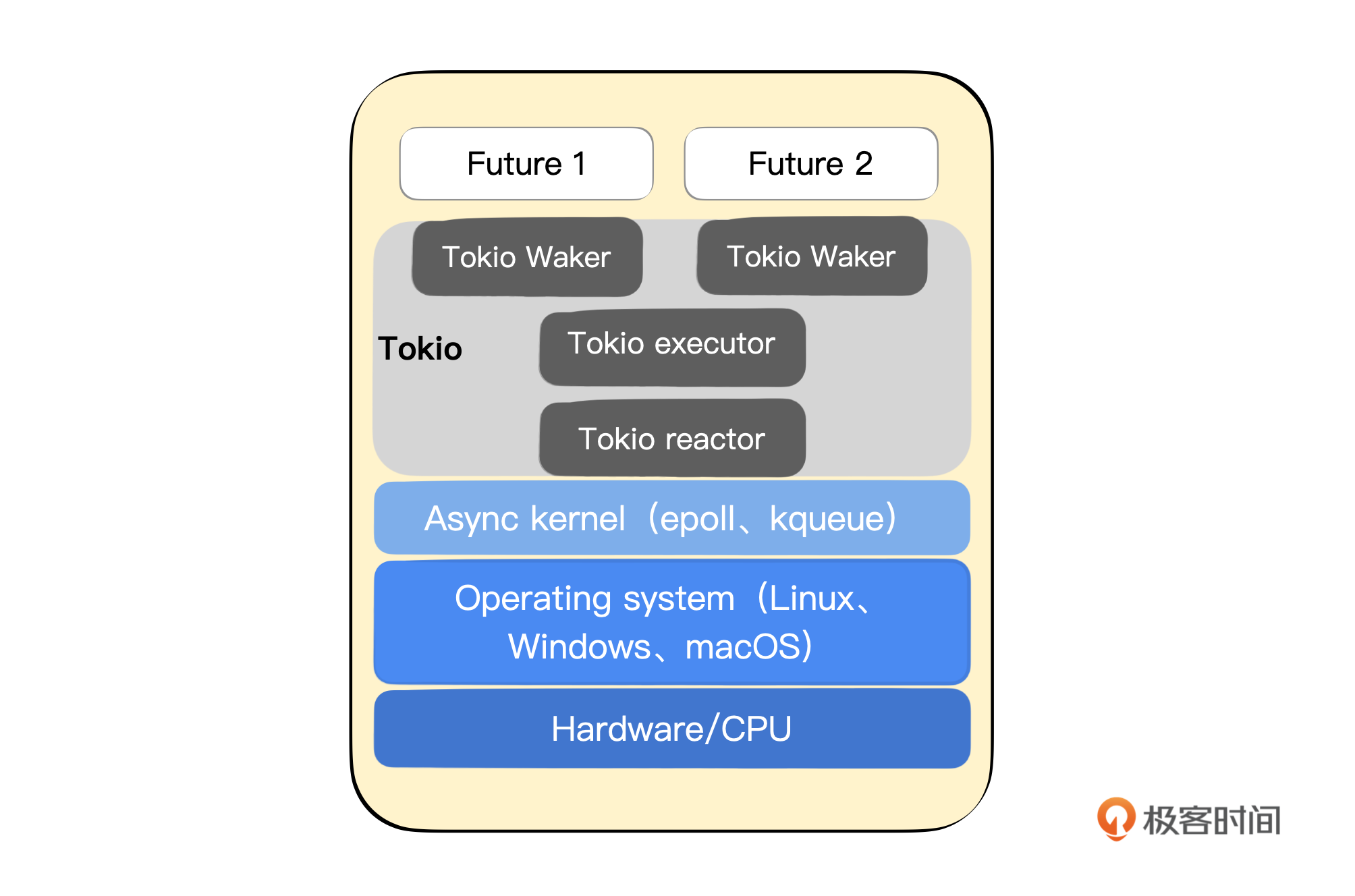
最底层是硬件、CPU等。在其上是操作系统,Linux、Windows、macOS 等。不同的操作系统会提供不同的异步抽象机制,比如 Linux 下有 epoll,macOS下有kqueue。
Tokio的异步Runtime能力实际正是建立在操作系统的这些异步机制上的。Tokio的reactor用来接收从操作系统的异步框架中传回的消息事件,然后通知 tokio waker 把对应的任务唤醒,放回 tokio executor 中执行。每一个任务会被抽象成一个Future来独立处理,而每一个Future在Rust中会被处理成一个结构体,用状态机的方式来管理。Tokio中还实现了对这些任务的安排调度机制。
注:官方的 async book 有对这个专题更深入的讲解:不过这本异步书写得偏难,并不适合新手,有兴趣的话可以翻阅一下。
task:轻量级线程
tokio提供了一种合作式(而非抢占式)的任务模型:每个任务task都可以看作是一个轻量级的线程,与操作系统线程相对。操作系统默认的线程机制需要消耗比较多的资源,一台普通服务器上能启动的总线程数一般最多也就几千个。而tokio的轻量级线程可以在一台普通服务器上创建上百万个。
M:N模型
tokio的这个模型是一种M:N模型,M表示轻量级线程的数量,N表示操作系统线程的数量。也就是说,它实际是将所有的轻量级线程映射到具体的N个操作系统线程上来执行,相当于在操作系统线程之上抽象了一层,这层抽象是否高效正是衡量一个Runtime好坏的核心标准。其中,操作系统线程数量N是可以由开发者自行配置的,最常用的默认配置是一个机器上有多少CPU逻辑处理器核,N就等于多少。
合作式
同时,tokio的轻量级线程之间的关系是一种合作式的。合作式的意思就是同一个CPU核上的任务大家是配合着执行(不同CPU核上的任务是并行执行的)。我们可以设想一个简单的场景,A和B两个任务被分配到了同一个CPU核上,A先执行,那么,只有在A异步代码中碰到 .await 而且不能立即得到返回值的时候,才会触发挂起,进而切换到任务B执行。
当任务B碰到 .await 时,又会回去检查一下任务A所await的那个值回来没有,如果回来了就唤醒任务A,从之前那个 .await 后面的语句继续执行;如果没回来就继续等待,或者看看能不能从其他核上拿点任务过来执行,因为此时任务A和任务B都在等待await的值回来。任何一个task里await的值回来后(会由操作系统向tokio通知一个事件),tokio就会唤醒对应的task继续往下执行。
也就是说,在一个task没有遇到 .await 之前,它是不会主动交出这个CPU核的,其他task也不能主动来抢占这个CPU核。所以tokio实现的这个模型叫做合作式的。和它相对的,Go语言自带的Runtime实现的Goroutine是一种抢占式的轻量级线程。
非阻塞
从前面代码的示范及讲解可以看到,在程序员这个视角看来,代码层面的效果是一个task(一段异步代码)遇到 .await 时,看起来就好像是被阻塞住了,会等待请求结果的返回。而从tokio底层的运行和调度机制来看,它又是非阻塞的。非阻塞的意思是,一个轻量级线程task的“卡住”,不会把用来承载它的操作系统线程给真正地卡住,OS线程被调度了新的任务执行。这样,CPU资源就没有被浪费。
这个task之间的调度工作是在tokio内部自动完成的,对程序员来说是不可见的。这样就带来了巨大的好处,程序员写异步并发代码,就跟之前写同步代码基本一样,顺着将逻辑写下去就行了。而不会因为去适应异步回调而把代码逻辑打碎分散到文件的各个地方。所以,tokio的task在真正执行的时候是非阻塞的,不会对系统资源造成浪费。
下面我们来看一下如何创建tokio task,这需要使用 task::spawn() 函数。
use tokio::task; #[tokio::main] async fn main() { task::spawn(async { // 在这里执行异步任务 }); }
在这个示例里,main函数里面创建了一个新的task,用来执行具体的任务。我们需要知道,tokio管理下的 async fn main() {} 本身就是一个task,相当于在main task中,创建了一个新的task来执行。这里,main task就是父task,新创建的这个task是子task。
那聪明的你可能要问了,这两个task之间的生存关系是怎样的呢?它们其实是没有关系的。在tokio中,子task的生存期有可能超过父task的生存期,也就是父task执行结束了,但子task还在执行。如果在父task里要等待子task执行完,再结束自己,保险的做法是用 JoinHandler。
注:在main函数中有更多细节,如果main函数所在的task先结束了,会导致整个程序进程退出,有可能会强制杀掉那些新创建的子task。
use tokio::task; #[tokio::main] async fn main() { // 在这里执行异步任务 let task_a = task::spawn(async { "hello world!" }); // ... // 等待子任务结束,返回结果 let result = task_a.await.unwrap(); assert_eq!(result, "hello world!"); }
JoinHandler是什么意思呢?这个新概念跟task的管理相关。我们在main task中里创建一个新task后, task::spawn() 函数实际有一个返回值,它返回一个handler,这个handler可以让我们在main task里管理新创建的task。这个handler也可以用来指代这个新的task,相当于给这个task取了一个名字。比如示例里,我们就把这个新的任务命名为task_a,它的类型是 JoinHandler。在用 spawn() 创建task_a后,这个新任务就 立即执行。
task_a.await 会返回一个Result,所以上面代码中,需要加一个 unwrap() 把task_a真正的返回内容解包出来。至于对task的 .await 为什么会返回一个Result,而不是直接返回异步任务的返回值本身,是因为task里有可能会发生panic。你可以看一下例子。
use tokio::task; #[tokio::main] async fn main() { let task_a = task::spawn(async { panic!("something bad happened!") }); // 当task_a里面panic时,对task handler进行.await,会得到Err assert!(task_a.await.is_err()); }
由于task可能会panic,所以就得对task的返回值用Result包一层,这样方便在上一层的task里处理这种错误。 在Rust中,只要过程中有可能返回错误,那就果断用Result包一层作为返回值,这是典型做法。
有了 JoinHandler,我们可以方便地创建一批新任务,并等待它们的返回值。你可以看一下示例。
use tokio::task; async fn my_background_op(id: i32) -> String { let s = format!("Starting background task {}.", id); println!("{}", s); s } #[tokio::main] async fn main() { let ops = vec![1, 2, 3]; let mut tasks = Vec::with_capacity(ops.len()); for op in ops { // 任务创建后,立即开始运行,我们用一个Vec来持有各个任务的handler tasks.push(tokio::spawn(my_background_op(op))); } let mut outputs = Vec::with_capacity(tasks.len()); for task in tasks { outputs.push(task.await.unwrap()); } println!("{:?}", outputs); } // 输出 Starting background task 1. Starting background task 2. Starting background task 3.
上面示例里,我们用 tasks 这个动态数组持有3个异步任务的handler, 它们是并发执行的。然后对 tasks 进行迭代,等待每个task执行完成,并且搜集任务的结果放到 outputs 动态数组里。最后打印出来。
可以看到,在tokio中创建一批任务并发执行非常简单,循环调用 task::spawn() 就行了,并且还能对创建的任务进行管理。
哪些操作要加 .await?
到目前为止,我们已经初步感知到了tokio的强大能力,确实很好用,也很直观。但是我们还有一个疑惑,在写异步代码的时候,我怎么知道哪些地方该加 .await,哪些地方不该加呢?
一个总体的原则是, 涉及到I/O操作的,都可以加,因为tokio已经帮我们实现了一份异步的对应于Rust标准库的I/O实现。最常见的I/O操作就是网络I/O、磁盘I/O等等。具体来说,有几大模块。
- net模块:网络操作;
- fs模块:文件操作;
- 定时器操作:Interval、sleep等函数;
- channel:四种管道 oneshot、mpsc、watch、broadcast;
- signal模块:系统信号处理;
- process模块:调用系统命令等。
具体可以查看 tokio API。在查看API文档的时候,只要那个接口前面有 async 关键字修饰,那么使用的时候就需要加 .await。比如, tokio::fs::read() 的定义就是这样的:
pub async fn read(path: impl AsRef<Path>) -> Result<Vec<u8>>
而像其他的一些数据结构的基本操作,比如 Vec<T>、 HashMap<K, V> 的操作等,由于它们都是在内存里执行,它们的接口前面也没有 async 关键字修饰,所以不需要也不能加 .await。
小结
这节课我们一起学习了Async Rust和tokio相关的基本概念。Async Rust在整个Rust的体系中,相对于std Rust来讲是一片新的领地。
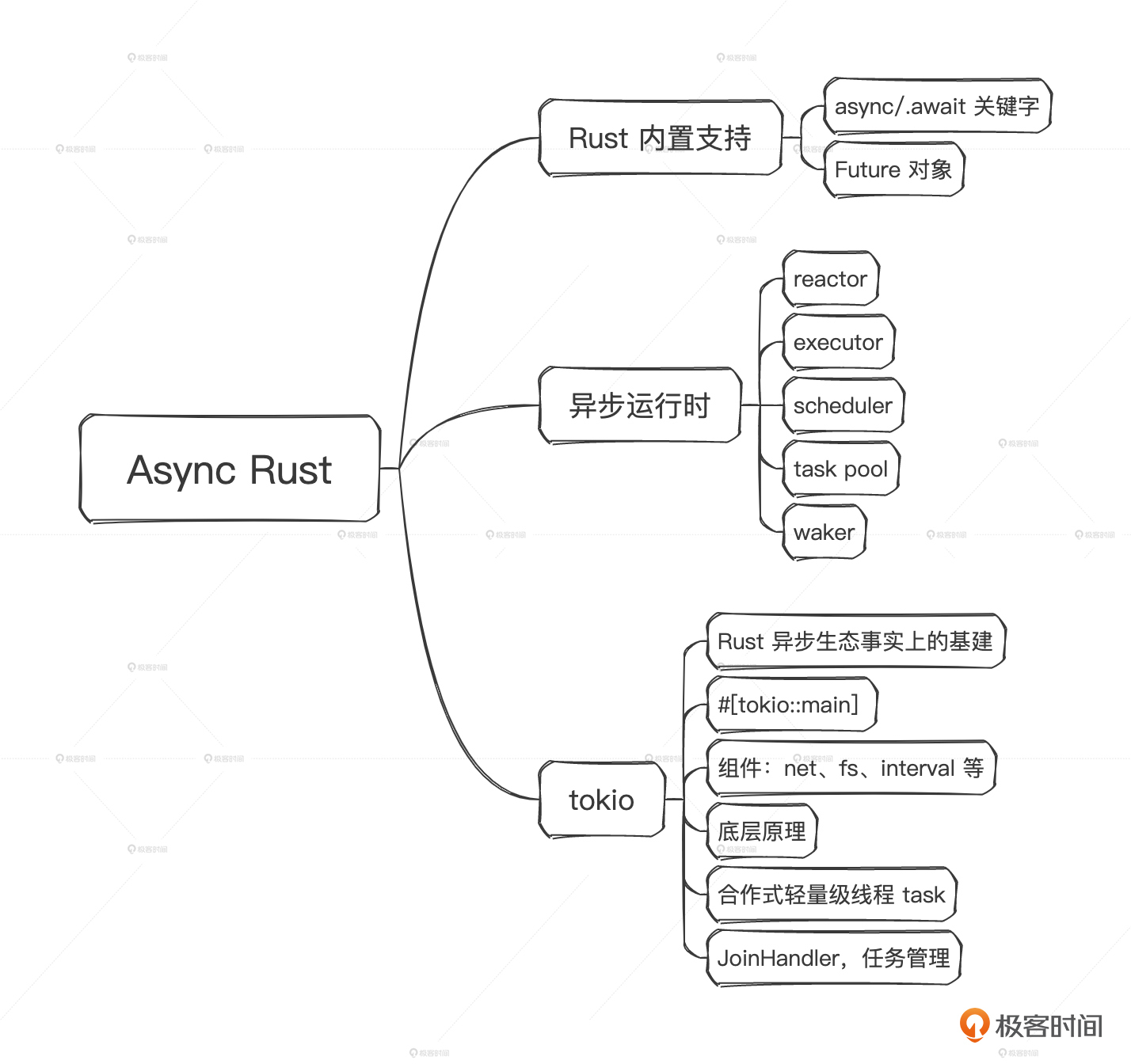
Rust中的 async 代码具有 传染性,也就是说一个函数如果要调用一个async函数的话,它本身也需要是async函数。Rust在语言层面提供了 async/.await 语法的支持,但是其并没有提供一个官方的异步运行时,来对异步代码的执行进行驱动。而tokio是整个Rust生态中经历过激烈竞争后的异步运行时胜出者,具有强大的功能、丰富的特性和广泛的使用度。
tokio提供了一套轻量级线程模型,方便程序员使用Rust进行大规模并发程序开发,特别适合高性能Web服务器领域,也适合处理一般的异步业务。
思考题
为什么我们要把async Rust叫做“独立王国”呢?欢迎你把自己的思考分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
tokio实战:编写一个网络命令行程序
你好,我是Mike,上一节课我们了解了Rust异步编程和tokio的基础知识,今天我们就来一起用tokio做一个小应用。
准备阶段
我们常常需要知道远程服务器上的一些信息,这有一些现成的工具可以做到。我们来试一下如何使用tokio实现这一功能。
目标: 编写一个获取服务器时间的命令行程序。
任务分解:
- 命令行:这个工具取名为 getinfo, 参数格式是
getinfo {ip},就是在 getinfo 后接IP地址,获取服务器时间。 - tcp server:监听 8888 端口,获取从客户端来的请求,然后获取服务器本地时间,返回。
- tcp client:连接服务端地址
ip:port,向服务端发送获取服务器时间指令。 - 测试。
实现
下面我们开始实现。
创建项目
我们打开终端或者IDE中的Terminal,执行:
cargo new --bin getinfo
命令行雏形
Rust标准库中实际已经有获取命令行参数的功能, std::env 提供了一种获取命令行参数的方法 std:: env:: args(),可以将命令行参数转换成一个迭代器,通过 for 循环就可以遍历所有命令行参数,当然也可以使用迭代器上的 .nth() 直接定位到某一个参数。比如:
let addr = env::args()
.nth(1)
.unwrap_or_else(|| "127.0.0.1:8888".to_string());
有了这个功能,我们就可以得到命令行的初始版本。
use std::env; fn main() { let addr = env::args() .nth(1) .unwrap_or("127.0.0.1:8888".to_string()); println!("{}", addr); }
检查一下Cargo.toml中的配置,我们的应用名字应该叫 getinfo。
[package]
name = "getinfo"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
执行 cargo build 编译,会出现 target 目录。
Cargo.lock Cargo.toml src/ target/
执行 cargo run 或 ./target/debug/getinfo。可以得到输出 127.0.0.1:8888。
而执行 cargo run -- 127.0.0.1:8000 或 ./target/debug/getinfo 127.0.0.1:8000,可以得到输出 127.0.0.1:8000。
这里我们来分析一下这个命令行的形式。
./target/debug/getinfo ip_address
命令行参数从左到右按序号从0开始计数,上面命令中, ./target/debug/getinfo 序号为 0, ip_address 部分序号就是 1,如果后面还有其他参数,那么序号依次递增。所以你就可以理解为什么我们上面的代码中,使用 .nth(1) 取IP地址的信息。
标准库中命令行相关的功能虽然比较初级,但是对于我们的例子来说,已经够用了。Rust生态中有个非常好用的写命令行的库: clap,如果你想写一个功能丰富的命令行程序,可以去尝试一下这个 clap。
下面我们就要开始 tokio tcp server 的创建。
添加依赖
先加入tokio的依赖,在项目目录下执行命令。
cargo add tokio --features full
cargo add tokio-util --features full
cargo add futures
cargo add bytes
执行完这几个添加依赖的命令后,Cargo.toml文件现在看起来是类似下面这个样子:
mike@LAPTOP-04V0EV33:~/works/jikeshijian/getinfo$ cat Cargo.toml
[package]
name = "getinfo"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
bytes = "1.5.0"
futures = "0.3.29"
tokio = { version = "1.33.0", features = ["full"] }
tokio-util = { version = "0.7.10", features = ["full"] }
cargo add 工具为我们准确配置了具体依赖库的版本号和特性。
基于tokio实现tcp server
我们的tcp server实际要干下面几件事儿。
- 接收tcp client的连接,每一个新连接创建一个新的task。
- 读取tcp client发过来的指令数据。
- 根据指令,获取服务器本地的时间信息。
- 将得到的信息字符串写入socket,返回给客户端。
use std::env; use tokio::io::{AsyncReadExt, AsyncWriteExt}; use tokio::net::TcpListener; use tokio::process::Command; #[tokio::main] async fn main() -> Result<(), Box<dyn std::error::Error>> { let addr = env::args() .nth(1) .unwrap_or_else(|| "127.0.0.1:8888".to_string()); println!("Listening on: {}", addr); let listener = TcpListener::bind(&addr).await?; // 注意这里是一个无条件循环,表明始终处于服务状态 loop { // 等待客户端请求连上来 let (mut socket, _) = listener.accept().await?; // 来一个客户端连接,创建一个对应的新任务 tokio::spawn(async move { // 分配一个缓冲存 let mut buf = [0; 1024]; let mut offset = 0; // 循环读,因为不能确保一次能从网络线路上读完数据 loop { // 读操作,返回的n表示读了多少个字节 // 正常情况下,读到数据才会返回,如果没有读到,就会等待 let n = socket .read(&mut buf[offset..]) .await .expect("failed to read data from socket"); // n返回0的情况,是碰到了EOF,表明远端的写操作已断开,这个一定要判断 if n == 0 { // 碰到了EOF就直接返回结束此任务,因为后面的操作没了意义 return; } println!("offset: {offset}, n: {n}"); let end = offset + n; // 转换指令为字符串 if let Ok(directive) = std::str::from_utf8(&buf[..end]) { println!("{directive}"); // 执行指令对应的工作 let output = process(directive).await; println!("{output}"); // 向客户端返回处理结果 socket .write_all(&output.as_bytes()) .await .expect("failed to write data to socket"); } else { // 判断是否转换失败,如果失败,就有可能是网络上的数据还没读完 // 要继续loop读下一波数据 offset = end; } } }); } } async fn process(directive: &str) -> String { if directive == "gettime" { // 这里我们用了unwrap()是因为我们一般确信执行date命令不会失败 // 更可靠的做法是对返回的Result作处理 let output = Command::new("date").output().await.unwrap(); String::from_utf8(output.stdout).unwrap() } else { // 如果是其他指令,我们目前返回 无效指令 "invalid command".to_owned() } }
代码中有详细解释,这里我也补充说明一下。
首先,我们给main函数指定了返回类型: Result<(), Box<dyn std::error::Error>>。错误类型部分是一个用 Box<T> 装盒的trait object,这个trait object是针对标准库中的Error trait的。在这里的意思是,凡是实现了Error trait的类型都可以作为错误类型从main函数中返回。
第12行 let listener = TcpListener::bind(&addr).await?; 行末有一个问号,这是Rust里的问号操作符,意思是.await 得到数据后是一个 Result<>,如果这个 Result<> 是Ok值,那就解开它,返回里面的内容,这个例子里是一个TcpListener实例;而如果这个 Result<> 是Err值,那就直接从函数中返回,不再往下执行。问号操作符在这里起一个防御式编程的作用,能够让流程代码显得更简洁。
注意第15行是一个loop无条件循环,也就是死循环。为什么呢?因为这是个服务端程序,是需要一直跑着的,退出就意味着出问题了。
第17行,监听客户端来的连接,来一个就产生一个 socket 实例。我们看到,在let后面用了模式匹配写法,直接把元组析构了。如果来了多个连接,就会产生多个task,它们之间互不干扰,是并发处理的。
第20行,针对每一个连上的客户端连接,创建一个新的tokio轻量级线程task,来处理对应的任务。继续往下,第22行,可以看到,这个服务端程序为每个连接创建了一个缓冲区,大小是1024字节。从网络上读到的数据会放在这个缓冲区里面。
第25行,再次用了一个循环。因为网络上的数据是呈流的形式过来的,在一次CPU读取它之前,这些数据有可能还没完全到达服务器上面。因此可能需要多次读。读没读够,可以尝试把已经读到数据转换成字符串,看是否能成功来判断(这个判断方式并不严谨,这里主要用于说明流程)。如果成功了,就调用 process() 业务函数来计算。
process()异步函数中使用了 tokio::process::Command 类型来调用系统中的 date 命令,这是一个Linux下的查看系统日期时间的命令,会输出下面这种格式:
Tue Oct 31 14:56:27 CST 2023
注:如果你使用Windows的话,可以找找Windows里的替代命令。
process() 函数会返回这个字符串。
然后,通过同一个 socket,将数据返回给客户端连接: socket.write_all。
在多次读的过程中,要注意偏移量offset的处理。可以看到,代码量虽然不多,但是充满了细节,请你仔细品味一下。
基于tokio实现tcp client
下面我们来看对应的tcp客户端应该怎么实现。
因为我们要马上再创建一个可执行程序,所以默认的 cargo run 命令就不能满足这个需求,它默认只能启动一个二进制文件。我们需要改一下Cargo.toml的配置,在文件中加入一些内容。
[[bin]]
name = "server"
path = "src/server.rs"
[[bin]]
name = "client"
path = "src/client.rs"
然后把src目录下的 main.rs 改成 server.rs,并创建一个新文件 client.rs,代码如下:
use std::env; use tokio::io::{AsyncReadExt, AsyncWriteExt}; use tokio::net::TcpStream; #[tokio::main] async fn main() -> Result<(), Box<dyn std::error::Error>> { let addr = env::args() .nth(1) .unwrap_or_else(|| "127.0.0.1:8888".to_string()); // 连接到服务端 let mut stream = TcpStream::connect(&addr).await?; // 写入指令数据,这是一种最简单的协议. stream.write_all(b"gettime").await?; // 等待tcp server的回复,读取内容 // 这里用动态数组来存储从服务端返回的内容 let mut buf: Vec<u8> = Vec::with_capacity(8128); // 读取的缓冲区 let mut resp = [0u8; 2048]; loop { // 尝试一次读,返回读到的字节数 let n = stream.read(&mut resp).await?; // 将读到的字节合并到buf中去 buf.extend_from_slice(&resp[0..n]); if n == 0 { // 流断掉了 panic!("Unexpected EOF"); } else if buf.len() >= 28 { // like: "Tue Oct 31 14:56:27 CST 2023" // buf 已经填充了足够的内容 break; } else { // buf 中还没有足够多的内容,继续填充... continue; } } // 转换并打印返回的信息 let timeinfo = String::from_utf8(buf)?; println!("{}", timeinfo); Ok(()) }
代码中有详细解释,这里我也做一下补充说明。
第11行,我们使用 TcpStream::connect() 连到服务端上去,注意这点和服务端的监听是不同的。然后第14行,向tcp连接中写入协议指令,这里就是简单的字节串: b"gettime"。
然后第17行到25行,我们采用了另外一种方式来存储读回来的数据,这里用到了动态数组Vec的 API extend_from_slice(),这个的好处是不需要由自己来维护每次读到的偏移量。第21行,我们再次使用了loop,还是同样的原因,网络上的数据流,我们有可能一次读取不完,需要多次读才行。
第29行是跳出此循环的判断条件,这里是因为我们知道会返回 date 命令的输出结果,它是固定的28个字节的长度。这个条件相当死板,这里也只是起演示作用。
最后就把这个从服务端程序得到的内容打印出来。下面我们开始测试。
测试
编译运行服务端:
cargo run --bin server 或 cargo run --bin server -- 127.0.0.1:8888
编译执行客户端:
cargo run --bin client 或 cargo run --bin client -- 127.0.0.1:8888
查看执行效果。
服务端打印:
Listening on: 127.0.0.1:8888
offset: 0, n: 7
gettime
Tue Oct 31 15:04:08 CST 2023
客户端打印:
Tue Oct 31 15:07:48 CST 2023
这样,我们就成功实现了我们的第一个命令行应用,并完整体验了tokio网络编程。
Frame 层
前面我们的实现,完成了这个应用初步的功能。但是实际上对于我们初学者来说,难度还是比较大,主要体现在4个方面。
- 什么时候要加loop,什么时候不加?
- 两个端的合法性判定条件是什么?能否推广到适用面更广的方式?
- 多次读取的偏移量或缓冲区如何准确维护?
- tcp网络协议的背景知识,服务端与客户端的基本概念,EOF在什么条件下触发等等。
其中前面三条都属于实现层面的细节,我们可以来了解一下产生这些复杂性的原因。
复杂性的来源
我们知道,一个tcp连接就像一个管道一样,里面流过的是一个个的字节,也就是说,它传输的是一个字节流。然而,由于网络本身的复杂性,比如如果服务器在很远的地方,数据有可能要经历过很多次路由器/交换机才能到达,有可能一个字节和下一个字节之间会间隔一段时间才能传过来。这时候,直接在 socket 上做的一次 read,并不能保证就一定读完整了我们想要的内容,有可能只读到了一个片段而已。
这个问题其实属于传输层的问题,不应该让上层业务开发人员来担忧。如果在考虑业务的同时,还要考虑这种底层问题的话,总会感觉施展不开,各种细节会缠得你寸步难行。
比如有两个人A和B,A给B发送两条消息msg_a和msg_b,B 接收消息的时候,一般会希望编程接口每次拿到一个完整的消息,第一次取是msg_a,不多也不少;第二次取是 msg_b,不多也不少。不会担心每次取的时候,消息可能取不完整,需要用一个循环重复取,并且还得把每次取到的片段拼接成一个大的完整的消息内容。
当消息体小的时候,可能问题不明显,当消息体大的时候,比如一次有几兆内容的时候,这个问题其实就无法忽略了。
好在tokio框架已经为我们考虑了这个问题。tokio生态引入了Frame的概念,Frame就是一个帧/框,一个Frame里可以包含一段完整的可预期的信息。相当于它在tcp这一层之上又抽象了一层,封装了具体怎么读取和切分原始的字节序列这个问题。Frame让我们读到的总是业务关心的一批批数据:msg。Frame机制将网络流的原始字节序列转换成Frame序列,并且会自动帮我们确定Frame的边界在哪里。
Frame编解码
既然是Frame,就涉及到采用何种编码的问题。Frame本身只是一个框的概念,这个框里面具体填什么格式的内容,是由编码决定的,写入的时候编码,取出的时候需要解码。
与 tokio 配套的 tokio_util crate 里,提供了四种最简单的编解码类型:BytesCodec、LinesCodec、AnyDelimiterCodec、LengthDelimitedCodec。我们分别介绍一下。
- BytesCodec
Frame长度为1的编解码。一个字节一个Frame。适用于文本和二进制的任何网络协议。如果你的应用就想一个字节一个字节地处理数据流,这个就是合适的选择。
- LinesCodec
行编解码协议,它使用 \n 作为Frame之间的分隔。这个协议用得很多,特别适合文本网络协议。
- AnyDelimiterCodec
指定间隔符的编解码协议,这个相当于LinesCodec的扩展版本。用这个协议,你可以自定义任何Frame分隔符,比如 ; , # 等等。它也比较适用于文本网络协议。
- LengthDelimitedCodec
长度分隔编解码协议。这个协议的思路是,每一个msg发送的时候,在它前面,都加上一个固定位数的长度表示前缀。这样,每次读到这个前缀数字的时候,就知道接下来要读多少个字节,才会形成一个完整的Frame。比如编码后的一个Frame类似下面这个样子:
+----------+--------------------------------+
| len: u32 | frame payload |
+----------+--------------------------------+
这个方法是协议设计的典型方法,具有非常强的通用性,适用于文本或二进制的网络协议。
tokio不仅提供了这些默认的简单的编解码方案,它还允许你自定义Codec。如果上面4种都不能满足你的需求,你完全可以按它的规范自定义一个。
此处,我们可以用LengthDelimitedCodec,只需要在基本的 TcpStream 上套一下就可以了。接着往下看。
使用Frame改造代码
使用Framed + LengthDelimitedCodec 类型改造后的服务端和客户端代码如下:
服务端代码:
use bytes::Bytes; use futures::{SinkExt, StreamExt}; use std::env; use tokio::net::TcpListener; use tokio::process::Command; use tokio_util::codec::{Framed, LengthDelimitedCodec}; #[tokio::main] async fn main() -> Result<(), Box<dyn std::error::Error>> { let addr = env::args() .nth(1) .unwrap_or_else(|| "127.0.0.1:8888".to_string()); println!("Listening on: {}", addr); let listener = TcpListener::bind(&addr).await?; // 注意这里是一个无条件循环,表明始终处于服务状态 loop { // 等待客户端请求连上来 let (stream, _) = listener.accept().await?; // 包裹成一个Frame stream let mut framed_stream = Framed::new(stream, LengthDelimitedCodec::new()); // 创建子task执行任务 tokio::spawn(async move { // 等待读取一个一个msg,如果返回None,会退出这个循环 while let Some(msg) = framed_stream.next().await { match msg { Ok(msg) => { // 解析指令,执行任务 let directive = String::from_utf8(msg.to_vec()) .expect("error when converting to string directive."); println!("{directive}"); let output = process(&directive).await; println!("{output}"); // 返回执行结果 _ = framed_stream.send(Bytes::from(output)).await; } Err(e) => { println!("{e:?}"); } } } }); } } async fn process(directive: &str) -> String { if directive == "gettime" { // 这里我们用了unwrap()是因为我们一般确信执行date命令不会失败 // 更可靠的做法是对返回的Result作处理 let output = Command::new("date").output().await.unwrap(); String::from_utf8(output.stdout).unwrap() } else { // 如果是其他指令,我们目前返回 无效指令 "invalid command".to_owned() } }
这里我简单解释一下上面的示例。
在监听到连接stream(第19行)后,把它包裹成Frame stream(第21行),然后使用 while let 配合 framed_stream.next() 对这个流进行迭代,就读出了里面一帧一帧的数据msg。需要返回结果的时候,使用 framed_stream.send() 就可以了。
客户端代码:
use bytes::Bytes; use futures::{SinkExt, StreamExt}; use std::env; use tokio::net::TcpStream; use tokio_util::codec::{Framed, LengthDelimitedCodec}; #[tokio::main] async fn main() -> Result<(), Box<dyn std::error::Error>> { let addr = env::args() .nth(1) .unwrap_or_else(|| "127.0.0.1:8888".to_string()); // 连接到服务端 let stream = TcpStream::connect(&addr).await?; // 包裹成 Frame stream let mut framed_stream = Framed::new(stream, LengthDelimitedCodec::new()); // 发送指令 framed_stream.send(Bytes::from("gettime")).await?; // 读取返回数据,这里只读一次 if let Some(msg) = framed_stream.next().await { match msg { Ok(msg) => { let timeinfo = String::from_utf8(msg.to_vec())?; println!("{}", timeinfo); } Err(e) => return Err(e.into()), } } Ok(()) }
在连接到服务器,得到连接stream(第13行)后,把它包裹成Frame stream(第15行) ,然后使用 framed_stream.send() 发送一条指令,在后面用迭代器方法等待指令执行后返回的内容msg。对msg的处理方式和服务端代码一致。
可以看到,经过Frame层抽象后,大大精简了代码逻辑,整体变得非常清爽。最关键的是,改造后的代码实际 完全重塑了程序员的心智模型:我们不再需要关注底层传输的大量细节了,真正实现了面向业务编码,可以按时下班了,非常开心。
注:这节课的完整代码点击 这里 可以获取。
小结
这节课我们一起学习了如何循序渐进地基于tokio开发一个服务端和客户端tcp网络应用命令行程序。知识点很多,我们一起来回顾一下。
- Rust中命令行参数的获取方式;
- 在Cargo.toml 配置文件中添加依赖;
- 在服务端建立 tcp lisener;
- 根据新的连接创建新的task;
- 读取tcp数据输入,以及写入返回内容;
- 建立 tcp client 连接;
- 编译测试Rust命令行程序;
- tokio的Frame概念和编解码;
- 使用Frame简化网络编程。
网络编程有其复杂性在里面,所以这节课我们应该重点掌握使用Frame的编程模型,同时了解原始字节流的处理原理。
思考题
最后请你来思考2个问题。
- EOF是什么,什么时候会碰到EOF?
- 请问 stream.read_to_end() 接口能读完网络连接中的数据吗?
欢迎你把思考后的结果分享到评论区和我一起讨论,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
tokio编程:在多任务之间操作同一片数据
你好,我是Mike。今天我们一起来学习如何在tokio的多个任务之间共享同一片数据。
并发任务之间如何共享数据是一个非常重要的课题,在所有语言中都会碰到。不同的语言提供的方案支持不尽相同,比如 Erlang 语言默认只提供消息模型,Golang 也推荐使用 channel 来在并发任务之间进行同步。
Rust语言考虑到其应用领域的广泛性和多样性,提供了多种机制来达到这一目的,需要我们根据不同的场景自行选择最合适的机制。所以相对来说,Rust在这方面要学的知识点要多一些,好处是它在几乎所有场景中都能做到最好。
任务目标
定义一个内存数据库db,在不同的子任务中,并发地向这个内存数据库更新数据。
潜在问题
为了简化问题,我们把 Vec<u32> 当作db。比如这个db中现在有10个数据。
let mut db: Vec<u32> = vec![1,2,3,4,5,6,7,8,9,10];
现在有两个任务 task_a 和 task_b,它们都想更新db里的第5个元素的数据 db[4]。
task_a 想把它更新成 50,task_b 想把它更新成 100。这两个任务之间是没有协同机制的,也就是互相不知道对方的存在,更不知道对方要干嘛。于是就可能出现这样的情况,两个任务几乎同时发起更新请求,假如 task_a 领先一点点时间,先把 db[4] 更新成 50 了,但是它得校验一下更新正确了没有,所以它得发起一个索引请求,把 db[4] 的数据取出来看看是不是 50。
但是在task_a去检查 db[4] 的值之前极小的一个时间片段里面,task_b 对db[4]更新操作也发生了,于是db[4] 被更新成了 100。然后 task_a 取回值之后,发现值是 100。很奇怪,并且判断自己没有更新成功这个数据,有可能会再更新一次,再次把 db[4] 置为 50。这又可能对 task_b 的校验机制造成干扰。于是整个系统就开始紊乱了。
这就是多个任务操作共享数据可能会发生的问题。下面我们看看在Rust中怎么去解决这个问题。
方案尝试
我们可以先从最简单的思路开始,设计如下方案。
方案一:全局变量
如果你有其他语言编程经验的话,应该很容易就能想到一个方案,就是利用全局变量来实现多个任务的数据共享。假如我们有一个全局变量 DB,为 Vec<u32> 类型,每个任务都可以访问到这个DB,并可以向里面push数据。
我们先来试试直接在main函数里对这个DB全局变量进行操作。
static DB: Vec<u32> = Vec::new(); fn main() { DB.push(10); }
发现不行,编译会报错:
error[E0596]: cannot borrow immutable static item `DB` as mutable
--> src/main.rs:4:5
|
4 | DB.push(10);
| ^^^^^^^^^^^ cannot borrow as mutable
可能是没加 mut?加上试一试。
static mut DB: Vec<u32> = Vec::new(); fn main() { DB.push(10); }
还是出错:
error[E0133]: use of mutable static is unsafe and requires unsafe function or block
--> src/main.rs:4:5
|
4 | DB.push(10);
| ^^^^^^^^^^^ use of mutable static
|
= note: mutable statics can be mutated by multiple threads: aliasing violations or data races will cause undefined behavior
Rust编译器报错说,要使用可变的静态全局变量是不安全的,需要用到unsafe功能。unsafe功能我们还没讲,而且不是这节课的重点,所以这里不展开。总之, Rust不推荐我们使用全局(静态)变量。因为全局变量不是一个好的方案,特别是对于多任务并发程序来说,应该尽可能避免。
那既然全局变量不能用了,有一个可行的选择是,在 main 函数中创建一个对象实例,把这个实例传给各个任务。因为这个实例是在main函数中创建的,它的生命期跟main函数一样长,所以也相当于全局变量了。
方案二:main函数中的对象
稍微改一下上面的代码,这下可以了。
fn main() { let mut db: Vec<u32> = vec![1,2,3,4,5,6,7,8,9,10]; db[4] = 50; }
下面我们尝试在main函数中创建一个tokio任务。
#[tokio::main] async fn main() { let mut db: Vec<u32> = vec![1,2,3,4,5,6,7,8,9,10]; let task_a = tokio::task::spawn(async { db[4] = 50; }); _ = task_a.await.unwrap(); println!("{:?}", db); }
这是一段稀松平常的代码,目的就是起一个task,更新一下Vec里的元素,然后等待这个任务结束,打印这个Vec的值。但是,在Rust中,这段代码无法通过,Rust编译器会报错。
error[E0373]: async block may outlive the current function, but it borrows `db`, which is owned by the current function
--> src/main.rs:5:37
|
5 | let task_a = tokio::task::spawn(async {
| _____________________________________^
6 | | db[4] = 50;
| | -- `db` is borrowed here
7 | | });
| |_____^ may outlive borrowed value `db`
|
= note: async blocks are not executed immediately and must either take a reference or ownership of outside variables they use
help: to force the async block to take ownership of `db` (and any other referenced variables), use the `move` keyword
|
5 | let task_a = tokio::task::spawn(async move {
| ++++
我们来分析一下这个错误提示,错误提示第1行说,任何异步块都有可能超出当前函数的生存期,但是它里面依赖的db是在当前函数定义的,因此在异步块执行的时候,db指向的对象有可能会消失,从而出错。你可能已经猜到了,错误原因跟所有权相关。原因是这个task_a运行的生存时间段,有可能超过main task生存的时间段,所以task_a里的async块中直接借用main函数中的局部变量db会有所有权相关风险。
不过这里还有一点疑问,我们不是在main中手动 .await 了吗?会等待这个子task的返回结果,但是Rust并没有分析到这一点。它可能会觉得你在 task_a.await 这一句之前其实是有机会将db给弄消失的,比如手动 drop() 掉这个db,或者说调用了什么别的函数,把db的所有权在那里给消耗了。
它在错误信息第12行建议我们在 async 后加 move 修饰符,这样指明强制将 db 的所有权移动进task_里去。我们按照建议修改一下。
#[tokio::main] async fn main() { let mut db: Vec<u32> = vec![1,2,3,4,5,6,7,8,9,10]; let task_a = tokio::task::spawn(async move { db[4] = 50; }); _ = task_a.await.unwrap(); println!("{:?}", db); }
仍然编译出错,报错信息换了。
error[E0382]: borrow of moved value: `db`
--> src/main.rs:10:22
|
3 | let mut db: Vec<u32> = vec![1,2,3,4,5,6,7,8,9,10];
| ------ move occurs because `db` has type `Vec<u32>`, which does not implement the `Copy` trait
4 |
5 | let task_a = tokio::task::spawn(async move {
| _____________________________________-
6 | | db[4] = 50;
| | -- variable moved due to use in generator
7 | | });
| |_____- value moved here
...
10 | println!("{:?}", db);
| ^^ value borrowed here after move
它说,db已经被移动到了task_a里了,所以在main函数中访问不到。这种严苛性,对于从其他语言过来的新手来说,确实令人崩溃。不过反过来想想Rust确实把细节抠得很死,这也是它比其他语言安全的原因。
那么我们就听小助手的话,不在main函数中打印了。这样确实能编译通过。
#[tokio::main] async fn main() { let mut db: Vec<u32> = vec![1,2,3,4,5,6,7,8,9,10]; let task_a = tokio::task::spawn(async move { db[4] = 50; }); _ = task_a.await.unwrap(); }
第一步走通了,下一步我们要测试多任务并发的情况,所以我们需要再增加一个任务。
use tokio::task; #[tokio::main] async fn main() { let mut db: Vec<u32> = vec![1,2,3,4,5,6,7,8,9,10]; let task_a = task::spawn(async move { db[4] = 50; }); let task_b = task::spawn(async move { db[4] = 100; }); _ = task_a.await.unwrap(); _ = task_b.await.unwrap(); }
这种写法明显会有问题,我们甚至不需要编译就可以知道,因为出现了两次 async move 块。如果你是一步步学过来的话,应该知道,db在第一个async move时已经被移动进 task_a 了,后面不可能再移动进 task_b。
编译验证后,确实如此。
error[E0382]: use of moved value: `db`
--> src/main.rs:10:30
|
5 | let mut db: Vec<u32> = vec![1,2,3,4,5,6,7,8,9,10];
| ------ move occurs because `db` has type `Vec<u32>`, which does not implement the `Copy` trait
6 |
7 | let task_a = task::spawn(async move {
| ______________________________-
8 | | db[4] = 50;
| | -- variable moved due to use in generator
9 | | });
| |_____- value moved here
10 | let task_b = task::spawn(async move {
| ______________________________^
11 | | db[4] = 100;
| | -- use occurs due to use in generator
12 | | });
| |_____^ value used here after move
那应该怎么办呢?
方案三:利用 Arc
回想一下 第 12 讲 我们讲到过的Arc这个智能指针,它可以让多个持有者共享对同一资源的所有权。但是Arc也有一个巨大的限制,就是它无法修改被包裹的值。但不管怎样,我们还是碰碰运气,改动一下。
use std::sync::Arc; #[tokio::main] async fn main() { let mut db: Vec<u32> = vec![1,2,3,4,5,6,7,8,9,10]; let arc_db = Arc::new(db); let arc_db2 = arc_db.clone(); let task_a = tokio::task::spawn(async move { arc_db[4] = 50; }); let task_b = tokio::task::spawn(async move { arc_db2[4] = 100; }); _ = task_a.await.unwrap(); _ = task_b.await.unwrap(); // println!("{:?}", db); }
不出所料,Rust编译不通过,这说明通过 Arc<T> 没办法修改里面的值。
error[E0596]: cannot borrow data in an `Arc` as mutable
--> src/main.rs:10:9
|
10 | arc_db[4] = 50;
| ^^^^^^ cannot borrow as mutable
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `Arc<Vec<u32>>`
error[E0596]: cannot borrow data in an `Arc` as mutable
--> src/main.rs:13:9
|
13 | arc_db2[4] = 100;
| ^^^^^^^ cannot borrow as mutable
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `Arc<Vec<u32>>`
虽然现在我们的代码还是没有编译通过,但是思路是没问题的:要在并发的多个任务中,访问同一个资源,那么必然涉及到多所有权,所以使用Arc是完全没有问题的。现在的问题是, 有没有办法更改被Arc包裹起来的值。
答案是有的,利用 Mutex 就可以。
方案四:Arc+Mutex
一个多任务并发编程要修改同一个值,那必然要防止修改冲突,这就不得不用到计算机领域里一个常见的工具——锁。
Mutex是一种互斥锁,被Mutex包裹住的对象,同时只能存在一个reader或一个writer。使用的时候,要先获得Mutex锁,成功后,才能读或写这个锁里面的值。多个任务不能同时获得同一个Mutex锁,当一个任务持有Mutex锁时,其他任务会处于等待状态,直到那个任务用完了Mutex锁,并自动释放了它。
use std::sync::Arc; use tokio::sync::Mutex; #[tokio::main] async fn main() { let db: Vec<u32> = vec![1,2,3,4,5,6,7,8,9,10]; let arc_db = Arc::new(Mutex::new(db)); // 加锁 let arc_db2 = arc_db.clone(); let arc_db3 = arc_db.clone(); let task_a = tokio::task::spawn(async move { let mut db = arc_db.lock().await; // 获取锁 db[4] = 50; assert_eq!(db[4], 50); // 校验值 }); let task_b = tokio::task::spawn(async move { let mut db = arc_db2.lock().await; // 获取锁 db[4] = 100; assert_eq!(db[4], 100); // 校验值 }); _ = task_a.await.unwrap(); _ = task_b.await.unwrap(); println!("{:?}", arc_db3.lock().await); // 获取锁 } // 输出 [1, 2, 3, 4, 100, 6, 7, 8, 9, 10]
加上Mutex,这个例子就能顺利编译并运行通过了。
这个例子里的第7行,我们使用 Arc::new(Mutex::new()) 组合把db包了两层,外层是Arc,里层是Mutex。然后,我们把arc_db克隆了两次,这种克隆只是增加Arc的引用计数,代价非常低。
然后在每次使用的时候,先通过 arc_db.lock().await 这种方式获得锁,再等待取出锁中对象的引用,这里也就是Vec的引用,然后通过这个引用去更新db的值。
利用Arc与Mutex的组合,我们还顺便解决了在main task不能打印这个db的问题。实际上,在Rust中, Arc<Mutex<T>> 是一对很常见的组合,利用它们的组合技术,基本上可以满足绝大部分的并发编程场景。
有了这两兄弟的加持,我们用Rust写业务代码就变得像Java一样高效、便捷。相对于Go、Python或JavaScript来说,Rust的异步并发编程代码稍微有些繁琐,但是它的模式是非常固定的,最后这个示例里的模式可以无脑使用。正因为如此,Arc、Mutex和clone() 一起,被社区叫做“Rust三板斧”,就是因为它们简单粗暴,方便好用。
到这里为止,我们已经解决了这节课开头提出的问题。
其他锁
除了Mutex,tokio里还提供了一些锁,我们来看一看。
tokio::sync::RwLock
RwLock是读写锁。它和Mutex的区别是,Mutex不论是读还是写,同时只有一个能拿到锁。比如,一个task在读,而另一个task也想读的时候,仍然需要等待第一个task先释放锁。所以在读比较多的情况下,Mutex的运行效率不是太理想。
而RwLock的设计是,当一个任务拿的是读锁时,其他任务也能再拿到读锁,多个读锁之间可以同时存在。当一个任务想拿写锁的时候,必须等待其他所有读锁或写锁释放后才能拿到。
当一个任务拿到了写锁时,其他任务只能等待它完成后才能继续操作,不管其他任务是要写还是读。因此对于写来讲,RwLock是排斥型访问;对于读来讲,RwLock提供了共享访问。这一点与不可变引用和可变引用的关系特别像。
我们来看下面的示例:
use tokio::sync::RwLock; #[tokio::main] async fn main() { let lock = RwLock::new(5); // 多个读锁可以同时存在 { let r1 = lock.read().await; let r2 = lock.read().await; assert_eq!(*r1, 5); assert_eq!(*r2, 5); } // 在这一句结束时,两个读锁都释放掉了 // 同时只能存在一个写锁 { let mut w = lock.write().await; *w += 1; assert_eq!(*w, 6); } // 在这一句结束时,写锁释放掉了 }
可以看到,RwLock的使用非常简单,在读操作比写操作多很多的情况下,RwLock的性能会比Mutex好很多。
Rust标准库中还有一些用于简单类型的原子锁。
std::sync::atomic
如果共享数据的只是一些简单的类型,比如 bool、i32、u8、usize等等,就不需要使用Mutex或RwLock把这些类型包起来,比如像这样 Arc<Mutex<u32>>,可以直接用Rust标准库里提供的原子类型。 std::sync::atomic 这个模块下面提供了很多原子类型,比如AtomicBool、AtomicI8、AtomicI16等等。
Mutex<u32> 对应的原子类型是 std::sync::atomic::AtomicU32。
像下面这样使用:
use std::sync::atomic::AtomicU32; fn main() { // 创建 let atomic_forty_two = AtomicU32::new(42); let arc_data = Arc::new(atomic_forty_two); let mut some_var = AtomicU32::new(10); // 更新 *some_var.get_mut() = 5; assert_eq!(*some_var.get_mut(), 5); }
其他类型按类似的方式使用就可以了。原子类型之所以会单独提出来,是因为它是锁的基础,其他的锁会建立在这些基础原子类型之上,这些原子类型也可以充分利用硬件提供的关于原子操作的支持,从而提高应用的性能。
注:在多核CPU中,常见的硬件支持原子操作的方法包括CPU中的缓存一致性协议、总线锁定等机制,可以使多个线程或进程同时对同一变量进行原子操作时,不会出现数据竞争和线程同步的问题。
锁(lock)和无锁(lock-free)是计算机科学领域一个非常大的课题,Rust有本书 《Rust Atomics and Locks》 专门讲这个,有兴趣的话你可以看一看。
小结
这节课我们通过一步步验证的方式,学习了在Rust和tokio中如何在多个任务中操作共享数据,经过多次被编译器拒绝的痛苦,最后我们得到了一个相当舒服的方案。这个方案可以供我们以后在做并发编程时使用,使用时的模式非常固定,没有什么心智负担。整个探索过程虽然比较辛苦,但是结果却是比较美好的。这也许就是Rust的学习过程吧,先苦后甜。
在整个探索过程中,我们也能深切体会Rust所有权模型在并发场景下发挥的重要作用。如果你想让程序编译通过,那么必须严格遵守Rust的所有权模型;一旦你在Rust的所有权指导下捣鼓出了并发代码,那么 你的并发代码就一定不会产生由于竞争条件而导致的概率性Bug。
如果你有这方面的经验教训,你一定会特别憎恶这种概率性的Bug,因为有可能仅仅是重现Bug现场就要花一个月的时间。同时,你会爱上Rust,因为它从语言层面就帮我们杜绝了这种情况,让我们的线上服务特别稳定,晚上可以安心睡觉了。
思考题
这节课代码里下面这两句的意义是什么,第一行会阻塞第二句吗?
_ = task_a.await.unwrap();
_ = task_b.await.unwrap();
希望你可以开动脑筋,认真思考,把你的答案分享到评论区,也欢迎你把这节课的内容分享给其他朋友,邀他们一起学习Rust。好了,我们下节课再见吧!
tokio编程:使用channel在不同任务间通信?
你好,我是Mike。今天我们来了解并发编程的另一种范式——使用channel在不同的任务间进行通信。
channel翻译成中文就是通道或管道,用来在task之间传递消息。这个概念本身并不难。我们回忆一下上节课的目标:要在多个任务中同时对一个内存数据库进行更新。其实我们也可以用channel的思路来解决这个问题。
我们先来分解一下任务。
- 创建三个子任务,task_a、task_b 和另一个起代理作用的 task_c。
- 在 task_a 和 task_b 中,不直接操作db本身,而是向 task_c 发一个消息。
- task_c 里面会拿到 db 的所有权,收到从 task_a 和 task_b 来的消息后,对db进行操作。
基于这个思路,我们来重写上一节课的示例。
MPSC Channel
我们使用tokio中的MPSC Channel来实现。MPSC Channel是多生产者,单消费者通道(Multi-Producers Single Consumer)。
MPSC的基本用法如下:
let (tx, mut rx) = mpsc::channel(100);
使用MPSC模块的 channel() 函数创建一个通道对,tx表示发送端,rx表示接收端,rx前面要加mut修饰符,因为rx在接收数据的时候使用了可变借用。channel使用的时候要给一个整数参数,表示这个通道容量多大。tokio的这个 mpsc::channel 是带背压功能的,也就是说,如果发送端发得太快,接收端来不及消耗导致通道堵塞了的话,这个channel会让发送端阻塞等待,直到通道里面的数据包被消耗到留出空位为止。
MPSC的特点就是可以有多个生产者,但只有一个消费者。因此,tx可以被随意clone多份,但是rx只能有一个。
前面的例子,我们用channel来实现。
use tokio::sync::mpsc; #[tokio::main] async fn main() { let mut db: Vec<u32> = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; let (tx, mut rx) = mpsc::channel::<u32>(100); // 创建channel let tx1 = tx.clone(); // 拷贝两份arc let tx2 = tx.clone(); let task_a = tokio::task::spawn(async move { if let Err(_) = tx1.send(50).await { // 发送端标准写法 println!("receiver dropped"); return; } }); let task_b = tokio::task::spawn(async move { if let Err(_) = tx2.send(100).await { // 发送端标准写法 println!("receiver dropped"); return; } }); let task_c = tokio::task::spawn(async move { while let Some(i) = rx.recv().await { // 接收端标准写法 println!("got = {}", i); db[4] = i; println!("{:?}", db); } }); _ = task_a.await.unwrap(); _ = task_b.await.unwrap(); _ = task_c.await.unwrap(); } //输出 got = 50 [1, 2, 3, 4, 50, 6, 7, 8, 9, 10] got = 100 [1, 2, 3, 4, 100, 6, 7, 8, 9, 10] ^C
代码第6行,我们使用 let (tx, mut rx) = mpsc::channel::<u32>(100); 创建一个channel,注意,这一句使用 ::<u32> 指定了这个channel中要传输的消息类型,也就是传u32类型的整数,通道容量为100个消息。
第8行和第9行,clone了两份tx。因为tx本质上实现为一个Arc对象,因此clone它也就只增加了引用计数,没有多余的性能消耗。
第11行和第17行,创建了两个工作者任务,在里面我们用 if let Err(_) = tx1.send(50).await 这种写法来向 channel 中发送信息,因为向 MPSC Channel 中灌数据时,是有可能会出错的,比如channel的另一端 rx 已经关闭了(被释放了),那么这时候再用 tx 发数据就会产生一个错误,所以这里需要用 if let Err(_) 这种形式来处理错误。
第24行,创建一个代理任务 task_c,使用这种写法 while let Some(i) = rx.recv().await 来接收消息。这里 rx.recv().await 获取回来的是一个 Option<u32> 类型,因此要用 while let Some(i) 这种模式匹配语法来写,i 就是收到的消息。然后在while内部处理具体的业务就行了。当 rx 收到一个 None 值(channel关闭产生的)的时候,会退出这个循环。
可以看到,当业务正常进行时,这个程序不会自动终止,而是会一直处于工作状态,最后我们得用 Ctrl-C 在终端终止它的运行。为什么呢?因为 while let 没有退出。 rx.recv().await 一直在等待下一个msg的到来,但是前面两个发消息的任务 task_a、task_b 的工作已经完成,退出了,于是没有角色给rx发消息了,它就会一直等下去。这里的 .await 是一种不消耗资源的等待,tokio保证这种等待不会让一个CPU忙空转。
第31行~第33行的顺序在这里并不是很重要,你可以试试改变 task_a、task_b、task_c 的 await 的顺序,看看输出结果的变化。
花几分钟理解了这个过程后,你会发现这个方案的思维方式和前面使用锁的方式完全不同。这其实是一种常见的设计模式:代理模式。
真正的并发执行
tokio::task::spawn() 这个API有个特点,就是通过它创建的异步任务,一旦创建好,就会立即扔到tokio runtime 里执行,不需要对其返回的 JoinHandler 进行 await 才驱动执行,这个特性很重要。
我们使用这个特性分析一下前面的示例:task_a、task_b、task_c 创建好之后,实际就已经开始执行了。task_c 已经在等待channel数据的到来了。第31到33行JoinHandler的await只是在等待任务本身结束而已。我们试着修改一下上面的示例。
use std::time::Duration; use tokio::sync::mpsc; use tokio::task; use tokio::time; #[tokio::main] async fn main() { let mut db: Vec<u32> = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; let (tx, mut rx) = mpsc::channel::<u32>(100); let tx1 = tx.clone(); let tx2 = tx.clone(); let task_a = task::spawn(async move { println!("in task_a 1"); time::sleep(Duration::from_secs(3)).await; // 等待3s println!("in task_a 2"); if let Err(_) = tx1.send(50).await { println!("receiver dropped"); return; } }); let task_b = task::spawn(async move { println!("in task_b"); if let Err(_) = tx2.send(100).await { println!("receiver dropped"); return; } }); let task_c = task::spawn(async move { while let Some(i) = rx.recv().await { println!("got = {}", i); db[4] = i; println!("{:?}", db); } }); _ = task_c.await.unwrap(); // task_c 放在前面来await _ = task_a.await.unwrap(); _ = task_b.await.unwrap(); } // 输出 in task_a 1 in task_b got = 100 [1, 2, 3, 4, 100, 6, 7, 8, 9, 10] in task_a 2 got = 50 [1, 2, 3, 4, 50, 6, 7, 8, 9, 10] ^C
在这个示例里,我们在task_a中sleep了3秒(第16行)。同时把 task_c 放到最前面去 await 了(第39行)。可以看到,task_b发来的数据先打印,3秒后,task_a发来的数据打印了。
实际对于main 函数这个 task 来讲,它其实被阻塞在了第39行,因为 task_c 一直在 await,并没有结束。task_a 和 task_b 虽然已经结束了,但是并没有执行到第 40 行和第 41 行去。对整个程序的输出来讲,没有执行到第 40 行和第 41 行并不影响最终效果。你仔细体会一下。
所以使用 task::spawn() 创建的多个任务之间,本身就是并发执行的关系。你可以对比一下这两个示例。
unbounded channel
tokio::mpsc模块里还有一个函数 mpsc::unbounded_channel(),可以用来创建没有容量上限的通道,也就意味着,它不具有背压功能。这个通道里面能存多少数据,就看机器的内存多大,极端情况下,可能会撑爆你的服务器。而在使用方法上,这两种channel区别不大,因此不再举例说明。如果你感兴趣的话可以看一下我给出的 链接。
Oneshot Channel
如果现在我们要在前面示例的基础上增加一个需求:我在task_c中将db更新完成,想给 task_a 和 task_b 返回一个事件通知说,我已经完成了,应该怎么做?
这个问题当然不止一种解法,比如外部增加一个消息队列,将这两个消息抛进消息队列里面,让task_a和task_b监听这个队列。然而这个方案会增加对外部服务的依赖,可能是一个订阅-发布服务;task_a和task_b 里需要订阅外部消息队列,并过滤对应的消息进行处理。
tokio其实内置了另外一个好用的东西 Oneshot channel,它可以配合 MPSC Channel 完成我们的任务。Oneshot定义了这样一个模型,这个通道只能用一次,也就是说只能发送一条数据,发送完之后就关闭了,对应的tx和rx就无法再次使用了。这个很适合等待计算结果返回的场景。我们试着用这个新设施来实现一下我们的需求。
use std::time::Duration; use tokio::sync::{mpsc, oneshot}; use tokio::task; use tokio::time; #[tokio::main] async fn main() { let mut db: Vec<u32> = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; let (tx, mut rx) = mpsc::channel::<(u32, oneshot::Sender<bool>)>(100); let tx1 = tx.clone(); let tx2 = tx.clone(); let task_a = task::spawn(async move { time::sleep(Duration::from_secs(3)).await; let (resp_tx, resp_rx) = oneshot::channel(); if let Err(_) = tx1.send((50, resp_tx)).await { println!("receiver dropped"); return; } if let Ok(ret) = resp_rx.await { if ret { println!("task_a finished with success."); } else { println!("task_a finished with failure."); } } else { println!("oneshot sender dropped"); return; } }); let task_b = task::spawn(async move { let (resp_tx, resp_rx) = oneshot::channel(); if let Err(_) = tx2.send((100, resp_tx)).await { println!("receiver dropped"); return; } if let Ok(ret) = resp_rx.await { if ret { println!("task_b finished with success."); } else { println!("task_b finished with failure."); } } else { println!("oneshot sender dropped"); return; } }); let task_c = task::spawn(async move { while let Some((i, resp_tx)) = rx.recv().await { println!("got = {}", i); db[4] = i; println!("{:?}", db); resp_tx.send(true).unwrap(); } }); _ = task_a.await.unwrap(); _ = task_b.await.unwrap(); _ = task_c.await.unwrap(); } // 输出 got = 100 [1, 2, 3, 4, 100, 6, 7, 8, 9, 10] task_b finished with success. got = 50 [1, 2, 3, 4, 50, 6, 7, 8, 9, 10] task_a finished with success. ^C
解释一下这个例子,这个例子里的第9行,把消息类型定义成了 (u32, oneshot::Sender<bool>)。对,你没看错,是一个元组,元组的第二个元素为oneshot channel 的发送端类型。
然后第16行,在task_a中创建了一个 Oneshot channel,两个端为 resp_tx和resp_rx。然后在第17行,把resp_tx实例直接放在消息中,随着MPSC Channel一起发送给 task_c了。然后在 task_a 里用 resp_rx 等待 oneshot 通道的值传过来。这点很关键。task_b也是类似的处理。
在task_c里,第51行收到的消息是 Some((i, resp_tx)),task_c 拿到了 task_a 和 task_b 里创建的 Oneshot channel 的发送端 resp_tx,就可以用它在第55行把计算的结果发送回去: resp_tx.send(true).unwrap();。
这个例子非常精彩,也是一种比较固定的模式。因为通道两个端本身就是类型的实例,当然可以被其他通道传输。这里我们 MPSC + Oneshot 两种通道成功实现了 Request/Response 模式。
tokio中的其他channel类型
接下来我们再介绍一下tokio中的其他channel类型。tokio中还有两个内置通道类型,用得不是那么多,但功能非常强大,你可以在遇到合适的场景时再去具体研究。
broadcast channel
广播模式,实现了MPMC模型,也就是多生产者多消费者模式,可以用来实现发布-订阅模式。每个消费者都会收到每个生产者发出的同样的消息副本。你可以查看 链接 了解学习。
broadcast通道实际已覆盖SPMC模型,所以不用再单独定义SPMC了。
watch channel
watch通道实际是一个特定化版本的broadcast通道,它有2个特性。
- 只有一个生产者,多个消费者。
- 只关心最后一个值。
它适用于一些特定的场景,比如配置更新需要通知工作任务重新加载,平滑关闭任务等等。你可以通过我给出的 链接 进一步学习。
补充知识:任务管理的2种常见模式
等待所有任务一起返回
前面示例中task_c很关键。为什么呢?因为它不但起到了搜集数据执行操作的作用,它还把整个程序阻塞住了,保证了程序的持续运行。那如果一个程序里面没有负责这个任务的角色,应该怎么去搜集其他任务返回的结果呢?我们在 第 13 讲 中已经提到了一种方式。
use tokio::task; async fn my_background_op(id: i32) -> String { let s = format!("Starting background task {}.", id); println!("{}", s); s } #[tokio::main] async fn main() { let ops = vec![1, 2, 3]; let mut tasks = Vec::with_capacity(ops.len()); for op in ops { // 任务创建后,立即开始运行,我们用一个Vec来持有各个任务的handler tasks.push(tokio::spawn(my_background_op(op))); } let mut outputs = Vec::with_capacity(tasks.len()); for task in tasks { // 在这里依次等待任务完成 outputs.push(task.await.unwrap()); } println!("{:?}", outputs); }
上面的代码有两个关键要点。
- 在第15行用一个Vec来存放所有任务的handler。
- 在第20行依次对 task 进行 await,获取任务的返回值。
这代表了一种模式。这个模式有个特点,就是要等待前面任务结束,才能拿到后面任务的返回结果。如果前面某个任务执行的时间比较长,即使后面的任务实际已经执行完了,在最后搜集结果的时候,还是需要等前面那个任务结束了后,我们才能搜集到后面任务的结果。比如:
use std::time::Duration; use tokio::task; use tokio::time; #[tokio::main] async fn main() { let task_a = task::spawn(async move { println!("in task_a"); time::sleep(Duration::from_secs(3)).await; // 等待3s 1 }); let task_b = task::spawn(async move { println!("in task_b"); 2 }); let task_c = task::spawn(async move { println!("in task_c"); 3 }); let mut tasks = Vec::with_capacity(3); tasks.push(task_a); tasks.push(task_b); tasks.push(task_c); let mut outputs = Vec::with_capacity(tasks.len()); for task in tasks { println!("iterate task result.."); // 在这里依次等待任务完成 outputs.push(task.await.unwrap()); } println!("{:?}", outputs); } // 输出 iterate task result.. in task_a in task_b in task_c // 在这之后会等待 3 秒,然后继续打印 iterate task result.. iterate task result.. [1, 2, 3]
上面的示例创建了三个任务 task_a、task_b、task_c,在task_a里等待3秒返回,task_b和task_c都是立即返回。执行的时候,当打印出 "in task_c" 后,会停止3秒左右,然后继续打印剩下的,印证了我们前面的分析。
tokio提供了一个宏 tokio::join!(),用来简化上面代码的写法,表示等待所有任务完成后,一起返回一个结果。用法如下:
use std::time::Duration; use tokio::task; use tokio::time; #[tokio::main] async fn main() { let task_a = task::spawn(async move { println!("in task_a"); time::sleep(Duration::from_secs(3)).await; // 等待3s 1 }); let task_b = task::spawn(async move { println!("in task_b"); 2 }); let task_c = task::spawn(async move { println!("in task_c"); 3 }); let (r1, r2, r3) = tokio::join!(task_a, task_b, task_c); println!("{}, {}, {}", r1.unwrap(), r2.unwrap(), r3.unwrap()); } // 输出 in task_a in task_b in task_c 1, 2, 3
这两个示例基本等价,都是在所有任务中等待最长的那个任务执行完成后,统一返回。你可以想想为什么它们差不多。
等待其中一个任务先返回
在实际场景中,还有另外一大类需求,就是在一批任务中,哪个任务先执行完,就马上返回那个任务的结果。剩下的任务,要么是不关心它们的执行结果,要么是直接取消它们继续执行。
针对这种场景,tokio提供了 tokio::select!() 宏。用法如下:
use std::time::Duration; use tokio::task; use tokio::time; #[tokio::main] async fn main() { let task_a = task::spawn(async move { println!("in task_a"); time::sleep(Duration::from_secs(3)).await; // 等待3s 1 }); let task_b = task::spawn(async move { println!("in task_b"); 2 }); let task_c = task::spawn(async move { println!("in task_c"); 3 }); let ret = tokio::select! { r = task_a => r.unwrap(), r = task_b => r.unwrap(), r = task_c => r.unwrap(), }; println!("{}", ret); } // 输出 // 第一次 in task_b in task_a 2 in task_c // 第二次 in task_a in task_c in task_b 2 // 第n次 in task_a in task_c in task_b 3
请注意示例里第21行到第25行的写法,这是 tokio::select! 宏定义的语法,不是Rust标准语法。变量r表示任务的返回值。当你多次执行上面代码后,你会发现,输出结果并不固定,你可以想一下为什么会这样。
小结
这节课我们讨论了在Rust中如何应用channel这种编程范式,在并发编程中避免使用锁。Rust的tokio库提供了常用的通道模型基础设施。
- MPSC 多生产者,单消费者 channel
- Oneshot 一次性 channel
- broadcast 广播模式
- watch 观察者模式
每种通道都有各自的用途,适用于不同的场景需求。这一讲我们重点讲解了前两种通道,只要你掌握了它们,另外两种使用方式也是差不多的。这节课讨论的这些模式相当固定,只要照搬套用就可以了。
本讲代码链接: https://github.com/miketang84/jikeshijian/tree/master/16-channel
思考题
你可以说一说从任务中搜集返回结果有几种方式吗?欢迎你把你对课程的思考和疑问留在评论区,我会和你一起交流探讨,如果你觉得这节课的内容对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!
tokio编程: Rust异步编程还有哪些需要注意的点?
你好,我是Mike。前面几节课,我们学习了Rust异步编程和tokio的基础知识,我们先来简单回顾下。
async/.await语法- tokio基本概念和组件
- 使用tokio编写一个网络并发应用
- 使用Arc和Mutex在多个task之间共享数据
- 在并发task之间使用Channel传递数据
通过学习这些内容,你应该已经能使用tokio开发Rust异步并发应用了。这节课,我们对Rust异步并发相关的知识点来做一点补遗。
async其他知识点
Rust代码中的async函数,其实和Rust的普通函数是不相容的。async Rust就好像是Rust语言里的一个独立王国。
async代码的传染性
Rust async代码具有传染性。前面我们给出了使用 async/.await 的两条规则。
- async函数或block只有被
.await后才被驱动。 .await只能在async函数或block中使用。
这就导致在业务代码中(非tokio那个顶层Runtime代码),如果你需要调用一个async函数,那么你也需要让你现在这个调用者函数也是async的,你可以看我给出的这个例子。
// 我们定义foo1为一个异步函数
async fn foo1() -> u32 {
100u32
}
// 我需要在foo2函数中调用foo1,那么这个foo2也必需要是async函数
async fn foo2() -> u32 {
foo1().await
}
// 我需要在foo3函数中调用foo2,那么这个foo3也必需要是async函数
async fn foo3() -> u32 {
foo2().await
}
#[tokio::main]
async main() {
let num = foo3().await;
println!("{}", num);
}
这就叫作async代码的传染性。这种传染性是由Rust的async语法带来的。
注:Rust中还有一个语法具有传染性——类型参数T。
但是实际工作中,我们经常会遇到异步代码与同步代码混合使用的情况。这类情况应该怎么处理呢?下面我们分情况来分析。
async代码环境中的同步代码
常见的同步代码分两类,一类是直接在内存里的简单操作,比如 vec.push() 这种API接口的调用。这类操作在std Rust里怎么使用在async Rust里就怎么使用,一样的。
async fn foo1() -> u32 {
let mut vec = Vec::new();
vec.push(10);
}
另外有一类操作,要么是需要执行长时间的计算,要么是需要调用第三方已经写好的同步库的代码,你没有办法去修改它。对于这类函数的调用,你当然也可以直接调用:
async fn foo1() -> u32 {
let result = a_heavy_work();
}
这样写当然是可以运行的,但会有性能上的问题:它会阻塞当前正在跑这个异步代码的系统线程(OS Thread,由tokio来管理维护),所以当前的这个系统线程就会被卡住,而不能再跑其他异步代码了。
好消息是,tokio专门给我们提供了另外的设施来处理这种情况,就是 task::spawn_blocking() 函数。你可以看一下它的使用方法。
#[tokio::main] async fn main() { // 此任务跑在一个单独的线程中 let blocking_task = tokio::task::spawn_blocking(|| { // 在这里面可以执行阻塞线程的代码 }); // 像下面这样用同样的方式等待这种阻塞式任务的完成 blocking_task.await.unwrap(); }
只需要把CPU计算密集型任务放到 task::spawn_blocking() 里就可以了,tokio会帮我们单独开一个新的系统线程,来专门跑这个CPU计算密集型的task。然后和普通的tokio task一样,可以通过await来获取它的结果,当然,也可以用Oneshot channel把结果返回回来。
给这种CPU计算密集型任务单独开一个系统线程运行,就能保证我们当前跑异步任务的系统线程不会被这个CPU计算密集型任务占据,导致异步并发能力下降,因此我们得到了一个比较好的方案。
一般来讲,主体是async代码,只有一些小部分是同步代码的时候,使用 task::spawn_blocking() 比较合适。
同步代码环境中的async代码
那如果主体代码是同步代码(或者叫 std Rust 代码),但是局部想调用一些async接口,比如db driver只提供了async封装,像这种情况下该怎么办呢?
回想一下我们前面讲到的,展开 #[tokio::main]。
#[tokio::main] async fn main() { println!("Hello world"); }
展开后,其实是下面这个样子:
fn main() { tokio::runtime::Builder::new_multi_thread() .enable_all() .build() .unwrap() .block_on(async { println!("Hello world"); }) }
类似地,我们要在同步风格的代码中执行async代码,只需要手动 block_on 这段异步代码就可以了。除了默认的系统多线程Runtime之外,tokio专门为这种临时的(以及测试的)场景提供了另一种单系统线程的runtime,就是 new_current_thread()。它的意思是就在当前程序执行的线程中建立tokio Runtime,异步任务就跑在当前这个线程中。比如:
async fn foo1() -> u32 { 10 } fn foo() { let rt = tokio::runtime::Builder::new_current_thread() .enable_all() .build().unwrap(); let num = rt.block_on(foo1()); // 注意这一句的 foo1(),调用了此异步函数 // 或者像下面这样写 //let num = rt.block_on(async { // foo1().await //}); println!("{}", num); } fn main() { foo(); } // 输出 10
就通过这种方式,我们在主体为std Rust的代码中,成功地调用了局部的async Rust代码,并得到了这段局部异步代码的返回值。
Rust async实现原理
Rust 的async实现实际采用的是一种无栈协程(Stackless Coroutine)方案。它的实现是非常高效的,性能在所有支持异步语法的语言中属于最高的那一级,非常厉害。
Rust async的背后原理
Rust语言实际会把 async 语法编译成 std Rust 中的状态机,然后通过运行时底层的 poll 机制来轮询这个状态机的状态。所以本质上来讲, async/.await 语法只是语法糖。
简单来说,Rust会把一个async函数转换成另一种东西,你可以看一下我给出的转换示例。
async函数:
async fn foo1() -> u32 {
10
}
转换后:
struct FutureA {
...
}
impl Future for FutureA {
...
}
具体的转换和实现细节我们现在不需要掌握,只需要知道,Rust的这种实现并不是像Go或Java那样,在系统级线程的基础上,单独实现了一层结合GC内存管理且具有完整屏蔽性的轻量级线程,它没有选择在OS应用之间引入一个层(layer),而是在结构体之上构建一个状态机,以零成本抽象(zero cost abstract)为原则,尽量少地引入额外的消耗,配合 async/.await 语法糖,来达到简化程序员开发难度的效果。
这种方案成功地让Rust的异步并发能力达到业界顶尖水平。Rust异步语法从提案到稳定推出,前后经历了大量的讨论和修改,花了将近5年的时间,非常不容易,是整个Rust社区共同努力的结果,期间的故事称得上是全世界开源协作的典范。
其他一些要注意的问题
Rust async编程也一直处于不断地发展过程中,比如目前在 trait 里,就不能定义async 方法,比如:
trait MyTrait {
async fn f() {}
}
// 编译错误
error[E0706]: trait fns cannot be declared `async`
--> src/main.rs:4:5
|
4 | async fn f() {}
|
为了解决这个问题,我们可以引入 async_trait crate 的 async_trait 宏来暂时过渡。
use async_trait::async_trait;
#[async_trait] // 定义时加
trait MyTrait {
async fn f() {}
}
struct Modal;
#[async_trait] // impl 时也要加
impl MyTrait for Modal {}
请注意上述代码中,在定义trait和impl trait的时候,都需要添加 #[async_trait] 属性宏来标注。添加了这个宏标注后,trait里的 async fn 就可以像普通的async fn 那样在异步代码中被调用了。
目前使用这个宏会有一点性能上的开销,好在trait中的async fn这个特性Rust官方也快稳定下来了,估计在1.75版本正式推出,到时候就可以去掉这个宏标注了。
小结
这节课我补充了Rust异步并发编程中剩下的一些需要注意的知识点。
我们一共花了5节课的时间来讲解async Rust和tokio的使用,这是因为异步并发编程对于一个场景,也就是高性能高并发服务来说,至关重要。在后面的Web后端服务开发实战部分,我们还会继续基于tokio进行讲解。
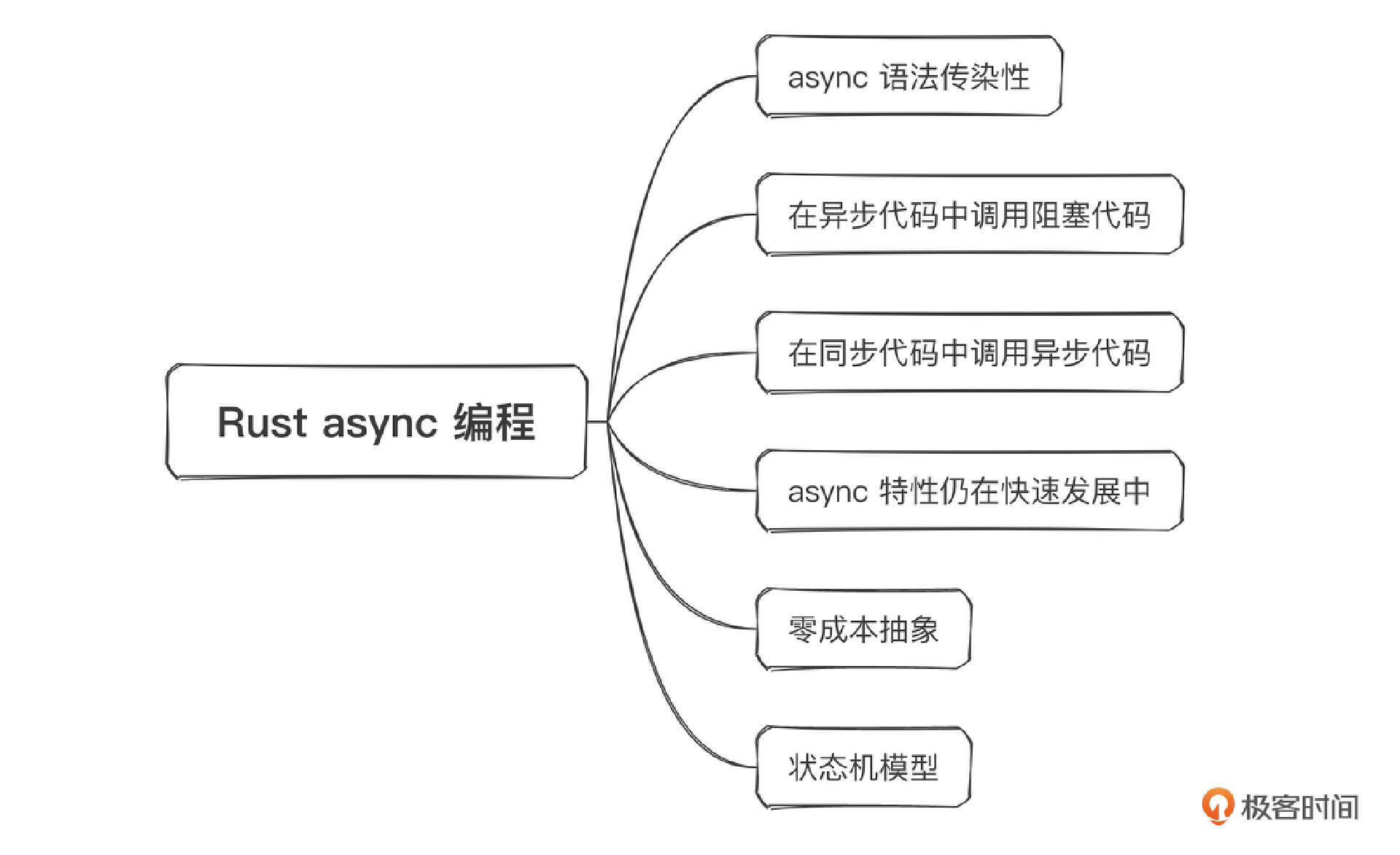
思考题
你是如何理解 “async Rust是一个独立王国”这种说法的?欢迎你分享自己的见解,我们一起讨论,如果你觉得这节课的内容对你有帮助的话,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
参考链接: https://tokio.rs/tokio/topics/bridging
错误处理系统:错误的构建、传递和处理
你好,我是Mike。今天我们一起来学习Rust语言中的错误表示、传递及处理相关的知识。Rust的错误处理很重要,也很系统。所以话不多说,我们直接进入正题。
错误的分类
错误是需要分类的,不同类型的错误可能有不同的处理策略。总的来看错误分成可恢复型错误和不可恢复型错误,下面我们具体来看看这两种类型。
不可恢复型错误
有些错误,我们碰到了后需要及早退出程序,或者直接不启动程序,而是打出错误信息。
Rust中,对这些错误的支持设施有4个。
- panic!:让程序直接崩掉,退出程序,同时可选择是否打印出栈回溯信息。
- todo!:常用于功能还未实现,执行到这里直接退出程序,并提示说这个功能处于准备做的状态。
- unimplemented!:常用于功能还未实现,执行到这里直接退出程序,并提示说这个功能处于未实现的状态。
- unreachable!:用于写在一些原则上不可能执行到的语句,比如一个
loop {}死循环的后面,执行到那里的话,就表示肯定出错了,直接退出程序。
可恢复型错误
可恢复型错误指的是那一类错误,在遇到后,不应该让整个程序直接停止运行,而是在代码逻辑中分析可能的错误原因,要么尝试恢复性的处理方案,要么给用户返回自定义的错误信息,让用户明白任务未达到预期的原因。
在Rust中,一般使用 Result<T, E> 来承载可能会出错的函数返回值。 Result<T, E> 中的T代表正常情况下的返回类型,E代表出错情况下的返回类型。如何方便地构造E的实例,是一个重要的课题。
不可恢复型错误和可恢复型错误在某些时候界限不是那么清晰,在同一个地方,你既可以把它设计成可恢复型错误,也可以把它处理成不可恢复型错误。因此从本质上来说,是由业务逻辑来确定你要把它当成哪一类错误来处理。
错误相关的基础设施
Result<T, E>
Rust中主要通过Result类型(实例)来包裹错误类型(实例),包裹后,Result可以通过函数返回值返回到上一层调用者函数中,再由上一层函数中的逻辑来决定是在这一层用某些逻辑处理这个错误,还是继续把这个错误抛到更上一层函数进行处理,我们也可以把包裹错误的 Result<T, E> 转换成 panic!() 或者在match的Err分支调用 panic!() 来中止程序的运行。
我们前面讲到过 Result<T, E> 解包的两个函数: unwrap() 和 expect(),起的作用就是把错误 Result 值转换成 panic!(),这两个方法的区别仅在于 expect() 可以为我们提供更多的信息,让我们知道这个panic的精确位置,前提是这个提示信息要独一无二,特别是在调用栈层次非常深的情况下,提供准确的panic位置信息非常重要。
从以上对函数中错误处理的描述中,我们可以知道,错误处理本身是一项系统性的工作,其中包含:
- 错误的表示和构造;
- 错误的传递;
- 错误的处理。
据调查,一个软件项目发展到成熟阶段,用于错误处理的代码可能会占所有代码的三分之一以上。而Rust从语法和标准库层面,对错误处理做了根本上的原生支持,它要求我们必须对程序的健壮性负责,使得我们没法偷懒。在非要偷懒的情况下,也会留下明显足迹。
比如下面这个例子演示了在我们想偷懒的情况下,勤奋的Rustc小助手是如何提醒我们的。
fn foo() -> Result<String, String> { Ok("abc".to_string()) } fn main() { foo(); // 这里Rustc小助手会警告你 }
在其他语言中,如果我们像上面示例中那样调用 foo() 函数,而忽略了它的返回值,一般是没问题的。但是在Rust的地盘,Rustc小助手会提醒我们,这里有一个Result没有被使用,你必须要处理一下,并给出了处理建议。
warning: unused `Result` that must be used
--> src/main.rs:5:5
|
5 | foo(); // 这里Rustc小助手会警告你
| ^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
5 | let _ = foo(); // 这里Rustc小助手会警告你
| +++++++
由此可见,小助手不会让我们放过任何一个可能的错误。
Error trait
Rust中定义了一个抽象的Error trait,任何实现了这个trait的类型都被Rust生态认为是一个错误类型。
pub trait Error: Debug + Display {}
可以看到,一个类型要实现Error,必须同时为这个类型实现Debug和Display trait。前面提到过,Debug trait可以使用derive宏由Rust自动为你的类型实现,而Display trait需要你自己手动impl实现。
实现Error trait是Rust生态中的一种规范,也就是说如果你想在你的这层module里定义一种错误类型的话,为它实现Debug、Display、Error 后,生态就会把你的这个类型认成一种错误类型。这里就体现了trait作为一种社区协议的作用。
一个重要的点是,实现了Error trait的类型,可以被代入到 dyn Error 这个trait object里使用,而生态中很多库支持接受 &dyn Error 或 Box<dyn Error> 类型,这样你的代码就能和那些库无缝集成了。比如,让你自定义的错误类型从下面的函数中返回。
fn foo() -> Result<String, Box<dyn Error>> {
// 可返回一个由Box包起来的自定义错误类型。
}
当然,这并不是说,对于 std::result::Result<T, E> 这个类型,这里面的E就一定要实现Error trait,这是两码事。 Result<T, E> 中的 E 可以是任意类型。我们再复习一下标准库里 Result<T, E> 的定义。
pub enum Result<T, E> {
Ok(T),
Err(E),
}
从这个enum可以看到,对E没有任何约束。因此,即使你的类型不实现Error trait,它还是能被代入 Result<T, E> 中作为错误类型而使用。请注意这点区别。
小提示, Result<T, E> 的变体 Ok 和 Err 已经被加入到 pub std::prelude 里了,因此在代码中可以直接使用,不需要在前面加 Result 前缀。
std中的错误类型
Rust标准库里已经定义了一些错误类型,我们来看一下常用的几个。
std::io:Error
io Error,被定义成一个结构体,负责表示标准库里I/O相关场景的错误类型。
pub struct Error { /* private fields */ }
常见的I/O操作指的是标准输入输出、网络读写、文件读写等。在std::io模块中,对这种I/O上的读写做了统一的抽象,而类型io::Error也是这个抽象里的一部分。
我们可以用 new() 函数像下面这样创建一个io::Error实例, new() 函数第一个参数是ErrorKind枚举,第二个参数是具体的错误内容。
use std::io::{Error, ErrorKind};
// 错误可以从字符串中构造
let custom_error = Error::new(ErrorKind::Other, "oh no!");
其中 ErrorKind 是一个枚举,目前包含40种变体,基本上把在标准库中能遇到的I/O错误都详尽地定义了。
pub enum ErrorKind {
NotFound,
PermissionDenied,
ConnectionRefused,
ConnectionReset,
HostUnreachable,
NetworkUnreachable,
ConnectionAborted,
NotConnected,
AddrInUse,
AddrNotAvailable,
NetworkDown,
BrokenPipe,
AlreadyExists,
WouldBlock,
NotADirectory,
IsADirectory,
DirectoryNotEmpty,
ReadOnlyFilesystem,
FilesystemLoop,
StaleNetworkFileHandle,
InvalidInput,
InvalidData,
TimedOut,
WriteZero,
StorageFull,
NotSeekable,
FilesystemQuotaExceeded,
FileTooLarge,
ResourceBusy,
ExecutableFileBusy,
Deadlock,
CrossesDevices,
TooManyLinks,
InvalidFilename,
ArgumentListTooLong,
Interrupted,
Unsupported,
UnexpectedEof,
OutOfMemory,
Other,
}
虽然很多,但这也仅限于标准库中I/O模块可能出现的错误类型,它远远不能覆盖全部,因此这个ErrorKind仅用于标准库I/O模块相关的错误类型。
parseError
标准库中定义了一组parse相关的错误类型。
- std::num::ParseIntError
- std::num::ParseFloatError
- std::char::ParseCharError
- std::str::ParseBoolError
- std::net::AddrParseError
这些错误类型是与FromStr trait相关的,也就是在把字符串解析到其他类型的时候可能会出现的错误类型,比如:
use std::net::IpAddr; fn main() { let s = "100eee"; if let Err(e) = s.parse::<i32>() { // e 这里是 ParseIntError println!("Failed conversion to i32: {e}"); } let addr = "127.0.0.1:8080".parse::<IpAddr>(); if let Err(e) = addr { // e 这里是 AddrParseError println!("Failed conversion to IpAddr: {e}"); } } // 输出 Failed conversion to i32: invalid digit found in string Failed conversion to IpAddr: invalid IP address syntax
用枚举定义错误
下面我们来看在Rust中使用Result作为函数返回值,在上层中处理的典型方式。
// 定义自己的错误类型,一般是一个枚举,因为可能有多种错误
enum HereError {
Error1,
Error2,
Error3,
}
// 一个函数返回Err
fn bar() -> Result<String, HereError> {
Err(HereError::Error3)
}
fn foo() {
match bar() {
Ok(_) => {}
Err(err) => match err { // 在上层中通过match进行处理
HereError::Error1 => {}
HereError::Error2 => {}
HereError::Error3 => {}
},
}
}
通常我们会在当前模块中定义错误类型,一般是枚举类型,因为错误种类往往不止一个。如果某个接口返回了这个错误类型,在上层就需要match这个枚举类型进行错误处理。
到目前为止我们并没有给我们自定义的错误类型HereError实现Debug、Display和Error trait,所以我们的错误类型还仅限于自己玩,为了把它纳入Rust生态体系,我们需要给它实现这3个trait。但是我们没必要自己手动去实现,社区中已经有很好的工具crate: thiserror 可以帮助我们实现这个目的,继续往下看,待会儿就会讲到。
错误的传递
前面我们介绍了错误类型的定义和处理的基本方式,接下来,我们开始系统性地介绍错误的传递。
函数返回 Result<T, E>
前面已经讲过,在Rust中只要一个函数中可能有出错的情况发生,那么它的返回值就默认约定为Result。在继续讲之前,我们先对比一下其他语言中是怎么处理的。
C语言中,一般用同一种类型的特殊值表示异常。比如一个函数返回一个有符号整数,可以用0表示正常情况下的返回,用-1或其他负数值表示异步情况下的返回。但是这个约定并不是普遍共识,因此你可以在C语言中看到,大部分情况下函数返回0表示正常,但在一些特定情况下,返回0又表示不正确。缺乏强制约束给整个生态带来了混乱。
Java这种语言,提供强大的try-catch-throw,在语言层面捕获异常。这种形式虽然方便,但实际上会给语言Runtime带来负担,因为语言的Runtime要负责捕获代码中的异常,会有额外的性能损失。另外,由于try-catch-throw使用很方便,有时会看到程序员为了偷懒,将一大段代码全部包在try-catch-throw中的情况,无疑这会大大降低代码的质量,整个程序没办法对错误情况做精细地处理。
而Rust采取的方式是把异常情况独立出来一个维度,放在 Result<T, E> 的Err变体中。也就是说,错误在类型上就是以独立的维度存在的。比如:
fn foo(num: u32) -> Result<String, String> {
if num == 10 {
Ok("Hello world!".to_string())
} else {
Err("I'm wrong!".to_string())
}
}
上述代码中的错误类型部分被定义为String类型,实际上你可以定义成任意类型,比如下面我们把错误定义成u32类型。
fn foo(num: u32) -> Result<String, u32> {
if num == 10 {
Ok("Hello world!".to_string())
} else {
Err(100)
}
}
有时一个函数中的错误情况可能不止一种,这时候该怎样定义返回类型呢?惯用办法就是使用enum,前面其实已经见过了,这里再看一个示例。
enum MyError {
Error1,
Error2,
Error3,
}
fn foo(num: u32) -> Result<String, MyError> {
match num {
10 => Ok("Hello world!".to_string()),
20 => Err(MyError::Error1),
30 => Err(MyError::Error2),
_ => Err(MyError::Error3),
}
}
这里Result的E部分,类型就是我们自定义的MyError。
另一种常用的办法是让函数返回 Result<_, Box<dyn Error>>,比如:
use std::error::Error;
use std::fmt;
#[derive(Debug)]
struct MyError;
impl fmt::Display for MyError {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
write!(f, "{}", self)
}
}
impl Error for MyError {}
fn foo(num: u32) -> Result<String, Box<dyn Error>> {
match num {
10 => Ok("Hello world!".to_string()),
_ => {
let my_error = MyError;
Err(Box::new(my_error))
}
}
}
可以看到,一旦把错误独立到另一个维度来处理后,我们得到了相当大的灵活性和安全性:可以借助类型系统来帮助检查正常情况与异常情况的不同返回,大大减少了编码出错的机率。
有了这套优秀的错误处理底层设施后,整个Rust生态上层建筑逐渐结构性地构建起来了,大家都遵从这个约定,用同样的方式来传递和处理错误,形成了一个健康良好的生态。
map_err转换错误类型
我们常常使用Result上的 map_err 方法手动转换错误类型。比如下面这个示例:
use std::fs::File;
use std::io::Read;
fn read_file() -> Result<String, String> {
match File::open("example.txt").map_err(|err| format!("Error opening file: {}", err)) {
Ok(mut file) => {
let mut contents = String::new();
match file
.read_to_string(&mut contents)
.map_err(|err| format!("Error reading file: {}", err))
{
Ok(_) => Ok(contents),
Err(e) => {
return Err(e);
}
}
}
Err(e) => {
return Err(e);
}
}
}
我们要在 read_file() 中打开一个文件,并读取文件全部内容到字符串中。整个过程中,有可能出现两个I/O错误:打开文件错误和读取文件错误。可以看到在示例中我们使用 map_err 将这两个I/O错误的类型都转换成了String类型,来和函数返回类型签名相匹配。然后,对两个操作的Result进行了match匹配。这个函数里的两个文件操作可能的错误都是std::io::Error类型的。
很多时候同一个函数中会产生不同的错误类型,这时仍然可以使用 map_err 显式地把不同的错误类型转换成我们需要的同一种错误类型。
Result 链式处理
除了每次对Result进行match处理外,Rust中还流行一种方式,就是对Result进行链式处理。我们可以将上面打开文件并读取内容的例子改写成链式调用的风格。
代码如下:
use std::fs::File; use std::io::Read; fn read_file() -> Result<String, String> { File::open("example.txt") .map_err(|err| format!("Error opening file: {}", err)) .and_then(|mut file| { let mut contents = String::new(); file.read_to_string(&mut contents) .map_err(|err| format!("Error reading file: {}", err)) .map(|_| contents) }) } fn main() { match read_file() { Ok(n) => println!("{}", n), Err(err) => println!("Error: {}", err), } }
可以明显看到,使用链式风格改写的示例比前面用match进行处理的示例简洁很多。这里用到了 map_err、 and_then、 map 三种链式操作,它们可以在不解开Result包的情况下直接对里面的内容进行处理。关于这几个方法的详细内容,你可以参考 第 8 讲。
这里需要说明的是,在第5行 File::open() 执行完,如果产生的 Result 是 Err,那么在第6行 map_err() 后,不会再走 and_then() 操作,而是直接从 read_file() 函数中返回这个 Result 了。如果第5行的操作产生的 Result 是 Ok,就会跳过第6行,进入第7行执行。
进入第7行后,会消解前面产生的Result,把 file 对象传进来使用。然后我们再去看第9行产生的Result,如果这个Result实例是Err,那么执行完第10行后,就直接从闭包返回了,返回的是Err值,这个值会进一步作为 read_file() 函数的返回值返回。而如果Result实例是Ok,就会跳过第10行,执行第11行,第11行将 contents 字符串move进来作为内层闭包的返回值,并进一步以 Ok(contents) 的形式作为 read_file() 函数的返回值返回。
你可能会惊叹,这种链式处理比前面的match操作优美太多,但是理解起来也困难太多。这是正常的,开始的时候我们对这种链式写法会比较陌生,不过没关系,可以多写写,慢慢理解,这就是一个熟能生巧的事情,本身其实并不复杂。
? 问号操作符
另一方面,前面的match写法,有没有办法简化呢?因为看上去好像有很多样板代码。
use std::fs::File;
use std::io::Read;
fn read_file() -> Result<String, String> {
match File::open("example.txt").map_err(|err| format!("Error opening file: {}", err)) {
Ok(mut file) => {
let mut contents = String::new();
match file
.read_to_string(&mut contents)
.map_err(|err| format!("Error reading file: {}", err))
{
Ok(_) => Ok(contents),
Err(e) => {
return Err(e);
}
}
}
Err(e) => {
return Err(e);
}
}
}
比如上面代码中的第13~15行和第18~20行,都是把错误 Err(e) 返回到上一层。
Err(e) => {
return Err(e);
}
Rust中有一个 ? 操作符,可以用来简化这种场景。我们把前面代码用 ? 操作符改造一下。
use std::fs::File;
use std::io::Read;
fn read_file() -> Result<String, String> {
let mut file =
File::open("example.txt").map_err(|err| format!("Error opening file: {}", err))?;
let mut contents = String::new();
file.read_to_string(&mut contents)
.map_err(|err| format!("Error reading file: {}", err))?;
Ok(contents)
}
哇,神奇不?怎么行数缩短了这么多。
具体来说, ? 操作符大体上等价于一个match语句。
let ret = a_result?;
等价于
let ret = match a_result {
Ok(ret) => ret,
Err(e) => return Err(e), // 注意这里有一个return语句。
};
也就是说,如果result的值是Ok,就解包;如果是Err,就提前从此函数中返回这个Err。这实际是一种 防御式编程,遇到了错误,就提前返回。防御式编程能让函数体中的代码大大简化,可以减少很多层括号,相信你已经从上面的示例对比中感受到了。
细心的你可能已经发现了,这里的e是这个 a_result 里 Err(e) 中的 e。这个实例的类型是什么呢?使用return语句返回它的话,那么它是不是一定和函数中定义的返回类型中的错误类型一致呢?这个问题其实很重要。从上面的示例来看,我们明确地用 map_err 把 io::Error 转换成了 String 这种类型,所以是没问题的。我们可以来做个实验,把 map_err 去掉试试。
use std::fs::File;
use std::io::Read;
fn read_file() -> Result<String, String> {
let mut file =
File::open("example.txt")?;
let mut contents = String::new();
file.read_to_string(&mut contents)?;
Ok(contents)
}
编译器报错了:
error[E0277]: `?` couldn't convert the error to `String`
--> src/lib.rs:6:34
|
4 | fn read_file() -> Result<String, String> {
| ---------------------- expected `String` because of this
5 | let mut file =
6 | File::open("example.txt")?;
| ^ the trait `From<std::io::Error>` is not implemented for `String`
|
= note: the question mark operation (`?`) implicitly performs a conversion on the error value using the `From` trait
= help: the following other types implement trait `From<T>`:
<String as From<char>>
<String as From<Box<str>>>
<String as From<Cow<'a, str>>>
<String as From<&str>>
<String as From<&mut str>>
<String as From<&String>>
= note: required for `Result<String, String>` to implement `FromResidual<Result<Infallible, std::io::Error>>`
error[E0277]: `?` couldn't convert the error to `String`
--> src/lib.rs:8:39
|
4 | fn read_file() -> Result<String, String> {
| ---------------------- expected `String` because of this
...
8 | file.read_to_string(&mut contents)?;
| ^ the trait `From<std::io::Error>` is not implemented for `String`
|
= note: the question mark operation (`?`) implicitly performs a conversion on the error value using the `From` trait
= help: the following other types implement trait `From<T>`:
<String as From<char>>
<String as From<Box<str>>>
<String as From<Cow<'a, str>>>
<String as From<&str>>
<String as From<&mut str>>
<String as From<&String>>
= note: required for `Result<String, String>` to implement `FromResidual<Result<Infallible, std::io::Error>>`
提示说, ? 操作符不能把错误类型转换成 String 类型。这也是初学者在使用 ?操作符时的一个常见错误,容易遇到错误类型不一致的问题。并且遇到这种错误时完全不知道发生了什么,更不知道怎么解决。
我们继续看错误提示,它说, ? 操作符利用From trait尝试对错误类型做隐式转换,并列出了几种已经实现了的可以转换到String的错误类型。也就是说,Rust在处理 ? 操作符的时候,会尝试对错误类型进行转换,试着看能不能自动把错误类型转换到函数返回类型中的那个错误类型上去。如果不行,就会报错。你可以参考 第 11 讲,回顾一下如何使用 From<T> trait。我们按照要求对 std::io::Error 实现一下这个转换就好了。
use std::fs::File;
use std::io::Read;
impl From<std::io::Error> for String {
fn from(err: std::io::Error) -> Self {
format!("{}", err)
}
}
fn read_file() -> Result<String, String> {
let mut file =
File::open("example.txt")?;
let mut contents = String::new();
file.read_to_string(&mut contents)?;
Ok(contents)
}
咦,不通过,提示:
error[E0117]: only traits defined in the current crate can be implemented for types defined outside of the crate
--> src/lib.rs:4:1
|
4 | impl From<std::io::Error> for String {
| ^^^^^--------------------^^^^^------
| | | |
| | | `String` is not defined in the current crate
| | `std::io::Error` is not defined in the current crate
| impl doesn't use only types from inside the current crate
|
= note: define and implement a trait or new type instead
发现它违反了 第 9 讲 我们说过的trait孤儿规则。怎么解决呢?好办,重新定义一个自己的类型就可以了,你可以看一下修改后的代码。
use std::fs::File;
use std::io::Read;
struct MyError(String); // 用newtype方法定义了一个新的错误类型
impl From<std::io::Error> for MyError {
fn from(err: std::io::Error) -> Self {
MyError(format!("{}", err))
}
}
fn read_file() -> Result<String, MyError> {
let mut file =
File::open("example.txt")?;
let mut contents = String::new();
file.read_to_string(&mut contents)?;
Ok(contents)
}
这下就对了。
示例里,我们在第4行用newtype模式定义了一个自定义错误类型,里面包了String类型,然后在第6行对它实现 From<std::io::Error>,在第8行产生了错误类型实例。然后在第12行,把 read_file() 的返回类型改成了 Result<String, MyError>。
这样就可以了,如果出现打开文件错误或者读取文件错误, ? 操作符会自动把std::io::Error类型转换到我们的MyError类型上去,并从 read_file() 函数里返回。不再需要我们每次手动写 map_err 转换错误类型了。整个代码结构看上去非常清爽,我们得到了一个非常不错的解决方案。
利用 ? 操作符,我们可以在函数的嵌套调用中实现一种冒泡式的错误向上传递的效果。
错误处理系统最佳实践
有了前面的铺垫,下面我们来讲一下Rust中的错误处理系统最佳实践是什么。
错误的冒泡
通常我们编写的软件有很多依赖,在每个依赖甚至每个模块中,可能都有对应的错误子系统设计。一般会以一个crate为边界暴露出对象的错误类型及可能相关的处理接口。因此,如果我们从依赖树的角度来看,你编写的软件的错误系统也是以树的形式组织起来的,是一个层级系统。
在层级错误系统中,某一层出现的错误有的会在那一层处理,但有的也不一定会在那一层处理掉,而是采用类似冒泡的方式传递到更上层来处理。前面讲到的 ?操作符就是用于编写冒泡错误处理范式的便捷设施。
那么从下层传上来的错误,具体应该在哪个层次进行处理呢?这个问题没有统一的答案,是由具体的软件架构设计决定的。一般来说,一个软件它本身的架构也是在不断演进的,很可能开始的时候,你会在中间某一层给出一个处理方案,但是随着架构演化,可能最后会往上抛,甚至抛到界面层,抛给你的用户来处理。情况千变万化,需要具体问题具体分析。
那么,有没有最佳实践呢?经过Rust社区几年的探索,目前确实有一些实践经验得到了较高的评价,我们这里就来介绍一下。
前面讲过,一个完整的错误系统包括:错误的构造和表示、错误的传递、错误的处理。首先就是在错误的构造和表示上,目前Rust生态中有一个很棒的库: thiserror。
错误的表示最佳实践
前面我们讲过,我们定义的错误类型得实现std::error::Error 这个trait,才是一个在生态意义上来讲合格的错误类型。但是要靠自己完整地手动去实现这个Error,需要写不少重复的冗余代码。因为对于一个可靠的应用来说,每一个模块都可能会有其错误类型。
所以一个完整的软件,就会有非常多的错误类型,每次都写同样的样板代码,大家都不会喜欢。于是就出现了这样一个库 thiserror,它能为我们一体化标注式地生成那些样板代码。
使用 thiserror 的方式如下:
use thiserror::Error; // 引入宏
#[derive(Error, Debug)] // 这里derive Error宏
pub enum DataStoreError {
#[error("data store disconnected")] // 属性标注
Disconnect(#[from] io::Error), // 属性标注
#[error("the data for key `{0}` is not available")]
Redaction(String),
#[error("invalid header (expected {expected:?}, found {found:?})")]
InvalidHeader {
expected: String,
found: String,
},
#[error("unknown data store error")]
Unknown,
}
利用thiserror,我们可以直接在枚举上drive Error宏。这就方便得多了。在这一个大宏的下面,还可以利用 #[error("")]、 #[from] 等属性宏对枚举的变体做更多的配置。
通过这样的标注,我们把目标类型转换成了一个合格的被Rust生态认识的错误类型。
错误的传递最佳实践
前面我们已经多次提到过,在Rust中使用 ? 操作符就能方便地进行错误的冒泡传递。不过需要注意的是, ? 返回的错误类型可能与函数返回值定义的错误类型不一样,遇到这种情况,就要手动做 map_err,手动实现 From<T> trait,或者利用thiserror 里提供的 #[from] 属性宏标注。
错误处理最佳实践
错误处理指的是要对传过来的错误进行处理。Rust生态中有一个anyhow crate,非常好用。
anyhow这个crate,提供了一套方便的功能,让我们可以快速(无脑)地接收和处理错误。你可以统一使用 Result<T, anyhow::Error> 或等价的 anyhow::Result<T> 作为一个函数的返回类型,担当错误的接收者。
这意味着什么呢?以前你需要自己定义一个模块级的Result,才能简写 std::result::Result。模块层级多了后,光维护这些Result类型,都是一件头痛的事情。
struct MyError;
type Result<String> = std::result::Result<String, MyError>;
现在你不需要自定义一个 Result type了。直接使用 anyhow::Result<T> 就可以。
fn foo() -> anyhow::Result<String> {}
这有什么好处呢?实际是又在一个更高的层次上定义了一种错误接收协议——你写的任何模块,都可以用这同一种定义,而不需要在不同的模块中定义不同的Result类型。不同的人也不需要定义各自的Result类型,大家都一样的,使用anyhow::Result就行了,这样交流起来就更方便。
使用 anyhow::Result<T> 作函数返回值,你在函数中可以使用 ?操作符来把错误向上传递,只要这个错误类型实现了std::error::Error 这个 trait 就行了。而我们前面讲过,这个trait是std标准库中的一个标准类型,如果你想让自己的错误类型融入社区,都应该实现这个trait。而前面的thiserror也是方便实现这个trait的一个工具库。这样是不是一下子就串起来了。std、anyhow 和 thiseror 可以无缝配合起来使用。
这样就产生了一个什么样的效果呢?你不用再为错误类型的不一致,也就是向上传递的错误类型与函数返回值的错误类型不一致,而头痛了。所以我们可以无脑写出下面的代码:
use anyhow::Result;
fn get_cluster_info() -> Result<ClusterMap> {
let config = std::fs::read_to_string("cluster.json")?;
let map: ClusterMap = serde_json::from_str(&config)?;
Ok(map)
}
注意,上面第4行返回的错误类型和第5行返回的错误类型是不同的,但是都能无脑地扔给anyhow::Result,因为它们都实现了 std::error::Error trait。
当你使用 anyhow::Result<T> 接收到错误实例之后,下一步就是处理错误。可以使用 match 结合downcast 系列函数进行处理。
match root_cause.downcast_ref::<DataStoreError>() {
Some(DataStoreError::Censored(_)) => Ok(..),
None => Err(error),
}
因为 anyhow::Result<T> 定义的是统一的错误类型接收载体,所以在实际处理的时候,需要把错误还原成原来的类型,分别进行处理,这也是为什么需要 downcast 的原因,语法就和上面的示例差不多。这里也隐含了一个知识点,就是anyhow::Error其实保留了错误实例的原始类型信息,有了这些信息后面我们才能做正确的错误处理分派。
除此之外,anyhow还提供了几个辅助宏,用于简化错误实例的生成。其中一个是anyhow! 宏,它可以快速地构造出一次性的能被 anyhow::Result<T> 接收的错误。
return Err(anyhow!("Missing attribute: {}", missing));
可以看到,anyhow这个crate直接把Rust的错误处理的体验提升了一个档次,让我们可以以一种统一的形式设计项目的错误处理系统。std、anyhow和thiserror 它们一起构成了Rust语言错误处理的最佳实践。
注:更多anyhow的资料,请查阅 链接。
小结
这节课我们系统性地介绍了Rust语言的错误处理相关的知识,同时也介绍了目前Rust生态中已经探索出来的错误处理的最佳实践。
Rust本身只提供了一些基础设施, Result<T, E>、 std::error::Error trait、 map_err、 ? 表达式、 From<T> trait、 panic! 系列宏等等。这些设施已经非常好了,但是在构建中大型工程的错误系统的时候,会比较繁琐,标准也没办法统一。
因此在这些基础设施之上,社区通过实践摸索出了 thiserror、anyhow 等优秀的crate,使Rust语言错误处理的工程体验提升了一个层次,达到了既好用又优美的状态。这两个库充分展现了Rust语言强大的表达能力,anyhow 主要通过Rust强大的类型系统实现,thiserror主要通过Rust强大的宏能力实现,而宏正是我们下节课要讲到的内容。
错误处理是软件中非常重要的组成部分,是软件稳定性和安全性的根源所在。Rust语言强迫我们必须做完善的错误处理,这也是Rust语言与众不同的地方。希望你足够重视,多实践,总结出自己的心得。
思考题
- 请你查阅Rust std资料,并说说对 std::error::Error 的理解。
- 请说明anyhow::Error与自定义枚举类型用作错误的接收时的区别。
欢迎你把你的思考和理解分享到评论区,和我一起讨论,如果你觉得有收获的话,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
Rust的宏体系:为自己的项目写一个简单的声明宏
你好,我是Mike,今天我们一起来学习Rust语言中有关宏的知识。
宏是一套预处理设施。它的输入是代码本身,对代码进行变换然后输出新的代码。一般来说,输出的新代码必须是合法的当前语言的代码,用来喂给当前语言的编译器进行编译。
宏不是一门语言的必备选项,Java、Go等语言就没有宏,而C、CPP、Rust等语言有宏,而且它们的宏工作方式不一样。
在Rust语言中,宏也属于语言的外围功能,用来增强Rust语言的核心功能,让Rust语言变得更方便好用。宏不属于Rust语言的核心,但这并不是说宏在Rust中不重要。其实在Rust代码中,宏随处可见,掌握宏的原理和用法,有助于我们编写更高效的Rust代码。
在Rust中,宏的解析和执行是在Rust代码的编译阶段之前。你可以理解成,在Rust代码编译之前有一个宏展开的过程,这个过程的输出结果就是完整版的Rust代码,然后Rust编译器再来编译这个输出的代码。
Rust语言中的宏
当前版本的Rust中有两大类宏:声明宏(declarative macro)和过程宏(procedure macro),而过程宏又细分成三种:派生宏、属性宏和函数宏。
下面我们分别介绍一下它们。
声明宏
声明宏是用 macro_rules! 定义的宏,我们常见的 println!()、 vec![] 都是这种宏。比如 vec![] 是按类似下面这种方式定义的:
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}
注:代码来自官方 The Book,这是一个演示版的定义,实际的 vec! 的定义比这个要复杂得多。
这是什么代码?完全看不懂,不是正常的Rust代码吧?是的,为了对Rust代码本身进行操作,需要重新定义一套语法形式,而这种语法形式,只在 macro_rules! 里有效。
宏整体上来说,使用了一种 代码匹配 + 生成机制 来生成新的代码。上面代码里的 $() 用来匹配代码条目。 $x:expr 表示匹配的是一个表达式,匹配后的条目用 $x 代替。 * 表示前面这个模式可以重复0次或者1次以上,这个模式就是 $( $x:expr ),,注意 $() 后面有个 , 号,这个逗号也是这个模式中的一部分,在匹配的时候是一个可选项,有就匹配,遇到最后一个匹配项的时候,就忽略它。 => 前面是起匹配作用的部分, => 后面是生成代码的部分。
在生成代码的部分中, $() 号和 => 前面那个 $() 的作用差不多,就是表明被包起来的这块代码是可重复的。紧跟的 * 表示这个代码块可以重复0次到多次。具体次数等于 => 号前面的 * 号所代表的次数,两个一致。下面我们创建一个拥有三个整数元素的Vec。
let v = vec![1,2,3];
代码展开后实际就是:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}
你可以看到, temp_vec.push(); 重复了3次,这是因为 1,2,3 匹配 $x: expr,匹配了3次,分别匹配出 1、2、3 三个整数。然后就生成了三行 temp_vec.push();。
你可能会问, vec![] 这对中括号哪里去了?其实在Rust中,你用 ()、[]、{} 都可以,比如:
let a = vec!(0, 1, 2);
let b = vec![0, 1, 2];
let c = vec! { 0, 1, 2 };
不过也确实存在一些习惯性的表述,比如对于Vec这种列表,用 [] 显得更地道,其他语言也多用 [],这样能够和程序员的习惯保持一致。对于类函数式的调用,使用 () 更地道。对于构建结构体之类的宏或者存在大段代码输入的情况,用 {} 更合适。
现在你是不是能读懂一点了?
上面代码里的expr表示要匹配的item是个表达式。常见的匹配方式有7种。
- expr:匹配表达式
- ty:匹配类型
- stmt:匹配语句
- item:匹配一个item
- ident:匹配一个标识符
- path:匹配一个path
- tt:匹配一个token tree
完整的说明,你可以看我给出的参考 链接。
常见的重复符号有3个。
*表示重复0到多次。+表示重复1到多次。?表示重复0次或1次。
利用刚刚学到的知识,我们可以自己动手写一个声明宏。
自己动手写一个声明宏
目标: 实现一个加法宏 add!(1,2),输出结果 3。
你可以看一下示例代码。
macro_rules! add { // 第一个分支,匹配两个元素的加法 ($a:expr, $b:expr)=>{ { $a+$b } }; // 第二个分支:当只有一个元素时,也应该处理,这是边界情况 ($a:expr)=>{ { $a } } } fn main(){ let x=0; let sum = add!(1,2); // 调用宏 let sum = add!(x); }
通过示例我们可以看到,声明宏里面可以写多个匹配分支,Rust会根据匹配到的模式自动选择适配的分支进行套用。
我们可以用 cargo expand 来展开这个代码。
展开后实际是下面这个样子。
#![feature(prelude_import)] #[prelude_import] use std::prelude::rust_2021::*; #[macro_use] extern crate std; macro_rules! add { ($a : expr, $b : expr) => { { $a + $b // 第一个分支,匹配两个元素的加法 } } ; ($a : expr) => { { $a // 第二个分支:当只有一个元素时,也应该处理,这是边界情况 } } } fn main() { let x = 0; let sum = { 1 + 2 }; // 调用宏 let sum = { x }; }
请你仔细对比展开前后的代码,好好理解一下。不过,仅仅是两个元素的相加,写个宏好像多此一举了。下面我们把它扩展到多个数字的加法。
macro_rules! add { ( $($a:expr),* ) => { { // 开头要有个0,处理没有任何参数传入的情况 0 // 重复的块 $( + $a )* } } } fn main(){ let sum = add!(); let sum = add!(1,2,3,4); }
你可以看一下它展开后的样子。
#![feature(prelude_import)] #[prelude_import] use std::prelude::rust_2021::*; #[macro_use] extern crate std; macro_rules! add { ($($a : expr), *) => { { 0 $(+ $a) * // 开头要有个0,处理没有任何参数传入的情况 // 重复的块 } } } fn main() { let sum = { 0 }; let sum = { 0 + 1 + 2 + 3 + 4 }; }
可以看到,经过简单的改造,我们的 add!() 宏现在能处理无限多的相加项了。如果有时间,你可以进一步考虑如何处理总和溢出的问题。
我们可以先从这种简单的宏入手,边写边展开看效果,实现一个声明宏并不难。
macro_export
在一个模块中写好声明宏后,想要提供给其他模块使用的话,你得使用 #[macro_export] 导出,比如:
mod inner {
super::m!();
crate::m!();
}
mod toexport {
#[macro_export] // 请注意这一句,把m!()导出到当前crate root下了
macro_rules! m {
() => {};
}
}
fn foo() {
self::m!(); // main函数在当前crate根下,可这样调用m!()
m!(); // 直接调用也是可以的
}
#[macro_export] 可以把你定义的宏导出到当前 crate 根下,这样在 crate 里可以用 crate::macro_name! 访问(例子里的第3行 crate::m!()),在其他crate中可以使用 use crate_name::macro_name 导入。比如,我们假设上面代码里crate的名字是 mycrate,在另一个程序里可以这样导入这个宏。
use mycrate::m;
fn bar() {
m!();
}
macro_use
前面我们使用了 use mycrate::m 这种精确的路径来导入 mycrate 中的 m!() 宏。如果一个crate里的宏比较多,我们想一次性全部导入,可以使用 #[macro_use] 属性,一次导入一个crate中所有已导出的宏,像下面这种写法:
#[macro_use] extern crate rocket;
不过这种写法算是Rust早期的遗留写法了,更推荐的还是用到哪个宏就引入哪个宏。有些代码库中还会有这种写法出现,你看到了需要知道是什么意思。
认识过程宏之派生宏
常见的结构体上的derive标注,就是派生宏。比如我们 上一节课 讲到的 thiserror 提供的 Error 派生宏。
use thiserror::Error;
#[derive(Error, Debug)] // 派生宏
pub enum DataStoreError {
#[error("data store disconnected")] // 属性宏
Disconnect(#[from] io::Error), // 属性宏
#[error("the data for key `{0}` is not available")] // 属性宏
Redaction(String),
#[error("invalid header (expected {expected:?}, found {found:?})")] // 属性宏
InvalidHeader {
expected: String,
found: String,
},
#[error("unknown data store error")] // 属性宏
Unknown,
}
上面示例中的 Debug 和 Error 就是派生宏。Debug 宏由std提供,Error由thiserror crate 提供。使用的时候,我们先使用use将宏导入到当前crate的scope。然后在 #[derive()] 中使用它。
#[derive(Error, Debug)]
它会作用在下面紧跟着的 enum DataStoreError 这个类型上面,对这个类型进行某种代码变换操作。最后的实现效果就是帮助我们实现了 std::error::Error 这个trait,以及对应的 Debug、Display 等trait。在我们看来,写上这一句话,就好像Rust自动帮我们完成了那些实现,给我们省了很多力气。
想看它到底在 enum DataStoreError 类型上施加了哪些魔法,只需要运行 cargo expand 展开它就可以了。你可以自己动手做一下实验。
在这个enum DataStoreError里的变体上,我们还可以看到另外两个宏 #[error()] 和 #[from],它们不是派生宏,而是过程宏中的属性宏。
认识过程宏之属性宏
Rust编译器提供了一些属性(Attributes),属性是施加在模块、crate或item上的元数据。这些元数据可用于很多地方。
- 代码条件编译;
- 设置 crate 名字,版本号和类型(是二进制程序还是库);
- 禁止代码提示;
- 开启编译器特性(宏、全局导入等);
- 链接到外部库;
- 标记函数为单元测试;
- 标记函数为性能评测的一部分;
- 属性宏;
- ……
要把属性施加到整个crate,语法是在crate入口,比如在 lib.rs 或 main.rs 的第一行写上 #![crate_attribute]。
如果只想把属性施加到某个模块或者item上,就把 ! 去掉。
#[item_attribute]
属性上面还可以携带参数,可以写成下面几种形式:
#[attribute = "value"]#[attribute(key = "value")]#[attribute(value)]
我们来看一下具体的例子。
// 声明这个 crate 为 lib,是全局性的属性
#![crate_type = "lib"]
// 声明下面这个函数为单元测试函数,这个属性只作用在test_foo()函数上
#[test]
fn test_foo() {
/* ... */
}
// 条件编译属性,这块深入下去细节非常多
#[cfg(target_os = "linux")]
mod bar {
/* ... */
}
// 正常来说,Rust中的类型名需要是Int8T这种写法,下面这个示例让编译器不要发警告
#[allow(non_camel_case_types)]
type int8_t = i8;
// 作用在整个函数内部,对未使用的变量不要报警
fn some_unused_variables() {
#![allow(unused_variables)]
let x = ();
let y = ();
let z = ();
}
如果你开始写原型代码的时候,经常出现变量或函数未使用的情况,Rust编译器会提示一堆,有时看着心烦,你可以在crate入口文件头写上两行内容。
#![allow(unused_variables)]
#![allow(dead_code)]
fn foo() {
let a = 10;
let b = 20;
}
它会压制Rust编译器,让Rust编译器“放放水”。你可以试着把前面两行注释掉,看看Rust编译器会提示什么。但是对于一个严肃的项目来说,应该尽可能地消除这些“未使用”的警告,所以项目写到一定程度,就要把这种全局属性去掉。
Rust中有非常丰富的属性,它们给Rust编译器提供了非常强大的配置能力。要掌握它们,需要花费大量的时间,你可以看一下 Attributes 相关资料。这也印证了Rust的适用面极其广泛。即使一个熟练的程序员,也没必要掌握全部,只需要了解其中的常见属性就可以。然后在遇到一些具体的场景时,再深入研究那些配置。
而如果我们要定义自己的“属性”,就需要通过属性宏来实现。这属于偏高级而且用得比较少的内容,需要的时候再去学习也来得及。具体的实现可以参考我给出的链接。
- https://earthly.dev/blog/rust-macros/
- https://doc.rust-lang.org/beta/reference/procedural-macros.html
比如著名的Web开发框架Rocket,就使用属性宏来配置URL mapping。
#[macro_use] extern crate rocket;
#[get("/<name>/<age>")] // 属性宏
fn hello(name: &str, age: u8) -> String {
format!("Hello, {} year old named {}!", age, name)
}
#[launch] // 属性宏
fn rocket() -> _ {
rocket::build().mount("/hello", routes![hello])
}
可以看到,有了属性宏的加持,Rust代码在结构上变得相当紧凑而有美感,跟Java的Spring框架有点相似了。
认识过程宏之函数宏
在某些特定的情况下,函数宏能更好地表达业务需求,比如写SQL语句。我们在Rust中撰写SQL语句,必须符合Rust的语法,因此,一般使用字符串来构造和传递SQL语句,比如:
fn foo() {
let sql = "select title, content from article where id='1111111';";
}
其实就不是那么方便,还容易出错。如果用函数宏来实现的话,可以做到如下效果:
// 这是伪代码
use sql_macros::sqlbuilder;
fn foo() {
sqlbuilder!(select title, content from article where id='1111111';);
}
这样写,就好像在一个在SQL编辑器里面写SQL语句一样,非常自然,而不是把SQL语句写成字符串的形式了。也就是说,可以在Rust代码中写非Rust语法的代码,有没有感觉很神奇。当你想自己造一个DSL(领域特定语言 Domain Specific Language )时,函数宏就可以派上用场了。
函数宏是过程宏的一种,也使用过程宏的方式来实现,相关信息可参考我给出的 链接。目前社区中关于过程宏完整而细致的教程并不多,后面我会出一系列这方面的专题教程。
宏的应用
综上,我们可以看到,利用宏可以做到以下几方面的事情。
- 减少重复代码。如果有大量的样板代码,可以使用声明宏或派生宏让代码变得更简洁、紧凑。
- 为类型添加额外能力。这是派生宏和属性宏的强大威力。
- 创建DSL。可以自己创建一种新的语言,利用Rust编译器在Rust中编译运行,而不需要你自己再去写一个单独的编译器或解释器了。
- 变换代码实现任意自定义目标。本质上来说,宏就是对代码的变换,并且是在真正的编译阶段之前完成的,因此你可以用宏实现任意天马行空的想法。
小结
宏在Rust里无处不在,我们学习的第一步是要认识它们,知道它们的作用,熟悉常见宏的意义和用法。然后要初步掌握写简单的声明宏的写法,这样能有效地提升你精简业务代码的能力。但同时也要注意,使用宏不能过度,宏的缺点是比较难调试,IDE对它的支持可能也不完美。滥用宏会导致代码难以理解。
过程宏的能力非常强,书写的难度也比较大,我们目前不需要掌握它的写法。当你遇到一个过程宏的时候,你可以先查阅文档,知道它的作用,做到会用。等遇到需要的场景的时候,再去深入钻研。
这节课我们还提到了一个用来展开宏代码的工具cargo expand,经常使用它,对你学习宏会有很大帮助。
思考题
学完这节课的内容,你可以查阅一下相关资料,说一说 allow、 warn、 deny、 forbid 几个属性的意义和用法。欢迎你把查阅到的内容分享到评论区,如果觉得有收获的话,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
生命周期:Rust如何做基本的生命周期符号标注?
你好,我是Mike,今天我们来了解一下Rust中的生命周期到底是什么。
你可能在互联网上的各种资料里早就见到过这个概念了,生命周期可以说是Rust语言里最难理解的概念之一,也是导致几乎所有人都觉得Rust很难,甚至很丑的原因。其实对于初学者来说,至少在开始的时候,它并不是必须掌握的,网上大量的资料并没有指明这一点,更加没有考虑到的是应该如何让初学者更加无痛地接受生命周期这个概念,而这也是我们这门课程尝试解决的问题。
下面让我们从一个示例说起,看看为什么生命周期的概念在Rust中是必要的。
从URL解析说起
URL协议类似下面这个样子,可以粗略地将一个URL分割成5部分,分别是 protocol、host、path、query、fragement。
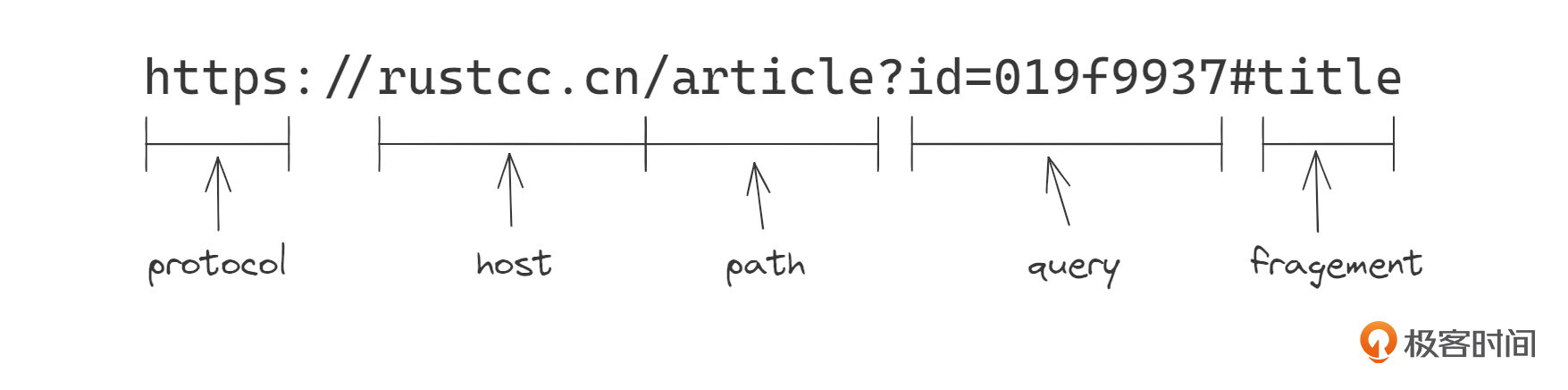
现在我们拿到一个URL字符串,比如就是图片里的这个。
let s = "https://rustcc.cn/article?id=019f9937#title".to_string();
现在要把它解析成Rust的结构体类型,按照我们已掌握的知识,先定义URL结构体模型,定义如下:
struct Url {
protocol: String,
host: String,
path: String,
query: String,
fragment: String,
}
没有问题,URL图示里的5大部分都已定义好了。解析出来大致就是这样一个效果。
let a_url = Url {
protocol: "https".to_string(),
host: "rustcc.cn".to_string(),
path: "/article".to_string(),
query: "id=019f9937".to_string(),
fragment: "title".to_string(),
};
这样完全没有问题,我们把一个字符串切割成5部分,转换成了一个结构体。不过这并不算一种高效的做法,在计算机系统里面,会做5次堆内存分配的操作。我们来看一下字符串转换成结构体之后栈和堆的示意图。
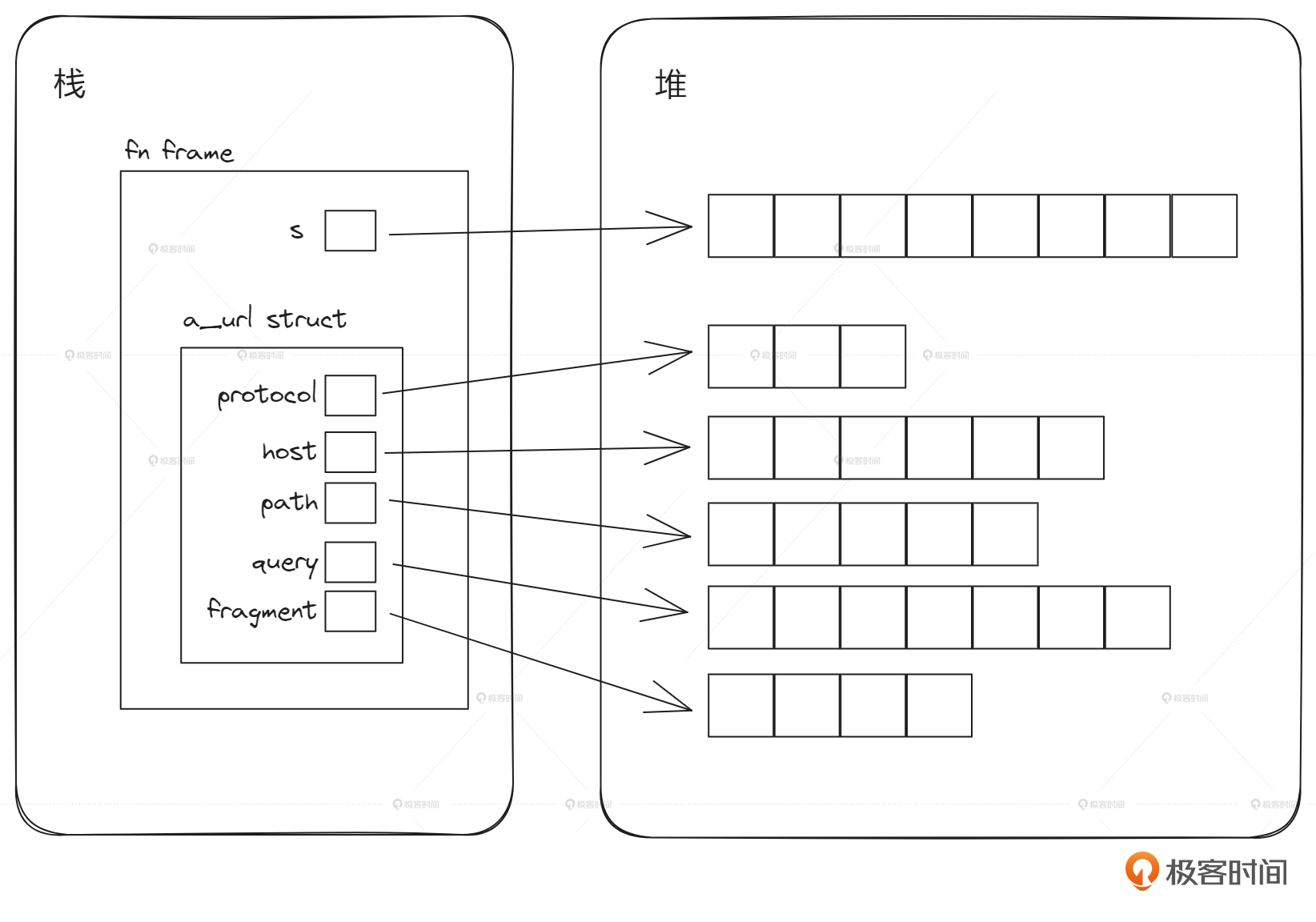
也就是说,我们把一个大的字符串,分成了5个小的字符串,并且每个小的字符串在堆里都单独分配了一块内存,原理上确实没问题,但从计算机科学来讲,5次堆内存的分配代价有点大。
那到底在性能上有什么问题呢?或者换句话问,有什么优化的方案呢?答案就是对于这种 只读解析,也就是没有修改需求的场景,我们不需要为每一个碎片单独分配一个堆内存,只需要定义5个切片引用就可以了。
在Rust语言里,你可以这样去定义这个结构体。
struct Url {
protocol: &str,
host: &str,
path: &str,
query: &str,
fragment: &str,
}
但是这样是没法通过编译的,需要加上一个东西,就是 <'a>。
struct Url<'a> {
protocol: &'a str,
host: &'a str,
path: &'a str,
query: &'a str,
fragment: &'a str,
}
然后像这样来创建Url实例。
let a_url = Url {
protocol: &s[..5],
host: &s[8..17],
path: &s[17..25],
query: &s[26..37],
fragment: &s[38..43],
};
然后,创建出来的内存结构是这样的:
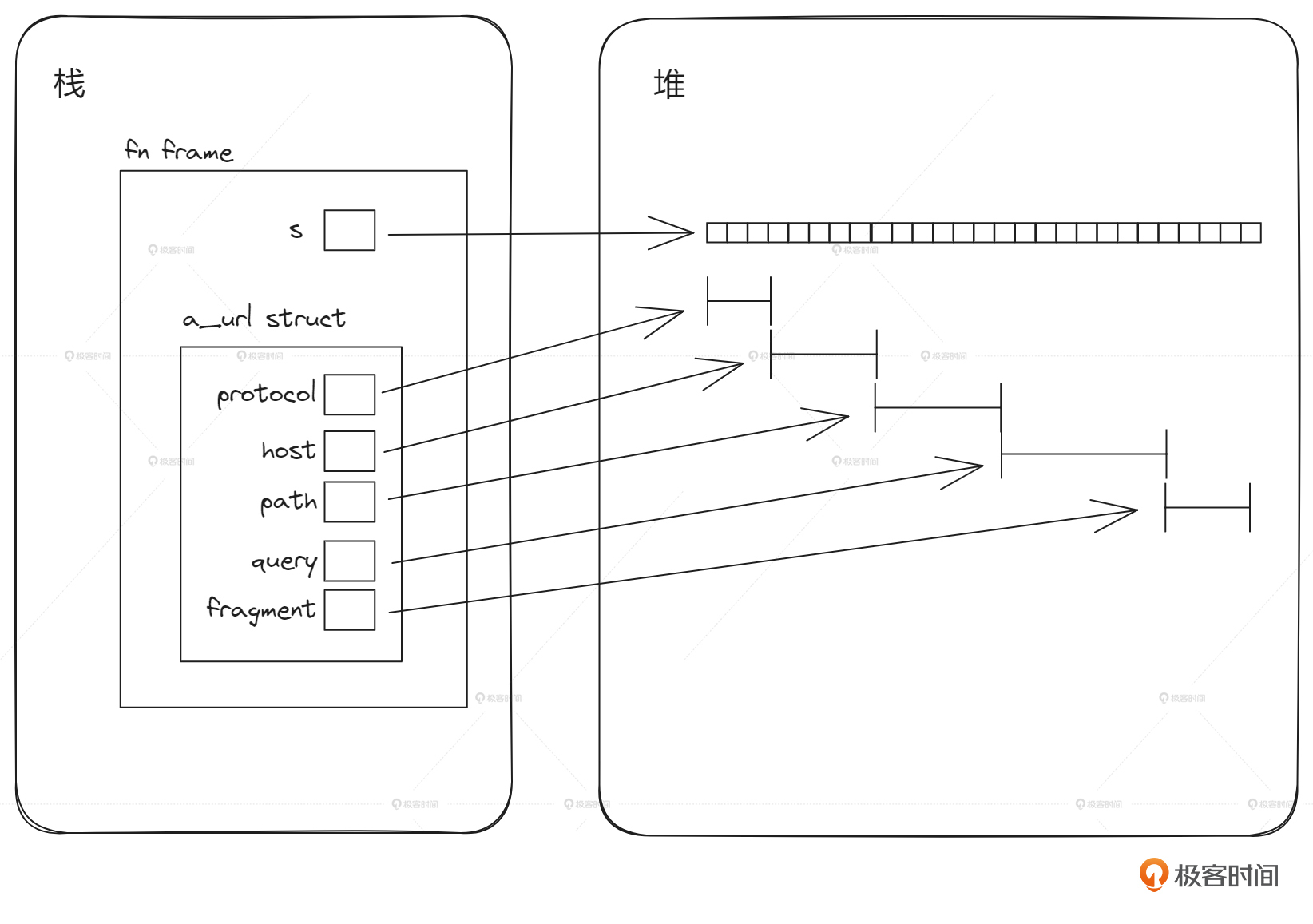
有看到区别吗?新的方式 Url 实例 a_url 里的5个字段 protocol、host、path、query、fragment 都只是存的切片引用,指向原始字符串s的某一个片断,不再单独分配一块块内存碎片了。这样整个过程就少分配了5次堆内存,解析出来的结构体占用内存比较少,而且解析过程中的性能很高。
这个示例反映了Rust语言的一大特点,就是 提供了最大的可能性,既可以简单粗暴侧重于易用性,先把东西做出效果,又可以用另外的方案从底层实现上做优化。 这种优化在Rust语言就能完成,而不需要借助额外的语言或设施。
从这个示例,我们引出了这样一种符号 'a。
struct Url<'a> {
protocol: &'a str,
host: &'a str,
path: &'a str,
query: &'a str,
fragment: &'a str,
}
它是什么呢?
Rust中的生命周期
'a 这种符号是引用的生命周期符号,用来标识一个结构体里是否有对外部资源的引用,从而帮助Rust的借用检查器(Borrow Checker)对引用的有效性进行 编译时 分析。
和大部分语言一样,在Rust里,任何变量都有scope,一般由最里层的花括号所定义。比如:
fn foo() -> {
let a = String::from("abc");
//
{
let b = String::from("def");
}
}
例子里,变量a的scope为从定义时开始,到第7行 foo() 函数的花括号结束。而变量b的scope为从定义时开始到第6行花括号结束。
但这个规则在Rust中只是针对所有权型变量的。对引用型变量来说,在Rust里有更严格的scope要求。
fn foo() -> {
let a = String::from("abc");
let a_ref = &a;
println!("{}", a_ref);
//
}
例子中,对于引用型变量 a_ref 来讲,由于它持有的是对所有权型变量a的引用, a_ref 实际的scope只是从第3行定义时开始到第4行最后一次使用时结束(这个规则我们在 第 3 讲 中已经验证过),到不了第6行的花括号。也就是说,Rust里的引用型变量的scope看起来总是要比对应的所有权型变量的scope要小。
这个很容易理解,因为所谓引用,就是必定有效的指针。 必定有效的意思就是,只要这个引用型变量还在,那它所指向的那个目标对象就一定在。Rust中采用的是彻底的静态分析技术(相对于运行时检查),希望在编译期间能够清楚地计算出每个资源,还有指向这个资源的引用的有效存在区间。要准确,既不能多,也不能少,并且两个要匹配好。于是Rust引入了所有权的设计,来描述对资源的管理。这是一个根上的设计,它的引入不可避免地带来了一整套后续的机制。
- 借用与引用
- 不可变引用
- 可变引用
- 引用的生命周期分析
所有权的生命周期scope的分析是比较简单的,用所在层次花括号规则就可以处理。难点在于引用的生命周期scope的分析,这个工作就是由Borrow Checker来做的。因为代码逻辑可能非常复杂,很难找到一种智能的方法可以通用地并且完全正确地处理所有代码中的引用。这非常困难,编程语言发展了几十年,其他语言要么如C这种放弃治疗,把这个问题全部交给程序员自己处理,要么像 Java 这种引入GC层,用GC来统一管理对资源的引用。
因此目前阶段Rust还需要我们程序员人为地为它提供一些信息标注,而 'a 就是这样一种信息标注机制。有可能后面随着AI的蓬勃发展,未来能出现可靠的方案,我们就不再需要手动添加这些标注信息了,但目前还是需要的。
'a 代表某一片代码区间,这片代码区间就是被这种符号标注的引用的有效存在区间。
结构体中的引用
上面示例的结构体Url中, <'a> 是表示定义一个生命周期符号 'a,这个 'a 的名字可以任意取,比如取名 'abc、 'h、 'helloworld 等都是可以的。一般使用单小写字母表示,但是你如果看到单词形式的生命周期符号也不要惊讶。比如:
struct Url<'helloworld> {
protocol: &'helloworld str,
// ...
}
定义好 'a 符号后,需要标注到目标的引用上面去,上述示例中,&str的 & 和 str 之间,加 'a,写成 &'a str。这样就表示 结构体Url依赖一个外部资源,具体来说,是其protocol字段依赖于一个外部的字符串。在上述示例中,Url的5个字段都依赖于同一个外部字符串资源,因此只需要一个生命周期参数 'a 就行了。如果是依赖于不同的字符串资源,可以分开写成不同的生命周期参数 'a、 'b 等。比如:
struct Url<'a, 'b, 'c> {
protocol: &'a str,
host: &'a str,
path: &'b str,
query: &'b str,
fragment: &'c str,
}
上面的定义中,Url定义了三个生命周期参数 'a、 'b、 'c。从这个定义我们能清晰地看出,Url类型 可能 依赖于3个外部字符串资源。
当在类型上添加了生命周期符号标注后,对它做impl的时候也需要带上这个参数了。
struct Url<'a> {
protocol: &'a str,
host: &'a str,
path: &'a str,
query: &'a str,
fragment: &'a str,
}
impl<'a> Url<'a> { // 这里
fn play() {}
}
请注意上面代码里的第9行 impl 后定义的 <'a> 参数,你可以发现 'a 的地位好像与类型参数 T 类似。
生命周期符号 'a 具有传染性。比如,一个结构体用于构建另一个结构体字段的时候。
struct Url<'a> {
protocol: &'a str,
// ...
}
struct Request<'a> {
url: Url<'a>,
body: String,
// ...
}
上面示例里,Request结构体中包含一个Url结构体的实例,因为Url类型带生命周期参数 'a,因此Request中也 不得不 带上同一个生命周期参数 'a。这就是 生命周期参数的传染性。
这样标识是有好处的,因为Url的实例依赖于外部所有权资源,那么顺推Request类型的实例也要依赖于那些外部所有权资源。如果不标识,当嵌套层次过多了之后,你很难用肉眼分析出一个结构体类型到底是不是 自包含(self-contained,也就是由自己掌握涉及资源的所有权)的。
好在Rust的严格性,要求你必须依次一个不差地标识出来,这样就不会出现潜在的问题了。不过总的来说,生命周期符号 'a 主要还是帮助Rust编译器的,而不是给程序员看的。程序员的直观感觉是它非常丑陋而且带来语法噪音。
在目前的技术能力下,通过引入生命周期符号标注,Rust能实现精准地分析引用的有效期。
函数返回值中的引用
除了结构体中,在其他语言元素上也会出现引用的场景。一大场景就是函数返回值中带引用,我们看下面这个函数。
fn foo() -> &str {
let s = String::from("abc");
&s
}
我们想返回 foo 函数里的局部变量s的引用,可以吗?肯定是不可以的。所有权变量s在 foo() 函数执行完后就被回收了,返回对这个字符串资源的引用不就是悬挂指针了吗?编译提示如下:
error[E0515]: cannot return reference to local variable `s`
--> src/main.rs:3:5
|
3 | &s
| ^^ returns a reference to data owned by the current function
那么,一个函数中返回一个类型的引用,有几种可能的情况呢?只有两种,一种是返回对外部全局变量的引用;另一种是返回函数的引用参数所指向资源的引用。
我们先看第一种情况。
static ASTRING: &'static str = "abc";
fn foo() -> &str {
ASTRING
}
这是可以的。但实际这样写的价值不大,没多大用。
第二种情况:
fn foo(a: &str) -> &str {
a
}
这也是可以的,但这种只有一个引用类型的参数传入,再返回回去,好像也没多大意思。如果有多个引用类型的参数传入呢?比如:
fn foo(a: &str, b: &str) -> &str {
a
}
Rust编译器开始抱怨了。
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:29
|
1 | fn foo(a: &str, b: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `a` or `b`
help: consider introducing a named lifetime parameter
|
1 | fn foo<'a>(a: &'a str, b: &'a str) -> &'a str {
| ++++ ++ ++ ++
它抱怨说,你少写了一个生命周期参数,因为函数的返回类型中包含一个借用值,但是函数签名中没有说这个借用是来自a还是b。然后还给出了一个建议,在函数参数和返回类型上,都加上生命周期参数 'a,就是像下面这个样子。
fn foo<'a>(a: &'a str, b: &'a str) -> &'a str {
a
}
类似于在结构体上定义生命周期参数,在函数签名中,如果要引入生命周期参数,也需要先定义,就是定义在函数名 foo 后的 <> 里。先定义,再使用。定义之后,在后面的引用上才能使用这个符号。
但是我们函数实现中明确写了返回a的,感觉Rust略笨。实际上到目前为止,Rust只会基于函数签名,也就是传入传出的类型进行分析,而不会去分析函数体的实现,也就是不会去分析函数中的实现逻辑。只要返回值的类型没有问题,它就不会抱怨。我们再看一个示例。
fn foo(i: u32, a: &str, b: &str) -> &str {
if i == 1 {
a
} else {
b
}
}
// 也需要写成
fn foo<'a>(i: u32, a: &'a str, b: &'a str) -> &'a str {
if i == 1 {
a
} else {
b
}
}
这个示例中,到底返回a还是b,在编译期是没办法确定下来的,只能在运行的时候,由具体传入的 i 值来确定。不过,Rust分析的时候,不关心这个具体的逻辑,它只看函数签名中的引用之间,有没有可能会发生关联。
fn foo<'a>(a: &'a str, b: &'a str) -> &'a str {
在foo函数签名中出现了4次 'a 符号,除去第一个是定义 'a,后面3次都是使用 'a。这后面三个不同位置的 'a 的意义到底是什么呢?
首先,foo函数的两个参数a、b,它是外部字符串资源的引用。它们所指向的字符串资源,有两种情况:
- 为同一个字符串资源;
- 为两个不同的字符串资源。
第一种情况比较好理解,返回的引用仍然指向这个字符串资源,因此它们标注为同一个 'a 生命周期参数符号。
第二种情况稍微复杂一些。a和b指向的是不同的字符串资源,对应的资源我们标记为 Ra 和 Rb,Ra和Rb有各自的scope。a是Ra的引用,b是Rb的引用,我们强行在这两个不同资源的引用上标注相同的生命周期参数 'a,它一定是做了某种操作,提供一些额外的信息。
因为Ra和Rb的scope一般不一样,我们假设Rb资源先释放,Ra资源后释放。那我们首先要保证的是在 foo() 函数执行期间,Ra和Rb都存在。在a和b的类型上强制标识 'a, 实际上是给 'a 取了一个比较小的代码区间,也就是到Rb的资源释放的那一行代码为止。
同时我们还把 'a 标注到返回类型上,就 意味着将 'a 指代的生命周期区间施加到了返回的引用上。我们可以用下面这个示例来验证这个论断。
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } } fn main() { let s1 = String::from("long string is long"); let result; { let s2 = String::from("xyz"); result = longest(s1.as_str(), s2.as_str()); } println!("The longest string is {}", result); }
编译会报错:
error[E0597]: `s2` does not live long enough
--> src/main.rs:14:39
|
13 | let s2 = String::from("xyz");
| -- binding `s2` declared here
14 | result = longest(s1.as_str(), s2.as_str());
| ^^^^^^^^^^^ borrowed value does not live long enough
15 | }
| - `s2` dropped here while still borrowed
16 | println!("The longest string is {}", result);
| ------ borrow later used here
从我们肉眼分析来看,result变量最后取的是s1的引用,并没有借用s2,它应该是在main函数里一直有效的,就是第16行应该能打印出正确的值。但是编译却不通过,为什么呢?
就是因为 Rust是按生命周期来分析借用的,而不是靠函数逻辑。在这个例子里,Rust会分析出来, longest() 函数返回值的生命周期 'a,是到代码第15行,也就是s2被回收的地方,前面我们说过,会在s1和s2两个资源的scope中取较小的那个区间。也就是说,result这个引用型变量的scope到第15行为止,所以在第16行就不能再使用它了。这个例子你可以仔细体会一下。
是不是有点反直觉?如果靠我们人眼去分析,这个例子应该是可以正常打印的。这也是Rust初学者常常疑惑而且崩溃的地方,不太好懂。你可以骂一下,Rust傻。确实傻,目前分析领域的技术还做不到完美解决这个问题,所以有点傻,我们只能希望在未来的版本迭代中逐渐增强Rust的推理能力。
类型方法中的引用
回顾前面的内容,类型的方法只是第一个参数为Self的所有权或引用类型的函数。因此上面分析的函数返回值里引用的细节也适用于类型的方法。
比较特别的是,如果返回的值是Self本身或本身一部分的引用,就不用手动写 'a 生命周期符号,Rust会自动帮我们在方法返回值引用的生命周期和Self的scope之间进行绑定,这是一条默认的规则。
struct A {
foo: String,
}
impl A {
fn play(&self, a: &str, b: &str) -> &str {
&self.foo
}
}
我们稍稍改一下代码就没办法编译通过了。
struct A {
foo: String,
}
impl A {
fn play(&self, a: &str, b: &str) -> &str {
a
}
}
编译提示:
error: lifetime may not live long enough
--> src/lib.rs:8:9
|
7 | fn play(&self, a: &str, b: &str) -> &str {
| - - let's call the lifetime of this reference `'1`
| |
| let's call the lifetime of this reference `'2`
8 | a
| ^ method was supposed to return data with lifetime `'2` but it is returning data with lifetime `'1`
|
help: consider introducing a named lifetime parameter and update trait if needed
|
7 | fn play<'a>(&'a self, a: &'a str, b: &str) -> &str {
| ++++ ++ ++
解释说,本来我们期望方法返回类型的生命周期为Self的生命周期,结果你给我返回了另一个资源的生命周期,我并不认识那个资源,所以需要你手动标注。并且给出了修改建议,我们按建议修改一下。
struct A {
foo: String,
}
impl A {
fn play<'a>(&'a self, a: &'a str, b: &str) -> &str {
a
}
}
这下就可以通过了。可以看到上面示例里的play方法在参数a、参数self和返回值之间进行了绑定。
'static
在所有的生命周期参数符号里有一个是特殊的,那就是 'static,它代表所有生命周期中最长的那一个,和程序存在的时间一样长。它表示被标注的引用所指向的资源在整个程序执行期间都是有效的。比如:
fn main() { let s: &'static str = "I have a static lifetime."; }
上面这个示例应该很容易理解,因为字符串字面量是存储在静态数据区的,程序存在多久,它就存在多久,它对应的局部变量 s(&'static str)的生命周期也就跟着可以持续到程序结束。
因此 'static 是所有生命周期符号中最长的一个。
对生命周期的理解
为什么放在尖括号中?
在前面的讲解中我们看到,生命周期参数是放在 <> 尖括号里的。回想一下之前的知识点,只有类型参数才会放在尖括号里,为什么生命周期参数也放在这里面呢?
如果用一句话解释,那就是因为 生命周期参数跟类型参数一样,也是 generic parameter 的一种,所以放在尖括号里,它俩的地位相同。
我们的程序跑起来,哪些资源会在什么时间分配出来,哪些资源会在什么时间回收,其实是个运行期间的概念。也就是说,是个时间上的概念。但对计算机来讲,每一条指令的执行,是要花相对确定的时间长度的,所以就在要执行的CPU指令条数和执行时间段上产生了正比映射关系。这就让我们在代码的编译期间去分析运行期间变量的生存时间区间变成可能。这就是Rust能够做生命周期分析的原因。
当我们使用生命周期参数标注 'a 的时候,并不能知道它所代表的将要运行的准确时间区间,或者说代码区间。比如对于函数来说,有可能它只运行一次,也有可能运行多次,运行在不同次数的时候,同一个 'a 参数可能代表的代码区间是不一样的。举例如下:
fn foo<'a>(a: &'a str, b: &'a str) -> &'a str { a } fn main() { { let s1 = "abc".to_string(); let s2 = "def".to_string(); let s3 = foo(&s1, &s2); println!("{}", s3); } // ... let s4 = "ghk".to_string(); let s5 = "uvw".to_string(); let s6 = foo(&s4, &s5); println!("{}", s6); }
在上面示例中, foo() 函数被调用了两次。在第一次调用的时候, 'a 代表的生命周期区间是到第11行的花括号截止。在第二次调用的时候, 'a 代表的生命周期区间是到第17行的花括号截止。所以两次 'a 的值是不同的。这也是我们要把 'a 叫做生命周期参数的原因。
'a 代表代码区间或时间区间,在编译的时候,通过分析才会确定下来。因此和类型参数类似,我们也要把这种生命周期参数放到尖括号里定义。 类型参数是空间上的展开(分析),生命周期参数是时间上的展开(分析)。
关于 'a 的语法噪音
前面我们讲解了Rust引入生命周期分析和生命周期参数标注符号的必要性和原因。但是不管怎样,这样的符号如果大量出现在代码中,会让代码变得很丑,充满噪音。
确实是这样的。至于当初为什么选择 'a 这种符号而不是其他符号,这个就不得而知了。也有可能键盘上的符号都差不多用完了,所以好像也没有其他更好的符号可以选。
好在你去阅读Rust生态里的代码的时候, 'a 符号出现的频率并不高。特别是在偏上层的业务代码中,我们几乎见不到 'a 符号。
什么时候可能会写生命周期参数?
什么时候会倾向于写生命周期参数呢?一般写底层库或对代码做极致性能优化的时候。
如果只是写上层的业务,我们基本不会有写生命周期参数符号的需求。Rust的一些机制比如智能指针,能保证我们在只持有自包含类型的情况下,也能得到非常高的性能。一般来说,写代码有三个阶段。
首先是先跑通,完成需求。Rust的起点较高,使用Rust写出来的代码不需要怎么优化,就能让你在大部分情况下赢在起跑线上。
第二阶段是,追求架构上的美感。当你完成第一阶段验证,并稳定运行后,你可能会追求更好的架构,更漂亮的代码。这个时候,你可以在Rust中的所有权三态理论、强大的类型系统、灵活的trait抽象能力的指导下重构你的项目。有聪明的Rust小助手在,你的重构之路会变得异常轻松。
第三个阶段才是当你在业务上真正遇到性能瓶颈的时候,再回过头来优化。Rust极高的上限和可容纳任何机制的能力,让你无需借助其他语言就能完成优化任务。你可以选择使用引用和生命周期分析,减少内存分配次数,从而提升性能。当然,性能优化是一项综合性的课题,Rust不能帮你解决所有问题。
关于API的最佳实践
在库的API设计上,Rust社区有一条共识:不要向外暴露生命周期参数。这样才能让API的使用更简单,并且不会把生命周期符号传染到上层。
一个反例就是std里Cow类型的设计,导致现在很少有人会优先选择使用Cow类型。
pub enum Cow<'a, B> {}
你可以查阅 链接 了解更多内容。
小结
所有权、借用(引用)、生命周期,这三兄弟是Rust中的一套高度耦合的概念,它们共同承担起了Rust底层的脏活累活,彻底扫清了最困难的障碍——正确高效地管理内存资源,为Rust实现安全编程和高性能编程打下了最坚实的基础。
所有权贯穿了Rust语言的所有主要特性,对应地,如果你继续深入钻研下去,你会发现生命周期概念也会贯穿那些特性。但是另外一方面,初学Rust也会有两个典型的认知错误。
- 我得把生命周期彻底掌握,才算学会Rust。
- 生命周期太难,我迈不过去只能放弃。
对这两种认知,我想说:即使你把生命周期掌握得很溜,也不代表你就能用好Rust。Rust是一门面向实用的语言,将Rust用好涉及大量的领域知识,这些都需要你花时间去学习。需要你有效地分配时间。前期初学的时候基本碰不到写生命周期符号的机会,理解到这节课所覆盖的内容就差不多了。所以你不要惧怕这个概念,用Rust来解决你的实际问题,不要害怕clone。
Rust牵涉面过于广泛,学习语言不是为了炫技,应该以实用为主,学以致用,边学边用。Rust没有天花板,这也意味着你的成长也不会有上限,加油吧!
思考题
你能说一说生命周期符号 'a 放在 <> 中定义的原因和意义吗?欢迎你把自己的理解分享到评论区,如果你觉得有收获的话,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!
答疑课堂(一)|第一章Rust基础篇思考题答案
你好,我是Mike。
恭喜你学完前两章的内容了,基础篇和进阶篇一共有20讲,每一讲的内容都很重要,算是你入门Rust的重要基础,所以一定要多读几遍,争取学透。为了让你学思结合,我们在每节课的最后设计了对应的思考题,这节课我们就来处理这些问题。
我也看到很多同学在课程的后面回答了这些问题,此外还有一些其他的问题,提得也很精彩,所以我挑出一并放在这里,希望能为你解惑,对你有所启发,话不多说,我们马上开始吧!
做完思考题再来看答案会更有收获。
基础篇
01|快速入门:Rust 中有哪些你不得不了解的基础语法?
思考题
- Rust 中能否实现类似 JS 中的 number 这种通用的数字类型呢?
- Rust 中能否实现 Python 中那种无限大小的数字类型呢?
答案
在 Rust 中,有多种数字类型,包括有符号和无符号整数、浮点数、复数等。和 JS 中的 number 类型相似,Rust 中的数字类型也支持基本的数学运算,例如加减乘除和取模等。不过,和 JS 的 number 不同,Rust 的数字类型都具有固定的位数,这意味着不同的数字类型有不同的取值范围。
此外,Rust 中的数值类型需要在编译时就确定它们的类型和大小,这些类型可以通过使用 Rust 内置的类型注解,或是灵活的小数点和后缀表示法来声明。而 crates.io 上有 num crate 可以用来表示通用的数字类型,具体是通过trait机制来实现的。
关于实现 Python 中无限大小的数字类型,Rust 不直接支持这个特性,但可以通过使用第三方库来实现。常用的第三方库包括 rug 和 num-bigint 等,它们提供了实现高精度计算的数据类型和函数,使 Rust 可以处理更大的整数和浮点数。这些库采用的是类似于 Python 的动态内存分配和存储机制,能够进行几乎无限大小的数字计算。
02|所有权(上):Rust 如何管理程序中的资源?
思考题
- 下面的示例将输出什么?
fn main() { let s = "I am a superman.".to_string(); for i in 1..10 { let tmp_s = s; println!("s is {}", tmp_s); } }
- 一个由固定尺寸类型组成的结构体变量,如下面示例中的Point类型,在赋值给另一个变量时,采用的移动方式还是复制方式?
struct Point {
x: i64,
y: i64,
z: i64
}
答案
- 无法通过编译,可以将第 5 行代码修改为:let tmp_s = s.clone();。
修改后如下:
fn main() { let s = "I am a superman.".to_string(); for _ in 1..10 { let tmp_s = s.clone(); println!("s is {}", tmp_s); } }
- 由于 Point 没有实现 Copy trait,所以在赋值过程中会产生 Move。如果结构体实现了 Copy trait,则会进行复制而不是移动。
答案来自二夕Thrower 和 Forest
03|所有权(下):Rust 中借用与引用的规则是怎样的?
思考题
- 请思考,为何在不可变引用存在的情况下(只是读操作),原所有权变量也无法写入?
fn main() { let mut a: u32 = 10; let b = &a; a = 20; println!("{}", b); }
- 请回答,可变引用复制的时候,为什么不允许copy,而是move?
答案
-
不可变引用的作用域跨越了所有权变量的写入过程,意味着同一个作用域同时存在可变引用和不可变引用,编译器为了防止读取错误,不能通过编译。可以把a = 20放到引用之前,即可编译通过。
-
可变引用如果可以Copy,就违反了可变引用不能同时存在的规则,因此只能Move。
不可变借用,从字面理解就是借出去了就不能变了,所以既然保证不变了,那这样的借用当然可以被借出去N次(原变量不可变是只限于在借出去的变量的有效生命周期内)。可变借用就是借出去随时有被改变的可能,在同一生命周期内借出去多次,有不确定性的被改变的风险,尤其在多线程中,所以就只让你借出去一次,既然存在有不确定性的被修改的可能,那这个时期肯定就不会让你再有不可以变借用了(因为随时会改变了,不可变借用本身也就不成立了)。Rust这个逻辑看似很繁杂,实则逻辑环环相扣清晰很符合常规。
答案来自Andylinge和Citroen
04|字符串:对号入座,字符串其实没那么可怕!
思考题
chars 函数是定义在 str 上的,为什么 String 类型能直接调用 str 上定义的方法?实际上 str 上所有的方法,String 都能调用,请问这是为什么呢?
答案
因此在String上实现了Deref trait,target为str。
另外补充一些字符串相关知识点。
Rust中 char 是用于存放unicode单个字符的类型(固定4个字节)。String类型只能放在堆上,通过引用所有权的形式和变量绑定,它的存储方式不是简单的char数组,而是utf8编码的字节序列,所以单独取这个序列的某一段切片,不一定能解析出具体的字符(程序里的 String[a..b],这里的a和b已经是经过特殊处理的保证截取的有效性)。
fn main() { let s = "abcdefghijk".to_string(); let a = &s[..5]; let s = "我爱中国".to_string(); let a = &s[..5]; } Running `target/debug/playground` thread 'main' panicked at src/main.rs:7:15: byte index 5 is not a char boundary; it is inside '爱' (bytes 3..6) of `我爱中国`
如果能取得有效的序列片段那就是str类型,但是程序里凡是用到绑定str类型变量的地方,则必须都是引用形式存在的(&str),因为str是引用的原始片段的那段真实数据,而&str类型是一个FatPointer,它包括引用目标的起始地址和长度,所以str和&str是完全两个不同的概念。
u8就是一个存储0到255大小的类型,因为一个字节就是8位,所以[u8, N]可以看做是程序的任何类型数据的二进制表示形式。
答案来自 Citroen
05|复合类型(上):结构体与面向对象特性
思考题
可以给 i8 类型做 impl 吗?
答案
基本数据类型无法实现impl,不过我们可以通过 trait给基本数据类型添加操作的方式来实现。
trait Operate { fn plus(self) -> Self; } impl Operate for i8 { fn plus(self) -> Self { self + self } } fn main() { let a = 1i8; println!("{}",a.plus()); }
另外可以用newtype模式对 i8 封装一下,再impl。
答案来自下雨天和约书亚
06|复合类型(下):枚举与模式匹配
思考题
match 表达式的各个分支中,如果有不同的返回类型的情况,应该如何处理?
答案
作为静态类型语言,match 返回的类型必须在编译期就被确定,也就意味着 match 必须返回相同的类型。在这个前提下,如果要返回不同的类型,那么切入点就只能是:“返回同一个类型,但是这个类型能表示(承载)不同的类型”,那就只能是本节课讲的枚举 enum 了。
enum Number { Int(i32), Float(f64), None } fn get_number(condition: i32) -> Number { match condition { 1 => Number::Int(10), 2 => Number::Float(3.14), _ => Number::None } } fn main() { let value = get_number(1); match value { Number::Int(i) => println!("int {}", i), Number::Float(f) => println!("float {}", f), Number::None => println!("not number"), } let value = get_number(2); match value { Number::Int(i) => println!("int {}", i), Number::Float(f) => println!("float {}", f), Number::None => println!("not number"), } let value = get_number(3); match value { Number::Int(i) => println!("int {}", i), Number::Float(f) => println!("float {}", f), Number::None => println!("not number"), } }
答案来自-Hedon 🍭
07|类型与类型参数:如何给 Rust 小助手提供更多信息?
思考题
如果你给某个泛型实现了一个方法,那么还能为它的一个具化类型再实现同样的方法吗?
答案
“为泛型实现了一个方法,能否再为具化类型实现一个同名方法”,取决于这个泛型能否表示相应的具化类型。比如为泛型 T 和 String 实现了相同的方法,由于 T 没有施加任何约束,它可以代表 String。那么当调用方法时,对于具化类型 String 来说,要调用哪一个呢?因此会出现歧义,编译器会报错:方法被重复定义了。
但如果给泛型 T 施加了一个 Copy 约束,要求 T 必须实现了 Copy trait,那么就不会报错了,因为此时 T 代表不了 String,所以调用方法不会出现歧义。但如果再为 i32 实现一个同名方法就会报错了,因为 i32 实现了 Copy,它可以被 T 表示。
答案来自古明地觉
08|Option、Result、迭代器及实际类型中所有权问题
思考题
你可以用同样的思路去研究一下,看看如何拿到 HashMap 中值的所有权。 https://doc.rust-lang.org/std/collections/struct.HashMap.html
答案
HashMap实现了 into_iter(),因此可以用for语句获取其所有权。
for (k, v) in myhash { //`myhash` moved due to this implicit call to `.into_iter()`
// todo:
// 这里会获得v的所有权,并且消耗掉myhash
}
println!("{:?}", myhash); //value borrowed here after move
答案来自PEtFiSh和Ransang
09|初识Trait:协议约束与能力配置
思考题
如果你学习或者了解过 Java、C++ 等面向对象语言的话,可以聊一聊 trait 的依赖和 OOP 继承的区别在哪里。
答案
trait 的依赖:小明要听从数学老师,语文老师,英语老师的话。老师之间是平等关系,多个依赖平等,最小依赖选择自己喜欢的功能。
OOP 继承:小明要听他爸、他爷爷、他曾祖父的话。继承之间存在父子关系,继承过来一堆破属性和方法,也许根本不是自己想要的,还要负重前行。
答案来自下雨天
10|再探Trait:Trait + 类型 = Rust 的大脑
思考题
请谈谈在函数参数中传入 &dyn TraitA 与 Box 两种类型的区别。
答案
Rust生命周期的独特设计,导致了该语言需要设计一些处理方式应对特殊情况,比如生命周期的标注(主要是给编译器进行代码处理时的提示)。事实上,我们在日常开发中应该避免一些陷入复杂情况的方式:比如,传入参数都用引用(borrow),传出结果都应该是owner。Rust也为我们提供了处理各种情况的工具。所以,一般来说,我们应该在传入参数的时候用 &dyn T,传出结果用 Box<dyn T>。
此外, &dyn TraitA 没有所有权,而 Box<dyn TraitA> 有所有权。 &dyn TraitA 是借用,Box 会转移所有权。
通过下面的程序可以测试出来:
fn doit3(t1: &dyn TraitA, t2: Box) { println!("{:?}", t1); println!("{:?}", t2) } fn main() { let a = AType; let b = BType; doit3(&a, Box::new(b)); println!("{:?}", a); println!("{:?}", b); } 输出: error[E0382]: borrow of moved value: b --> examples/trait_object.rs:29:22 | 26 | let b = BType; | - move occurs because b has type BType, which does not implement the Copy trait 27 | doit3(&a, Box::new(b)); | - value moved here 28 | println!("{:?}", a); 29 | println!("{:?}", b); | ^ value borrowed here after move
答案来自哄哄、鸠摩智和-Hedon 🍭
11|常见 Trait 解析:标准库中的常用 Trait 应该怎么用?
思考题
请举例说明 Deref 与 AsRef 的区别。
答案
在 Rust 中,Deref 和 AsRef 都是与引用相关的 trait,它们可以使某些类型在使用时具有类似于指针的行为,但它们的具体用途有所不同。
Deref trait 通常与智能指针一起使用。当我们编写 Rust 代码时,分配在堆上的值通常不是通过拷贝的方式传递或返回,而是通过使用指向它们的指针(智能指针)来传递或返回。Deref trait 可以强制将智能指针转换成指针,从而可以使用类似于 * 操作符这样的解引用语法访问指针指向的值。例如:
struct MyInt(i32); impl Deref for MyInt { type Target = i32; fn deref(&self) -> &Self::Target { &self.0 } } fn main() { let my_int = MyInt(42); assert_eq!(*my_int, 42); }
在上面的代码中,我们定义了一个 MyInt 结构体,它包含一个 i32 类型的值。我们实现了 Deref trait,并指定了目标类型为 i32。我们在 deref 方法中返回了 self.0,即指向 MyInt 中的 i32 值的引用。这样,我们就可以在 main 函数中使用 *my_int 访问这个 i32 值。
相比之下, AsRef trait 更加通用。它只是将类型的引用转换为其他类型的引用。一种常见的用途是将各种字符串类型统一转换为&str类型。例如:
fn do_something<T: AsRef<str>>(input: T) { let bytes = input.as_ref().as_bytes(); // Do something with the bytes... } fn main() { let my_str = "hello".to_string(); do_something(my_str); }
在上面的代码中,我们定义了一个 do_something 函数,它接受任何实现了 AsRef<str> trait 的值。在函数内部,我们首先使用 as_ref 方法将输入值转换为 &str 类型,然后使用 as_bytes 方法将 &str 类型转换为 &[u8] 类型。这样,我们就可以在函数中使用字节数组操作 bytes 了。在 main 函数中,我们传递了一个所有权字符串,它在函数中,使用 as_ref() 转换成了 &str 类型。
好了,以上就是我们第一章基础篇的思考题与答案,希望你对照着答案看一下自己的思路对不对,如果你有不同的见解,也欢迎你在评论区分享出来,我们一起讨论。我们下节课再见!
答疑课堂(三)|第三章Rust应用篇思考题答案
你好,我是Mike。
你真的很棒!已经学完我们这门30讲正文内容了,最后我们还是和前面两章一样处理一下第三章应用篇的思考题。这部分思考题动手操作的内容比较多,我希望你真的可以自己动手敲敲代码,在我给的示例里做出自己想要的效果。
话不多说,我们开始吧!
21|Web开发(上):如何使用Axum框架进行Web后端开发?
思考题
请你说一说 Request/Response 模型是什么,Axum 框架和其他 gRPC 框架(比如 Tonic)有什么区别?
答案
Request/Response 模型是一种通用的网络模型架构,用于简化跨越网络的数据传输操作。在这种模型中,客户端发送一个请求(Request),服务器端接收并处理该请求,然后返回一个响应(Response)给客户端。这种模型广泛应用于各种网络应用和协议中,如HTTP、FTP等。Request / Response 模型就是一来一回交互。
Axum 框架和其他 gRPC 框架主要是通信模式不一样。Axum提供了一种基于actor模型的通信模式。gRPC模型在Request / Response 模型基础上构造了更多的交互模型支持。

22|Web开发(下):如何实现一个Todo List应用?
思考题
当 Axum Handler 中有多个参数的时候,你可以试着改变一下参数的顺序,看看效果有没有变化。并在这个基础上说一说你对声明式参数概念的理解。
答案
声明式参数,简单来说就是参数的顺序不影响意图表达。因此在Axum中,解包器之间可以任意互换,这让axum的handler不那么在意参数顺序,而在意意图表达。这种设计有助于降低心智负担。
但是也要注意,对于要消耗http request body的解包器,如Json、body等,需要放在最后,原因也很简单,消耗掉了别人就用不了了。
23|Rust与大模型:用 Candle 做一个聊天机器人
思考题
你可以在我的示例上继续捣鼓,添加 GPU 的支持,在 Linux、Windows、macOS 多种平台上测试一下。
答案
GPU用于模型推理加速。目前candle quantized 模型的GPU支持还在todolist之中,已经规划。这也是给candle做贡献的机会。safetensors 格式的模型GPU支持已经可用,可以看candle官方的示例,一般只需要在运行命令行的时候添加 --features cuda 就行,用 --help 查看。
24|Rust图像识别:利用YOLOv8识别对象
思考题
请你开启 cuda 或 metal 特性尝试一下,使用不同的预训练模型看一下效果差异。另外你还可以换用不同的图片来测试一下各种识别效果。
答案
开启 cuda 或 metal 特性只需要在命令行中加参数即可,具体可以 --help 看一下参数。
我们用的M模型做测试,你可以选择S、L、X等模型试试。S速度最快,精度最低,模型体积最小。越往上走,模型速度变慢,精度变高,模型体积变大。实际场合中,特别是摄像头实时监控,往往用S最多,因为需要最快速检测。
25|Rust GUI编程:用Slint为Chatbot实现一个界面
思考题
这节课的示例非常原型化,代码还有很多可以改进的地方,请你思考一下并指出一两处。
答案
- 消息窗口没有处理自动滚动到最下面的逻辑。
- 消息窗口可以像微信那样左右对齐布局,机器人的消息靠左,自己的消息靠右。
26|Rust GUI编程:用Slint为YOLOv8实现一个界面
思考题
这节课的代码实现有一个性能上的问题,就是每次点击 Detect Objects 或 Detect Poses 的时候,实际上都重复加载了模型,你想一想如何优化这个点?
答案
可以把加载模型的逻辑放在界面启动完成后,通过回调函数加载。因为yolo模型还是比较小,因此可以直接写在GUI界面的回调中加载。
当点击识别对象和识别姿势按钮时,直接调用加载后的模型执行推理。这样反应速度能加快不少。
27|Rust Bevy游戏开发:用300行代码做一个贪吃蛇游戏
思考题
这节课的代码还有个问题,就是食物有可能在已经产生过的地方产生,也有可能在蛇身上产生,请问如何处理这个 Bug?
答案
添加一个Resource,跟踪维护食物的Positions,随机产生食物的时候,需要遍历判断是否在已有的食物的Positions和蛇的Positions上。如果有就重新计算随机数,再重复这个过程。
食物的Positions可以用HashSet这种数据结构管理。需要注意的是,当食物被吃掉后,也需要在这个结构中对应的清理。
28|Nom:用Rust写一个Parser解析器
思考题
请尝试用 Nom 解析一个简单版本的 CSV 格式文件。
答案
首先,你需要添加 Nom 依赖:
cargo add nom
然后,你可以使用以下代码来解析 CSV 文件(一个简单示例):
use nom::{ bytes::complete::tag, character::complete::{alphanumeric1 as field, line_ending}, multi::separated_list1, sequence::separated_pair, IResult, }; fn csv_line(input: &str) -> IResult<&str, Vec<&str>> { separated_list1(tag(","), field)(input) } fn csv(input: &str) -> IResult<&str, Vec<Vec<&str>>> { separated_list1(line_ending, csv_line)(input) } fn main() { let input = "field1,field2,field3\nfield1,field2,field3"; let result = csv(input); match result { Ok((_, parsed)) => { for line in parsed { println!("{:?}", line); } } Err(e) => println!("Error: {:?}", e), } }
29|Unsafe编程(上): Unsafe Rust中那些被封印的能力
思考题
Unsafe Rust 比 C 语言更安全吗,为什么?
答案
是的,总体来看Unsafe Rust 比 C 语言更安全。虽然是Unsafe,可以用指针。但是,Unsafe依然属于所有权这样的语法范畴。
来源:十八哥
30|Unsafe编程(下):使用Rust为Python写一个扩展
思考题
- C语言中的char与Rust中的char的区别在哪里?
- C语言的字符串与Rust中的String区别在哪里?
- 如何将C语言的字符串类型映射到Rust的类型中来?
答案
C语言中的char就是一个字节,Rust中的char是4个字节,存的是字符的unicode scalar值。
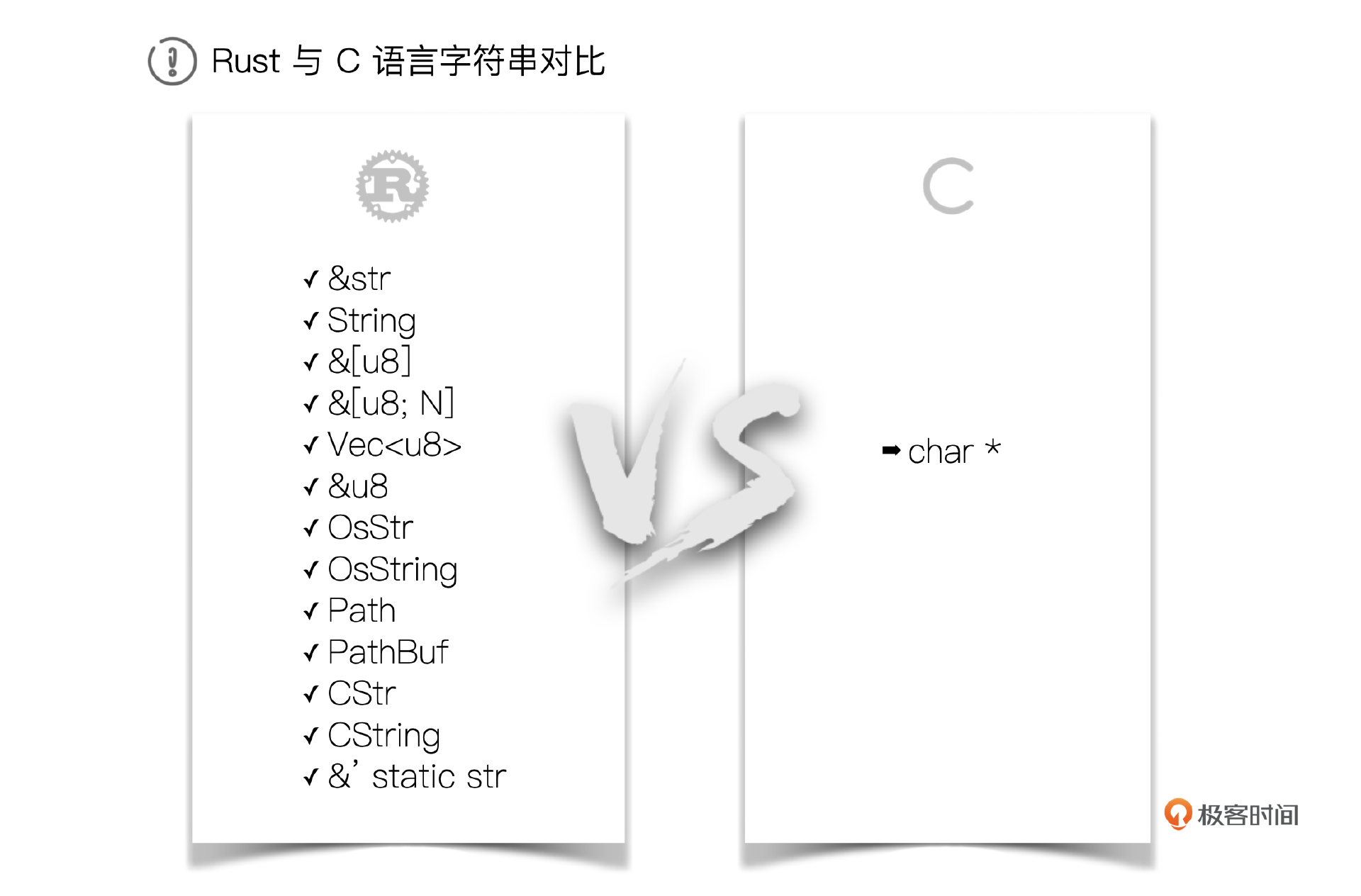
C中的字符串统一叫做 char *,这确实很简洁,相当于是统一的抽象。但是这个统一的抽象也付出了代价,就是丢失了很多额外的信息。Rust把字符串在各种场景下的使用给模型化、抽象化了。相比C语言的char *,多了建模的过程,在这个模型里面多了很多额外的信息。
C语言的字符串与Rust中的String区别主要在于以下几个方面:
- 存储方式:在C语言中,字符串通常以字符数组的形式存储,通过以null字符(‘\0’)作为字符串的结束标记。而在Rust中,String是动态分配的,基于UTF-8编码,并使用指针结构来追踪其起始和结束位置。
- 内存管理:在C语言中,字符串的内存管理需要手动处理,包括分配、释放等。而在Rust中,String的内存管理由Rust的所有权机制自动管理,无需手动释放。
- 安全性:C语言由于其原始的内存管理方式,容易导致内存泄漏、缓冲区溢出等问题。而Rust的类型系统和内存管理机制提供了更强的安全性保障,杜绝了这类问题的发生。
由于这些不同,C语言的字符串类型在Rust中映射为 CStr。
答疑课堂(二)|第二章Rust进阶篇思考题答案
你好,我是Mike。
这节课我们继续来看第二章的课后思考题答案。还是和之前一样,最好是自己学完做完思考题之后再来看答案,效果会更好。话不多说,我们直接开始吧!
进阶篇
12|智能指针:从所有权和引用看智能指针的用法
思考题
你试着打开示例中的这两句,看看报错信息,然后分析一下是为什么?
// arced.play_mutref(); // 不能用
// arced.play_own(); // 不能用
答案
Arc本质上是个引用,所以不允许同时存在可变引用或者移动。play_boxown() 和 play_own() 只能同时打开一个,这两个方法调用都会消耗所有权,导致没法调用另外一个。
答案来自Taozi和Michael
13|异步并发编程:为什么说异步并发编程是 Rust 的独立王国?
思考题
为什么我们要把 async Rust 叫做“独立王国”呢?
答案
因此async Rust代码是在一个Runtime里面执行的,而std Rust的代码不需要这个额外的Runtime,因此说它是独立王国。
另一方面,在 Rust 中,异步编程是使用 async/await 语法,这种语法具有可传染性,与std Rust代码也可以明显区分开,因此它像一个独立王国。
14|Tokio 编程(一):如何编写一个网络命令行程序?
思考题
- EOF 是什么,什么时候会碰到 EOF?
stream.read_to_end()接口能读完网络连接中的数据吗?
答案
EOF是End of file。在Linux万物皆file的情况下,connection也可以是一个file。所以,当Connection关闭的时候,就会产生EOF。
stream.read_to_end() 是持续 read() 直到EOF,因此能够读完网络里的数据,如果使用 stream.read_to_end(&mut buf).await?; 读取的话,会持续wait,直到连接关闭才能进行后续的操作。
答案来自PEtFiSh
15|Tokio 编程(二):如何在 Tokio 多任务间操作同一片数据?
思考题
下面这两句的意义是什么,第一行会阻塞第二句吗?
_ = task_a.await.unwrap();
_ = task_b.await.unwrap();
答案
await代码会持续等待直到任务结束,因此在main thread里第一行会阻塞第二行。但这不会让task_a阻塞task_b。加入await可以使最后的println!打印两个任务执行完以后被修改的db值,如果不加入await。有一定几率最后println!打印的还是原始的db。
答案来自PEtFiSh
16|Tokio 编程(三):如何用 channel 在不同任务间进行通信?
思考题
从任务中搜集返回结果有几种方式?
答案
从任务收集返回结果的方式有:
- 任务直接返回值,然后通过handler取回,比如
a = task_a.await.unwrap();。 - 通过锁的方式直接写在目标位置
- 通过channel的形式传递结果
- 似乎也可以unsafe来写全局变量。
答案来自PEtFiSh
17 | Tokio 编程(四):Rust 异步并发还有哪些需要关注的点?
思考题
你是如何理解 “async Rust 是一个独立王国”这种说法的?
答案
略
18 | 错误处理系统:Rust 中错误是如何被传递并处理的?
思考题
- 请你查阅 Rust std 资料,并说说对 std::error::Error 的理解。
- 请说明 anyhow::Error 与自定义枚举类型用作错误的接收时的区别。
答案
std::error::Error 是 Rust 标准库中的 trait,该 trait 表示可能的错误类型的共同行为,这些错误类型通常都表示了一个失败的操作或无效的输入。实现 Error trait 的类型必须提供一个错误描述和一个可操作性的字符串,通常用于打印错误信息。
anyhow::Error 是一个第三方 Rust 库,它提供了一种用于简化错误处理的方式,该库提供了一个 Error 类型,能够自动收集多个错误信息,并返回一个更易于调试和处理的错误类型。
与自定义枚举类型相比,使用 anyhow::Error 具有以下优点:
-
多态性:anyhow::Error 是一个特殊的错误类型,可以表示任何可能失败的操作,并且可以方便地传递错误信息和上下文,从而使错误处理更加灵活和方便。
-
方便处理:anyhow::Error 提供了一组常用的操作,如错误信息的格式化和日志记录等,这些操作相对繁琐,如果使用自定义枚举类型实现会相对麻烦和复杂。
-
减少代码重复:使用 anyhow::Error 可以排除许多写错误处理代码的繁琐重复的代码,提高代码可读性和可维护性。
而在使用自定义枚举类型来接收错误时,你需要眼睛注意只能返回对应的错误类型,因此可能需要对函数中的一些操作手动作类型转换(map_error)。不像 anyhow::Error 这样可以一股脑直接扔回去。也就是说使用自定义枚举类型来接收错误的心智负担会大一点。
19|Rust 的宏体系:为自己的项目写一个简单的声明宏
思考题
说一说 allow, warn, deny, forbid 几个属性的意义和用法。
答案
在 Rust 中,allow、warn、deny和forbid 是四个控制编译器警告和错误输出的属性。
- allow:允许代码中出现这些警告,编译器不会输出警告信息。
- warn:将警告转换为编译器的错误级别,编译器会在警告信息后面输出错误信息,但不会阻止代码的编译。
- deny:将警告变为编译错误,编译器会在错误信息后面输出警告信息,并且由于错误级别的提高,代码无法编译通过。
- forbid:严格禁止代码中出现这些警告,如果代码中出现了这些警告,就会直接报错并停止编译。
这些属性通常用于优化编译器输出,使输出更加简洁和准确,并降低代码中不良代码的风险。一般情况下,allow 属性用于代码库中的不重要代码部分,warn 用于需要注意但不会造成严重后果的代码部分,deny 用于那些可能会导致问题的代码部分,而 forbid 则用于绝对不能出现问题的代码部分。
例如,在 Rust 中可以这样使用这些属性:
#[allow(dead_code)]
fn unused_function() {
// some unused code
}
#[warn(unused_variables)]
fn unused_variable() {
let _unused_var = "unused variable";
}
#[deny(unused_imports)]
use std::collections::HashMap;
#[forbid(unsafe_code)]
fn safe_function() {
// some safe code that is not allowed to be unsafe
}
在代码中使用 allow、warn、deny 和 forbid 属性可以帮助开发者更加简单高效地控制代码的输出和行为,并帮助代码更好地遵循 Rust 语言特性和最佳实践。
20 | 生命周期:Rust 如何做基本的生命周期符号标注?
思考题
你能说一说生命周期符号 'a 放在 <> 中定义的原因和意义吗?
答案
因为 'a 符号本来就是一种 generic 符号。 <T, 'a> 中的类型参数T用来代表编译期空间上的分析展开, 'a 用来代表编译期时间上的分析展开。所以, 'a 放在 <> 号中是理所当然的。它们的存在都是为了给编译器提供多一些信息。
Web开发(上):如何使用Axum框架进行Web后端开发?
你好,我是Mike, 今天我们来讲一讲如何用Axum框架进行Web服务器后端开发。
关于Rust是否适合做Web后端开发,很多人持怀疑态度。认为Web开发讲究的是敏捷,一种动态的、带运行时的、方便修改的语言可能更适合Web开发。
但有一些因素,其实决定了Rust非常适合Web开发。
- 时代变化:芯片摩尔定律已失效,服务器成本逐渐占据相当大的比例,无脑堆服务器的时代已经过去。当前阶段,对于规模稍微大一些的公司来说,降本增效是一个很重要的任务。而Rust的高性能和稳定可靠的表现非常适合帮助公司节省服务器成本。
- 随着业务的成型,一些核心业务会趋于稳定,模型和流程抽象已经基本不会有大的改动。这时,使用Rust重写或部分重写这些业务,会带来更强的性能和更可靠稳定的服务表现。
- Rust非常适合用来做一些通用的中间件服务,目前开源社区已经出现了一些相当优秀的中间件产品。
- Rust的表达能力其实非常强,其强大的类型系统可帮助开发者轻松地对问题进行建模。一个中等熟练的Rust开发者做原型的速度不会比Python慢多少,在复杂问题场景下,甚至更快。
- Rust的语言层面的设计使它特别适合做重构。重构Rust工程特别快,重构完后,也不用担心出错的问题。相对于动态语言,对应的测试用例都可以少准备很多。
Rust Web Backend 生态
Rust Web后端开发生态目前处于一种欣欣向荣的局面。就Web开发框架来说,能叫得上名字的就有十几种,其中按 crates.io 最新下载量排名,排列靠前的是这几位。
- Axum
- Actix-web
- Rocket
- Poem
- Rouille
- Salvo
从最近下载的绝对数量来说,Axum 的下载量是第二名 Actix-web 的 3 倍多。因此,我们选择了下载量最多的框架——Axum。
Tokio技术栈介绍
Axum有这么强劲的表现,得益于其本身优秀的设计,还有它无缝依赖的 Tokio 技术栈。Tokio从 2017 年发布 0.1 版本开始到现在,已经形成一套强大的技术栈。
这些可靠的工具链,为Rust在服务器端的发展打下了坚实的基础,越来越多的项目开始采用这一套技术栈。
Axum框架
Axum是一个专注于人体工程学和模块化的Web开发框架。——官方文档的Slogan
从上层视角来看,Axum具有以下特性:
- 写Router和Handler的时候,不需要使用宏(非标注风格)。
- 使用解包器进行声明式的请求解析。
- 简单和可预测的错误处理模型。
- 生成响应时只需用到最小的样板代码。
- 充分利用 tower 和 tower-http 的中间件、服务和工具的生态系统。
特别是最后一点,让Axum显著不同于其他框架。Axum自己不带中间件系统,而是使用 tower 系的中间件。这样就能和生态里的其他项目,如 hyper 或 tonic 共享中间件系统。 这种设计太棒了。
Tower中间层服务
Tower是一个模块化、可重用的组件系统,用于构建稳健的网络服务端和客户端应用。它对 请求/响应模型 做了一个统一的服务抽象,和具体的实现协议无关。你可以看一下Service的定义。
async fn(Request) -> Result<Response, Error>
Tower包含 Service 和 Layer 两个抽象。一个Service是一个接受请求,做出响应的异步函数;而一个 Layer 接受一个Service,处理并返回另一个Service。Service和Layer一起,就可以方便地构建中间件服务。而完全基于流(stream)的服务,并不适合使用Tower。
Tower-http介绍
Tower-http 是一个专门用于提供HTTP相关的中间件和设施的库,里面罗列了二十多个中间件。
在Axum中,最常用的中间件是下面这几个。
- TracyLayer 中间件,用于提供高层日志或跟踪。
- CorsLayer 中间件,用于处理CORS。
- CompressionLayer 中间件,用于自动压缩响应。
- RequestIdLayer 和 PropagateRequestIdLayer 中间件,用于设置和传播请求ID。
- TimeoutLayer 中间件,用于设置超时。
- HandleErrorLayer 中间件,用于转换各种错误类型到响应。
而每个中间件都可以用在全局Router、模块Router和Handler三个层次。
Router
Router用来定义URL到handler的映射,并用来构建模块化URL的层级,既能支持全局性路由,也能支持模块层级的路由。比如:
#![allow(unused)] fn main() { let user_routes = Router::new().route("/:id", get(|| async {})); let team_routes = Router::new().route("/", post(|| async {})); let api_routes = Router::new() .nest("/users", user_routes) .nest("/teams", team_routes); let app = Router::new().nest("/api", api_routes); }
Handler
在Axum里,Handler是一个异步函数,这个异步函数接受一个或多个解包器作为参数,返回一个可以转换为响应(impl IntoResponse)的类型。
最简单的 handler 类似下面这个样子:
async fn string_handler() -> String {
"Hello, World!".to_string()
}
使用Axum进行Web后端开发
现在话不多说,让我们开始Axum实战环节吧!
注:目前(2023年12月)Axum的最新版本是 v0.7 版,我们下面会基于这个版本来编写代码。
第一步:Hello world
我们先来看看Axum的Hello World是什么样子。
use axum::{response::Html, routing::get, Router}; #[tokio::main] async fn main() { // build our application with a route let app = Router::new().route("/", get(handler)); // run it let listener = tokio::net::TcpListener::bind("127.0.0.1:3000") .await .unwrap(); println!("listening on {}", listener.local_addr().unwrap()); axum::serve(listener, app).await.unwrap(); } async fn handler() -> Html<&'static str> { Html("<h1>Hello, World!</h1>") }
这里我给出这个步骤的 原始代码地址,你可以直接下载到本地运行。
从这个例子里,我们可以一窥Axum应用的基本结构。首先,一个Axum应用其实就是一个Tokio应用,以标志性的tokio::main属性宏开头。
#[tokio::main] async fn main() {
然后,创建一个Router实例,代表App。在Router中,绑定URL与handler。
然后使用 tokio::net::TcpListener::bind() 监听服务器地址,并将生成的 listener 传入 axum::serve() 中使用,启动axum服务。而这个应用的 handler 参数里没有解包器(extractor),是因为我们暂时不解析请求参数,所以参数部分留空。
async fn handler() -> Html<&'static str> {
Html("<h1>Hello, World!</h1>")
}
然后,这个handler的返回值是 Html<&'static str> 类型,它已经实现了 IntoResponse,所以可以作为 Response 返回类型。下面我们来测试,打开终端在代码目录下执行 cargo run。终端下输出 listening on 127.0.0.1:3000。
打开浏览器,输入 127.0.0.1:3000,可以看到下面这样的页面效果。
第二步:实现静态文件服务
静态文件服务非常有用,用于对服务器上的静态资源如图片、HTML、JS、CSS等文件提供服务。下面我们来看看如何使用Axum实现一个简单的静态文件服务。我们只需要引入ServeDir服务,然后在Router实例上使用 nest_service 挂载这个服务就可以了。
#![allow(unused)] fn main() { Router::new().nest_service("/assets", ServeDir::new("assets")) }
ServeDir::new() 的参数是资源目录的路径,上面一句表示把 /assets/* 的URL映射到 assets 目录下的哪些文件。
而如果需要配置获取默认文件,可以按照下面这样,在ServeDir里配置not_found_service,传一个ServeFile实例进去,这个ServeFile实例就是默认获取的那个文件。然后在Router实例配置时,添加一个 fallback_service 挂载 serve_dir。
#![allow(unused)] fn main() { let serve_dir = ServeDir::new("assets2") .not_found_service(ServeFile::new("assets2/index.html")); let app = Router::new() .route("/foo", get(handler)) .nest_service("/assets", ServeDir::new("assets")) .nest_service("/assets2", serve_dir.clone()) .fallback_service(serve_dir); }
上述示例里,即使我们访问一些不存在的URL地址,服务器也会返回assets2目录下的index.html文件。这通常正是我们想要的。你可以根据 示例源码 自行测试,查看效果。
你可以尝试如下URL地址:
http://127.0.0.1:3000/
http://127.0.0.1:3000/foo
http://127.0.0.1:3000/bar
http://127.0.0.1:3000/assets/index.html
http://127.0.0.1:3000/assets/ferris.png
http://127.0.0.1:3000/assets/script.js
http://127.0.0.1:3000/assets2/index.html
http://127.0.0.1:3000/assets2/ferris2.png
http://127.0.0.1:3000/assets2/script.js
...
第三步:加入日志记录
日志系统是一个服务必不可少的组件,我们一起来看看如何为Axum应用添加日志。在Axum中添加日志很简单。第一步,我们需要添加 tracing 和 tracing-subscriber 两个crates。
#![allow(unused)] fn main() { cargo add tracing cargo add tracing-subscriber }
然后引入TraceLayer。
#![allow(unused)] fn main() { use tower_http::trace::TraceLayer; }
在main函数的开头添加代码:
#![allow(unused)] fn main() { tracing_subscriber::fmt::init(); }
再在Router配置的时候,添加下面这行代码配置日志中间件服务就可以了。
#![allow(unused)] fn main() { let app = Router::new() .route("/foo", get(handler)) .nest_service("/assets", serve_dir.clone()) .fallback_service(serve_dir) .layer(TraceLayer::new_for_http()); // 添加这行 }
使用时,需要按照下面这个方式来使用。
#![allow(unused)] fn main() { tracing::debug!("listening on {}", addr); }
我们用上面一句替代了之前的 println!,在一个正经一点的应用中,我们都不会使用 println! 去打印日志的。
这里需要补充一点知识:Rust中的日志标准。Rust标准的log协议在 链接 里。这个crate中定义了5个级别的日志打印语句。
error!warn!info!debug!trace!
这5个级别从上到下警示程度为由高到低。也就是说,越往下会越详细。
但是这只是一套协议的定义,而不是具体实现。具体使用的时候,需要用另外的crate来实现。我们常用的 env_logger 就是其中一种实现,它把日志输出到标准终端里,用环境变量来控制打印的级别开关。而这里我们使用的 tracing 库也是这样一种实现。它是为tokio异步运行时专门设计的,适合在异步并发代码中使用。
你可以使用RUST_LOG来打开日志开关。比如:
#![allow(unused)] fn main() { RUST_LOG=trace cargo run }
访问 http://127.0.0.1:3000/foo ,可以看到,TRACE级别的和DEBUG级别的日志都打印出来了。
#![allow(unused)] fn main() { 2023-12-11T05:36:39.240674Z TRACE mio::poll: registering event source with poller: token=Token(0), interests=READABLE | WRITABLE 2023-12-11T05:36:39.240718Z DEBUG axumapp03: listening on 127.0.0.1:3000 2023-12-11T05:36:50.029388Z TRACE mio::poll: registering event source with poller: token=Token(1), interests=READABLE | WRITABLE 2023-12-11T05:36:50.029678Z TRACE mio::poll: registering event source with poller: token=Token(2), interests=READABLE | WRITABLE 2023-12-11T05:36:50.030011Z DEBUG request{method=GET uri=/foo version=HTTP/1.1}: tower_http::trace::on_request: started processing request 2023-12-11T05:36:50.030127Z DEBUG request{method=GET uri=/foo version=HTTP/1.1}: tower_http::trace::on_response: finished processing request latency=0 ms status=200 }
用debug模式日志会少一些。
#![allow(unused)] fn main() { RUST_LOG=debug cargo run }
访问 http://127.0.0.1:3000/foo , 输出:
#![allow(unused)] fn main() { 2023-12-11T05:43:45.223551Z DEBUG axumapp03: listening on 127.0.0.1:3000 2023-12-11T05:43:50.558174Z DEBUG request{method=GET uri=/foo version=HTTP/1.1}: tower_http::trace::on_request: started processing request 2023-12-11T05:43:50.558303Z DEBUG request{method=GET uri=/foo version=HTTP/1.1}: tower_http::trace::on_response: finished processing request latency=0 ms status=200 }
我们还可以指定只打印某些crate里的日志。
#![allow(unused)] fn main() { RUST_LOG=tower_http=debug,axumapp03=debug cargo run }
访问 http://127.0.0.1:3000/foo ,输出:
#![allow(unused)] fn main() { 2023-12-11T05:45:03.578294Z DEBUG axumapp03: listening on 127.0.0.1:3000 2023-12-11T05:45:08.036568Z DEBUG request{method=GET uri=/foo version=HTTP/1.1}: tower_http::trace::on_request: started processing request 2023-12-11T05:45:08.036696Z DEBUG request{method=GET uri=/foo version=HTTP/1.1}: tower_http::trace::on_response: finished processing request latency=0 ms status=200 }
你可以下载 源码 自行测试查看效果。
第四步:解析 Get 请求参数
一般一个URL是这样的:
https://rustcc.cn/article?id=8ba98036-e2fb-41cf-9dad-7cd874c397c4
最后面一段是 query,query 的格式为键值对列表,比如 x1=yyy&x2=zzz ,键值对之间使用 & 符号隔开。
Axum采用一种解包器(extractor)的方式,直接从HTTP Request里提取出开发者关心的参数信息。这种设计有一些好处:
- 减少样板重复代码,可以让代码更紧凑易读。
- 类型化,充分利用Rust强大的类型能力。
- 配置式开发,轻松惬意。
下面我们先来看如何从GET请求的URL中,取出Query参数。
在 Axum中,我们只需要在Handler中这样配置解包器就可以。
#[derive(Debug, Deserialize)]
struct InputParams {
foo: i32,
bar: String,
third: Option<i32>,
}
async fn query(Query(params): Query<InputParams>) -> impl IntoResponse {
tracing::debug!("query params {:?}", params);
Html("<h3>Test query</h3>")
}
这里这个 params 参数就是我们想要的query请求参数。可以看到,Axum框架自动帮我们处理了解析工作,让我们直接得到了Rust 结构体对象。减轻了我们处理具体协议的繁琐度,不易出错。请注意示例第8行的参数中使用了模式匹配,你可以回顾一下 第 6 讲 的模式匹配相关知识点。
我们可以继续折腾一下,InputParams里定义了一个third字段,它是 Option<i32> 类型,请你尝试在浏览器URL地址栏或插件中变换请求参数,查看及日志输出返回情况。可能的参数组合有下面这几种。
http://127.0.0.1:3000/query?foo=1&bar=2&third=3
http://127.0.0.1:3000/query?foo=1&bar=2
http://127.0.0.1:3000/query?foo=1
http://127.0.0.1:3000/query?bar=2
http://127.0.0.1:3000/query?foo=1&bar=2&third=3&another=4
本示例完整代码在 这里。
小结
通过这节课的展示,你有没有体会到使用Rust进行Web开发的感觉?其实跟那些动态语言如Python、JavaScript等开发Web没太大区别,Axum的代码也是比较精练的。请你一定要参考我给出的代码示例,对照源代码在你的本地跑起来。Web开发一个非常方便的地方就是方便测试,易于看到渐进的效果正反馈,所以动手是非常重要而且高效的。
相比于动态语言来讲,Rust的强类型更加能够保证Web后端服务的正确性和可靠性。性能自不用说,你选择了Rust,就是选择了高起点。
同时你可以看到,这节课出现的Axum示例代码,一点都不复杂,甚至都没有用到Rust的所谓各种高级特性。其实就是这样,你用Rust做日常开发,特别是业务开发,根本不难,不要被那些所谓的高级特性吓到,先用现成的框架,快速捣鼓出自己的东西,后面再慢慢上难度就好了。
思考题
请你说一说Request/Response 模型是什么,Axum框架和其他gRPC框架(比如Tonic)有什么区别。欢迎你把自己的思考分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
Web开发(下):如何实现一个Todo List应用?
你好,我是Mike,今天我们继续讲如何使用Axum开发Web后端。学完这节课的内容后,你应该能使用Axum独立开发一个简单的Web后端应用了。
第21讲,我们已经讲到了第4步,处理Get query请求,拿到query中的参数。下面我们讲如何处理Post请求并拿到参数。
这节课的代码适用于 Axum v0.7 版本。
基本步骤
第五步:解析 Post 请求参数
当我们想向服务端提交一些数据的时候,一般使用HTTP POST方法。Post的数据会放在HTTP的body中,在HTML页面上,通常会使用表单form收集数据。
和前面的Query差不多,Axum给我们提供了Form解包器,可以方便地取得form表单数据。你可以参考下面的示例。
#[derive(Deserialize, Debug)]
struct Input {
name: String,
email: String,
}
async fn accept_form(Form(input): Form<Input>) -> Html<&'static str> {
tracing::debug!("form params {:?}", input);
Html("<h3>Form posted</h3>")
}
可以看到,相比于前面的Query示例,form示例代码结构完全一致,只是解包器由Query换成了 Form。这体现了Axum具有相当良好的人体工程学,让我们非常省力。
我们这里在结构体上derive了 Deserialize,它是serde库提供的反序列化宏。serde库是Rust生态中用得最广泛的序列化和反序列化框架。
要测试Post请求,你需要安装一个浏览器插件,比如 Postman,它可以让你在浏览器中方便地构建一个Form格式的Post请求。
完整代码示例在 这里,这个示例运行后,访问 http://127.0.0.1:3000/form,会出现一个表单。

在表单中填入数据后,可以观察到日志输出像下面这个样子:
2023-12-11T07:08:33.520071Z DEBUG axumapp05: listening on 127.0.0.1:3000
2023-12-11T07:08:33.720071Z DEBUG request{method=GET uri=/ version=HTTP/1.1}: tower_http::trace::on_request: started processing request
2023-12-11T07:08:33.720274Z DEBUG request{method=GET uri=/ version=HTTP/1.1}: tower_http::trace::on_response: finished processing request latency=0 ms status=200
2023-12-11T07:08:33.833684Z DEBUG request{method=GET uri=/favicon.ico version=HTTP/1.1}: tower_http::trace::on_request: started processing request
2023-12-11T07:08:33.833779Z DEBUG request{method=GET uri=/favicon.ico version=HTTP/1.1}: tower_http::trace::on_response: finished processing request latency=0 ms status=404
2023-12-11T07:09:09.309848Z DEBUG request{method=GET uri=/form version=HTTP/1.1}: tower_http::trace::on_request: started processing request
2023-12-11T07:09:09.309975Z DEBUG request{method=GET uri=/form version=HTTP/1.1}: tower_http::trace::on_response: finished processing request latency=0 ms status=200
2023-12-11T07:09:13.964549Z DEBUG request{method=POST uri=/form version=HTTP/1.1}: tower_http::trace::on_request: started processing request
2023-12-11T07:09:13.964713Z DEBUG request{method=POST uri=/form version=HTTP/1.1}: axumapp05: form params Input { name: "111", email: "2222" }
2023-12-11T07:09:13.964796Z DEBUG request{method=POST uri=/form version=HTTP/1.1}: tower_http::trace::on_response: finished processing request latency=0 ms status=200
我们可以看到,在日志的第9行 form 表单的数据已经解析出来了。
下一步我们研究如何处理传上来的Json格式的请求。
第六步:解析 Json 请求参数
在现代Web开发中,发POST请求更多的时候是提交Json数据,这时HTTP请求的content-type 是 application/json。这种情况Axum应该怎么处理呢?
还是一样的,非常简单。Axum提供了解包器Json,只需要把参数解包器修改一下就可以了,解析后的类型都不用变。你可以看一下修改后的代码。
#[derive(Deserialize, Debug)]
struct Input {
name: String,
email: String,
}
async fn accept_json(Json(input): Json<Input>) -> Html<&'static str> {
tracing::debug!("json params {:?}", input);
Html("<h3>Json posted</h3>")
}
完整代码示例在 这里。这种Post请求在浏览器URL地址栏里面就不太好测试了。最好安装Postman等工具来测试。我用的Postwoman插件操作界面如下:
控制台log输出为:
2023-12-11T07:37:02.093884Z DEBUG axumapp06: listening on 127.0.0.1:3000
2023-12-11T07:37:07.665064Z DEBUG request{method=POST uri=/json version=HTTP/1.1}: tower_http::trace::on_request: started processing request
2023-12-11T07:37:07.665244Z DEBUG request{method=POST uri=/json version=HTTP/1.1}: axumapp06: json params Input { name: "mike", email: "mike@jksj.com" }
2023-12-11T07:37:07.665309Z DEBUG request{method=POST uri=/json version=HTTP/1.1}: tower_http::trace::on_response: finished processing request latency=0 ms status=200
可以看到,我们成功解析出了json参数,并转换成了Rust结构体。
截止目前,我们接触到了三个解包器:Query、Form、Json。Axum还内置很多高级解包器,感兴趣的话你可以点击这个 链接 了解一下。
解析出错了怎么办?
这里我们先暂停一下,回头想想。Axum帮我们自动做了参数的解析,这点固然很好、很方便。但是,如果参数没有解析成功,Axum就会自动返回一些信息,而这些信息我们根本没有接触到,好像也不能控制,这就一点也不灵活了。
Axum的设计者其实考虑到了这个问题,也提供了相应的解决方案——Rejection。只需要在写解包器的时候,把参数类型改成使用 Result 包起来,Result的错误类型为相应的解包器对应的Rejection类型就行了。比如Json解包器就对应JsonRejection,Form解包器就对应FormRejection。
async fn create_user(payload: Result<Json<Value>, JsonRejection>) {
用这种方式,我们能获得解析被驳回的详细错误原因,还可以根据这些原因来具体处理。比如我们可以返回自定义的错误信息模板。
比如:
use axum::{
extract::{Json, rejection::JsonRejection},
routing::post,
Router,
};
use serde_json::Value;
async fn create_user(payload: Result<Json<Value>, JsonRejection>) {
match payload {
Ok(payload) => {
// We got a valid JSON payload
}
Err(JsonRejection::MissingJsonContentType(_)) => {
// Request didn't have `Content-Type: application/json`
// header
}
Err(JsonRejection::JsonDataError(_)) => {
// Couldn't deserialize the body into the target type
}
Err(JsonRejection::JsonSyntaxError(_)) => {
// Syntax error in the body
}
Err(JsonRejection::BytesRejection(_)) => {
// Failed to extract the request body
}
Err(_) => {
// `JsonRejection` is marked `#[non_exhaustive]` so match must
// include a catch-all case.
}
}
}
let app = Router::new().route("/users", post(create_user));
更多详细的Rejection的信息,请参考 这里。
自定义Extractor
当然,面对业务的千变万化,Axum还给了我们自定义解包器的能力。平时用得不多,但必要的时候你不会感觉被限制住。
这方面的内容属于扩展内容,有兴趣的话你可以自己研究一下。请参考 这里。
第七步:Handler返回值
Axum handler的返回类型也很灵活。除了前面例子里提到的 HTML 类型的返回之外,常见的还有 String、Json、Redirect 等类型。实际上,只要实现了 IntoResponse 这个 trait 的类型,都能用作 handler 的返回值。Axum会根据返回值的类型,对Http Response 的status code和header等进行自动配置,减少了开发者对细节的处理。
比如返回一个HTML:
async fn query(Json(params): Json<InputParams>) -> impl IntoResponse {
Html("<h3>Test json</h3>")
}
返回一个String:
async fn query(Json(params): Json<InputParams>) -> impl IntoResponse {
"Hello, world".
}
返回一个Json:
async fn query(Json(params): Json<InputParams>) -> impl IntoResponse {
let ajson = ...;
Json(ajson)
}
从上面代码中可以看到,在Axum里Json既是解包器,又可以用在response里面。
在Rust中,借助serde_json提供的json!宏,你可以像下面这样方便地构造Json对象:
async fn accept_json(Json(input): Json<Input>) -> impl IntoResponse {
tracing::debug!("json params {:?}", input);
Json(json!({
"result": "ok",
"number": 1,
}))
}
你还可以返回一个Redirect,自动重定向页面。
async fn query(Json(params): Json<InputParams>) -> impl IntoResponse {
Redirect::to("/")
}
你甚至可以返回一个 (StatusCode, String)。
async fn query(Json(params): Json<InputParams>) -> impl IntoResponse {
(StatusCode::Ok, "Hello, world!")
}
可以看到,形式变化多端,非常灵活。至于你可以返回哪些形式,可以在 这里 看到。
注意,如果一个handler里需要返回两个或多个不同的类型,那么需要调用 .into_response() 转换一下。这里你可以回顾一下 第14讲 的知识点:impl trait 这种在函数中的写法,本质上仍然是编译期单态化,每次编译都会替换成一个具体的类型。
async fn query(Json(params): Json<InputParams>) -> impl IntoResponse {
if some_flag {
let ajson = ...;
Json(ajson).into_response()
} else {
Redirect::to("/").into_response()
}
}
有没有感觉到一丝丝震撼。Rust虽然是强类型语言,但是感觉Axum把它玩出了弱(动态)类型语言的效果。这固然是Axum的优秀之处,不过主要还是Rust太牛了。
关于返回Json的完整示例,请参考 这里。
测试效果图:
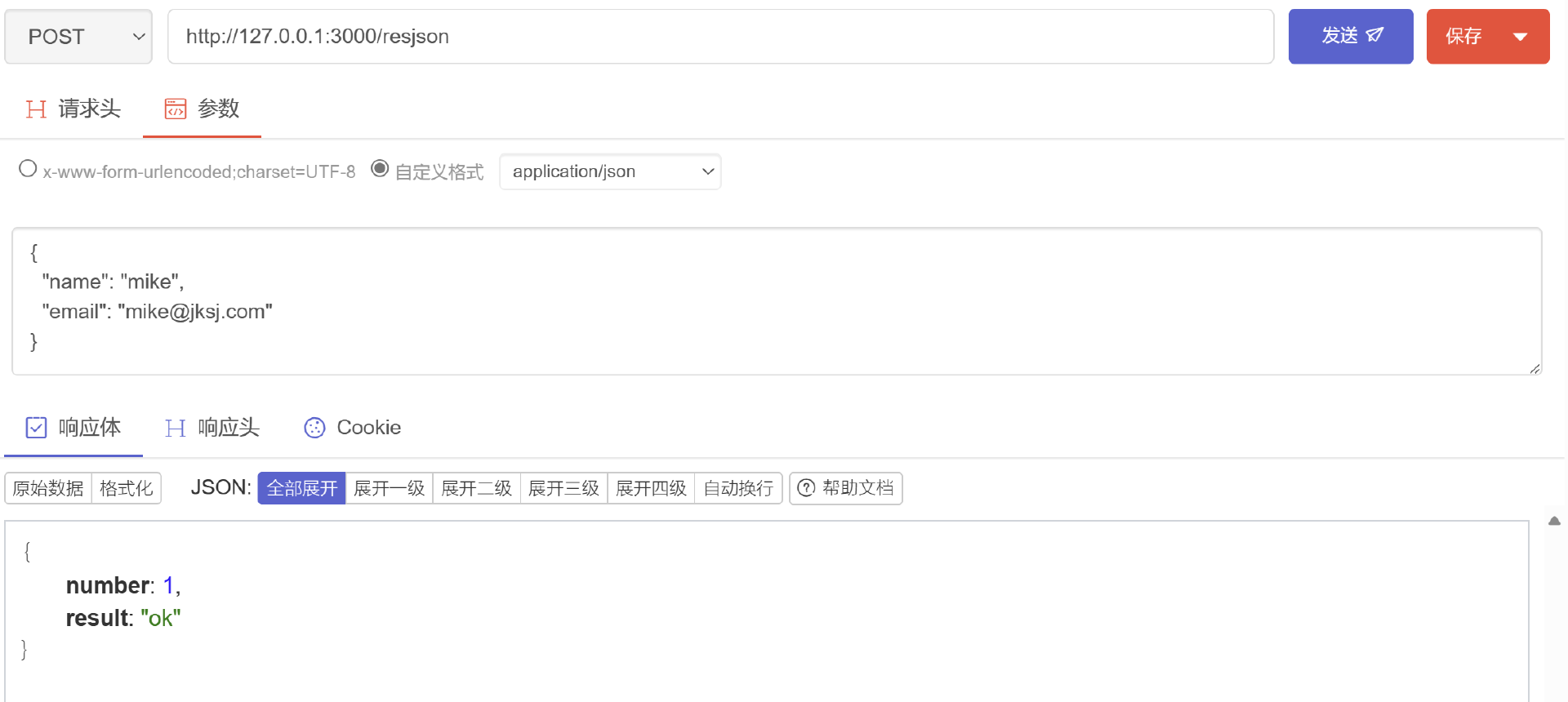
第八步:全局404 Fallback
有时,我们希望给全局的Router添加一个统一的404自定义页面,这在Axum中很简单,只需要一句话,像下面这样:
let app = Router::new()
.route("/", get(handler))
.route("/query", get(query))
.route("/form", get(show_form).post(accept_form))
.route("/json", post(accept_json));
let app = app.fallback(handler_404);
上面第7行就给没有匹配到任何一个url pattern的情况配置了一个 fallback,给了一个 404 handler,你自行在那个handler里面写你的处理逻辑就好了,比如直接返回一个404页面。
完整代码示例在 这里。
第九步:模板渲染
这里的模板渲染指服务端渲染,一般是在服务端渲染HTML页面。在Rust生态中有非常多的模板渲染库。常见的有 Askama、Terra等。这里我们以Askama为例来介绍一下。
Askama是一种Jinja-like语法的模板渲染引擎,支持使用Rust语言在模板中写逻辑。作为模板渲染库,它很有Rust的味道, 通过类型来保证写出的模板是正确的。如果模板中有任何非逻辑错误,在编译的时候就能发现问题。带来的直接效果就是,可以节约开发者大量调试页面模板的时间。凡是使用过的人,都体会到了其中的便利。
先引入 askama。
cargo add askama
使用的时候,也很简单,你可以参考下面的代码示例。
#[derive(Template)]
#[template(path = "hello.html")]
struct HelloTemplate {
name: String,
}
async fn greet(Path(name): Path<String>) -> impl IntoResponse {
HelloTemplate { name } .to_string()
}
模板中使用的是Jinja语法,这是一种很常见的模板语法,如果不了解的可查阅 相关资料。Askama的完整文档,请参考 链接
本小节完整可运行示例,请参考 这里。
运行效果:
第十步:使用连接池连接 PostgreSQL DB
一个真正的互联网应用大部分情况下都会用数据库来存储数据。因此,操作数据库是最常见的需求,而Axum就内置了这方面的支持。下面我们用 Postgres 来举例。
一般来讲,我们会定义一个全局应用状态,把所有需要全局共享的信息放进去。
struct AppState {
// ...
}
全局状态能够被所有handler、中间件layer访问到,是一种非常有效的设计模式。
在下面示例中,我们用 Pool::builder()创建一个连接池对象,并传送到AppState的实例里。
let manager = PostgresConnectionManager::new_from_stringlike(
"host=localhost user=postgres dbname=postgres password=123456",
NoTls,
)
.unwrap();
let pool = Pool::builder().build(manager).await.unwrap();
let app_state = AppState { dbpool: pool};
再使用 router 的 .with_state() 方法就可以把这个全局状态传递到每一个handler和中间件里了。
.with_state(app_state);
另一方面,在 handler 中使用 State 解包器来解出 app_state 。
async fn handler(
State(app_state): State<AppState>,
) {
// use `app_state`...
}
这里,取出来的这个app_state 就是前面创建的AppState的实例,在handler里直接使用就可以了。
当然除了上面的这些知识,你还需要在本地环境安装 PostgreSQL,或使用 Docker Compose 之类的工具快速构建依赖环境。这个步骤的完整可运行的代码在 这里,你可以在安装好PostgreSQL数据库后,设置好数据库的密码等配置,编译此代码连上去测试。
在Ubuntu/Debian下,安装配置PostgreSQL可能用到的指令有下面这几种。
sudo apt install postgresql
sudo su postgres
psql
postgres=# ALTER USER postgres WITH PASSWORD '123456'; # 配置默认用户密码
测试界面:
这个示例输出log类似如下:
2023-12-11T09:20:41.919226Z DEBUG axumapp10: listening on 127.0.0.1:3000
2023-12-11T09:20:50.224031Z DEBUG request{method=GET uri=/query_from_db version=HTTP/1.1}: tower_http::trace::on_request: started processing request
2023-12-11T09:20:50.224099Z DEBUG request{method=GET uri=/query_from_db version=HTTP/1.1}: axumapp10: get db conn Pool(PoolInner(0x557c6994ed80))
2023-12-11T09:20:50.255306Z DEBUG request{method=GET uri=/query_from_db version=HTTP/1.1}: axumapp10: query_from_db: 1
2023-12-11T09:20:50.256060Z DEBUG request{method=GET uri=/query_from_db version=HTTP/1.1}: axumapp10: query_from_db: 2
2023-12-11T09:20:50.256109Z DEBUG request{method=GET uri=/query_from_db version=HTTP/1.1}: axumapp10: query_from_db: 3
2023-12-11T09:20:50.256134Z DEBUG request{method=GET uri=/query_from_db version=HTTP/1.1}: axumapp10: calc_result 2
2023-12-11T09:20:50.256218Z DEBUG request{method=GET uri=/query_from_db version=HTTP/1.1}: tower_http::trace::on_response: finished processing request latency=32 ms status=200
跟我们预期一致,说明成功连上了数据库。
下面,我们通过一个综合示例,把这些工作整合起来,构建一个Todo List应用的后端服务。
综合示例:实现一个 Todo List 应用
TodoList是最常见的Web应用示例,相当于前后端分离型Web应用领域中的Helloworld。一般说来,我们要做一个简单的互联网应用,最基本的步骤有下面几个:
- 设计准备db schema。
- 对应 db schema 生成对应的 Rust model types。
- 规划 Router,加入需要的 http endpoints。
- 规划 handlers。
- 规划前后端数据交互方式,是用 form 格式还是 json 格式前后端交互数据,或者是否统一使用 Graphql 进行query和mutation。
- 代码实现。
- 测试。
下面我们就按照这个流程一步步来实现。
第一步:建立模型
这一步需要你对sql数据库的基本操作有一些了解。这里我们要创建数据库和表。
创建数据库:
create database todolist;
在 psql 中 使用 \c todolist 连上刚创建的todolist数据库,然后创建表。
create table todo (
id varchar not null,
description varchar not null,
completed bool not null);
然后在psql中使用 \d 指令查看已经创建好的table。
todolist=# \d
List of relations
Schema | Name | Type | Owner
--------+------+-------+----------
public | todo | table | postgres
(1 row)
如果你对SQL还不太熟悉,这里有一个简单的教程可供参考: PostgreSQL 教程 | 菜鸟教程 (runoob.com)
第二步:创建对应的Rust Struct
对应上面创建的todo table,我们设计出如下结构体类型:
#[derive(Debug, Serialize, Clone)]
struct Todo {
id: String,
description: String,
completed: bool,
}
第三步:规划Router
Todolist会有增删改查的操作,也就是4个基本的url endpoints。另外,需要将数据库连接的全局状态传到各个handler中。
let app = Router::new()
.route("/todos", get(todos_list))
.route("/todo/new", post(todo_create))
.route("/todo/update", post(todo_update))
.route("/todo/delete/:id", post(todo_delete))
.with_state(pool);
我们在这里添加了4个URL,分别对应query list、create、update、delete 四种操作。
第四步:设计业务对应的handler
一个标准的Todo List的后端服务,只需要对Todo模型做基本的增删改查就可以了。
- create 创建一个Todo item。
- update 更新一个Todo item。
- delete 删除一个Todo item。
- query list,加载一个Todo item list。在这个TodoList应用里,我们不需要对一个具体的item做query。
于是对应的,我们会有4个handlers。我们先把框架写出来。
async fn todo_create(
State(pool): State<ConnectionPool>,
Json(input): Json<CreateTodo>,
) -> Result<(StatusCode, Json<Todo>), (StatusCode, String)> {
async fn todo_update(
State(pool): State<ConnectionPool>,
Json(utodo): Json<UpdateTodo>,
) -> Result<(StatusCode, Json<String>), (StatusCode, String)> {
async fn todo_delete(
Path(id): Path<String>,
State(pool): State<ConnectionPool>,
) -> Result<(StatusCode, Json<String>), (StatusCode, String)> {
async fn todos_list(
pagination: Option<Query<Pagination>>,
State(pool): State<ConnectionPool>,
) -> Result<Json<Vec<Todo>>, (StatusCode, String)> {
上面我们设计好了 4 个handler的函数签名,这就相当于我们写了书的目录,后面要完成哪些东西就能心中有数了。函数签名里有一些信息还需要补充,比如HTTP请求上来后的入参类型。
下面定义了创建新item和更新item的入参DTO(data transform object),用来在Axum里把Http Request的参数信息直接转化成Rust的struct类型。
#[derive(Debug, Deserialize)]
struct CreateTodo {
description: String,
}
#[derive(Debug, Deserialize)]
struct UpdateTodo {
id: String,
description: Option<String>,
completed: Option<bool>,
}
有了这些类型,Axum会自动为我们做转换工作,我们在handler中拿到这些类型的实例,就可以直接写业务了。
第五步:规划前后端的数据交互方式
这一步需要做4件事情。
- query参数放在URL里面,用GET指令提交。
- delete操作的参数放在path里面,用 /todo/delete/:id 这种形式表达。
- create和update参数是放在body里面,用POST指令提交,用json格式上传。
- 从服务端返回给前端的数据都是以json格式返回。
这一步定义好了,就可以重新审视一下4个handler的函数签名,看是否符合我们的要求。
第六步:代码实现
前面那些步骤设计规划好后,实现代码就是一件非常轻松的事情了。基本上就是按照Axum的要求,写出相应的部分就行了。
你可以看一下完整可运行的 示例。在示例里,我们使用了bb8这个数据库连接池来连接pg数据库。这样我们就不需要去担心连接断开、重连这些底层的琐事了。
第七步:测试
一般,测试后端服务有几种方式:
- 框架的单元和集成测试方法,不同的框架有不同的实现和使用方式,Axum里也有配套的设施。
- Curl 命令行脚本测试。
- Web浏览器插件工具测试。
三种方式并不冲突,是相互补充的。第3种方式常见的有Postman这种浏览器插件,它们可以很方便地帮我们对Web应用进行测试。
测试创建一个Item:
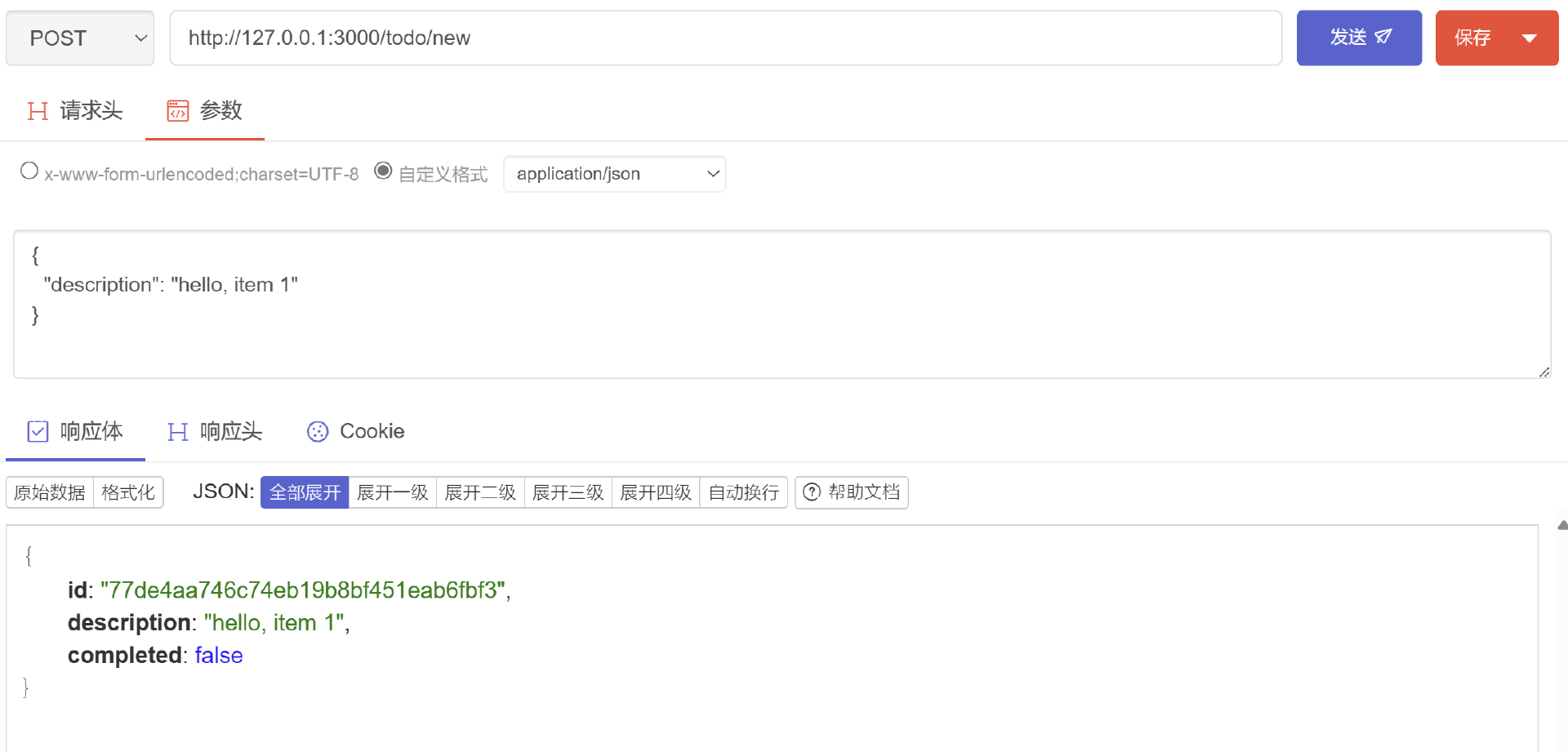
我们也可以多创建几个。
以下是创建了5个item的list返回,通过Get 方法访问 http://127.0.0.1:3000/todos。
[
{
"id": "77de4aa746c74eb19b8bf451eab6fbf3",
"description": "hello, item 1",
"completed": false
},
{
"id": "3c158df02c724695ac67d4cbff180717",
"description": "hello, item 2",
"completed": false
},
{
"id": "0c687f7b4d4442dc9c3381cc4d0e4a1d",
"description": "hello, item 3",
"completed": false
},
{
"id": "df0bb07aa0f84696896ad86d8f13a61c",
"description": "hello, item 4",
"completed": false
},
{
"id": "3ec8f48f5fd34cf9afa299427066ef35",
"description": "hello, item 5",
"completed": false
}
]
其他的更新和删除操作,你可以自己动手测试一下。
你阅读代码时,有3个地方需要注意:
- 注意参数传入中的可省参数 Option 的处理。
- handler的返回值用的Result,请注意业务处理过程中的错误转换。
- pg db 的操作,因为我们没有使用ORM这种东西,因此纯靠手动拼sql字符串,并且手动转换从pg db返回的row值的类型。这比较原始,也比较容易出错。但是对于我们学习来讲,是有好处的。后面你做Web应用的时候,可以选择一个ORM,Rust生态中比较出名的有 sqlx、SeaORM、Rbatis 等。
小结
这节课我们学会了如何使用Axum进行Web后端开发。Web开发本身是一个庞大的领域,要精通需要花费大量的时间。我通过两节课的时间,抽出了里面的思路和重要步骤,快速带你体验了如何实现一个todolist app。
这节课我们贯彻了循序渐进的学习方式。先对大目标进行分解,了解要完成一个目标之前,需要掌握多少基础的知识点。然后,就一点一点去掌握好,理解透。这样一步一步把积木搭上来,实际也花不了多少时间。这实际是一种似慢实快的方法。在Rust中,这种方法比那种先总体瞟一眼教程,直接动手做开发,不清楚的地方再去查阅相关资料的方式,效果要好一些,并且会扎实很多。
Axum是一个相当强大灵活的框架,里面还有很多东西(比如:如何写一个中间件,自定义extractor,如何处理流文件上传等)值得你去探索。好在,我们已经掌握了Axum的基本使用方法了,Web开发的特点让我们可以小步快跑,一点一点加功能,能立即看到效果。只要肯花时间,这些都不是问题。
思考题
当Axum Handler中有多个参数的时候,你可以试着改变一下参数的顺序,看看效果有没有变化。并在这个基础上说一说你对 声明式参数 概念的理解。
请你展开聊一聊,欢迎你留言和我分享、讨论,也欢迎你把这节课的内容分享给其他朋友,邀他一起学习,我们下节课再见!
Rust与大模型:用 Candle 做一个聊天机器人
你好,我是Mike。今天我们来聊一聊如何用Rust做一个基于大语言模型的聊天机器人。
大语言模型(LLM)是2023年最火的领域,没有之一。这波热潮是由OpenAI的ChatGPT在今年上半年发布后引起的,之后全世界的研究机构和科技公司都卷入了大模型的竞争中。目前业界应用大模型训练及推理的主要语言是Python和C/C++。Python一般用来实现上层框架,而C/C++一般起底层高性能执行的作用,比如著名的框架 PyTorch,它的上层业务层面是用Python写的,下层执行层面由C执行,因为GPU加速的部分只能由C/C++来调用。
看起来大语言模型好像和Rust没什么关系,必须承认,由于历史积累的原因,在AI这一块儿Rust的影响力还非常小。但从另一方面来讲呢,Rust是目前业界除Python、C++ 外,唯一有潜力在未来20年的AI 发展中发挥重要作用的语言了。为什么这么说呢?
首先Rust的性能与C/C++一致,并且在调用GPU能力方面也同样方便;其次,Rust强大的表达能力,不输于Python,这让人们使用Rust做业务并不难;然后,Rust的cargo编译成单文件的能力,以及对WebAssembly完善的支持,部署应用的时候非常方便,这比Py + C/C++组合需要安装的一堆依赖和数G的库方便太多。
目前Rust生态中其实已经有很多AI相关的基础设施了,你可以从我给出的 链接 里找到。
世界上最大的机器学习模型仓库平台 HuggingFace(机器学习领域的Github) 推出了 Rust 机器学习框架 Candle。在这个官方代码仓库上,HuggingFace上解释了为什么要做一个Rust的机器学习框架。
- Candle上云端的 Serverless 推理可行。PyTorch那一套体积太大,安装完得几个G,而Candle编译后的可执行文件才十几M到几十M。
- Candle可以让你避免Python的 GIL,从而提高性能。
- HuggingFace已经用Rust写了不少基础工具了,比如 safetensors 和 tokenizers。
Elon Musk的 x.ai 发布后,页面上也有一段对Rust的溢美之词:Rust被证明是一个理想的选择,用于构建可扩展的、可靠的、可维护性的基础设施。它提供了高性能、丰富的生态系统,它能阻止大部分错误,这些错误在分布式系统中经常会碰到。由于我们的团队规模很小,基础设施的可靠性就显得至关重要,否则维护工作会浪费大量创新的时间。Rust给我们提供了信心,任何的代码修改或重构都可以产出可工作的程序,并且在最小监管下可以持续运行好几个月(而不会出问题)。
Musk甚至说Rust语言是未来 构建 AGI 的语言。
在使用Rust尝试做聊天机器人之前,我们先来了解一下相关的背景知识。
大语言模型背景知识
这节课我们还是主要讲Rust及Rust的应用,所以相关的背景知识我们就简单概括一下。
机器学习(Machine Learning,ML)泛指用计算机对数据集按照一定的算法进行数据处理、分析、聚类、回归等。在执行前,人往往不知道结果是什么,所以叫机器学习。机器学习可以用于自动提取信息,自动或辅助人类做决策。
而神经网络(Neural Network)是机器学习的一类算法,它是模拟人的大脑神经元和连接的一种算法。目前整个业界投入资源最多的就是在这类算法上面,在这个类别中的创新也是最多的,有种观点认为神经网络算法是通向真正的AI最可能正确的路径。
而深度学习(Deep Learning),其实就是层次很多很深的神经网络。你可以想象,层次越深,节点数(图里那些圈)越多,就越能模拟大脑。但是深度学习带来的问题就是,层次越深,节点数越多,则那些线(就是权重值)就会越多,呈指数级增长,那么计算量就会越来越大。其实之前十几、二十年AI进展不大,主要就是因为这个计算能力限制了。
通过无数人的探索,我们发现可以把深度学习的计算并行化,优化了很多工程上的算法。这样就能够在大家熟悉的主要用来玩游戏的GPU显卡上运行,大大提高了计算速度。这个视角,二十多年前Nvidia的老黄就看明白了,早早地提供好了基础设施,CUDA、CUDNN等。所以现在你就看到了,一卡难求,已经严重影响到了游戏玩家的生存。
ChatGPT与LLaMA
那么ChatGPT是什么呢?英文是Chat Generative Pre-trained Transformer,是OpenAI提供的在线AI对话服务,具有令人惊叹的理解能力和回答能力。你可以把ChatGPT理解成一个为对话调优的预训练转换模型。GPT 3 有 1750 亿参数,有传言GPT 4 有 1.76万亿参数。参数是什么,就是图中节点之间的连线,你可以想象一下1750亿根线的场景。
OpenAI搞出了ChatGPT,让全世界惊掉了下巴,但是它是闭源的。于是Meta公司(前Facebook)的Yann LeCun(图灵奖得主)团队,搞了一个开源版本的GPT,叫 LLaMA。它也是在巨量的源数据集上进行的训练,生成了 70亿(7B),130亿(13B),650亿(65B)三个版本参数的大模型文件,可以供业界做学习和研究使用。现在已推出LLaMA 2,正在做LLaMA 3。
LLaMA搞出来后,掀起了LLM界的狂欢。全世界的团队在LLaMA的基础上,继续调优,推出了各种各样的大模型。比如国内清华的 ChatGLM, 零一万物的 Yi。国外的 Mistral、OpenChat、Starling 等。这块儿非常卷,大家都在争相推出自己调优后的版本,每天早上睡醒起来,都发现又推出了几个新的LLM。
这些训练好后的文件一般从几个G到几十G不等,也有几百G的。要运行它们,得有非常强大的机器才行。比如7B 的 LLaMA 2 文件,每个权重为一个 f16 浮点数,占两个字节,所以可以估算出要运行 LLaMA 2 模型,起码得有 14G 的内存或显存。内存还好,显存超过14G的个人用户真不多。并且,LLaMA2的模型文件是PyTorch导出的,只能由PyTorch框架来运行。
llama.cpp与量子化方法
车到山前必有路,大神 Georgi Gerganov 搞了一个项目: llama.cpp。它是一个用C/C++重新实现引擎的版本,不需要安装PyTorch,就可以运行LLaMA 2模型文件。最关键的是,它提出了一种量子化(quantization)方法,可以将权重从 16 位量子化到8位、6位、5位、4位,甚至2位。这样,就相当于等比缩小了占用内存的规模。比如,一个4位量子化版本的LLaMA 2 7B模型,就只需要不到4G的内存/显存就能运行。这样,就能适配大多数的个人计算机了。
这种量子化方法是个重大创新,它直接促进了LLM生态的进一步繁荣。现在HuggingFace上有大量量子化后的模型,比如 openchat_3.5.Q4_K_M.gguf 就是一个OpenChat的4位量子化的版本。我们下载的时候,直接下载这些量子化后的模型文件就可以了。
请注意,这些文件是训练后的成品,我们下载它是用来做推理(infer)的,而不是训练(train)的。当然,我们可以在这些成品模型上运行调优(fine tune)。
大模型文件格式
目前HuggingFace上有几种常见的LLM文件格式。
- bin格式:Pytorch导出的模型文件格式
- safetensors格式:HuggingFace定义的一种新的模型文件格式,有可能成为未来的主流格式。HuggingFace用Rust实现safetensors格式的解析,并导出为Py接口,请参见 链接。
- ggml格式:llama.cpp 项目量子化模型的前期模型格式。
- gguf格式:llama.cpp项目量子化模型的后期模型格式,也是现在主流的量子化LLM格式。
Rust的机器学习框架
Rust生态现在有几个比较不错的ML框架,最好的两个是: Candle 和 burn。后续,我们以Candle为例来介绍。
Candle介绍
据Candle官网介绍,它是一个极小主义机器学习框架,也就是没什么依赖,不像Pytorch那样装一堆东西,部署起来很麻烦。但其实它也能用来训练。
它有下面这些特性:
- HuggingFace出品。近水楼台先得月,Candle几乎能支持HuggingFace上所有的模型(有的需要经过转换)。
- 语法简单,跟PyTorch差不多。
- CPU、Cuda、Metal的支持。
- 让serverless和快速部署成为可能。
- 模型训练。
- 分布式计算(通过NCCL)。
- 开箱即用的模型支持,LLaMA、Whisper、 Falcon 等等。
Candle不仅仅是大模型深度学习框架,它还是一个机器学习框架,因此它也支持其他的机器学习算法和强化学习(reinforcement learning)。下面我们就来看看如何利用Candle框架做一个聊天机器人。
注:这节课的代码适用于 candle_core v0.3 版本。
使用Candle做一个聊天机器人
下载模型文件
我对一些大模型进行了测试,发现OpenChat的对话效果比较好,所以下面我们用OpenChat LLM来进行展示。我们会用 quantized 8bit 的版本。其实 4bit 的版本也是可以的,效果也非常好。
Candle 官方的示例比较复杂,我为这个课程定制了一个更简单的独立运行的 示例。你可以将这个仓库克隆下来,进入目录。在运行代码之前,下载模型文件和tokenizer.json文件。
与代码目录同级的位置,创建一个目录
mkdir hf_hub
进入这个目录,请下载
https://huggingface.co/TheBloke/openchat_3.5-GGUF/blob/main/openchat_3.5.Q8_0.gguf
和
https://huggingface.co/openchat/openchat_3.5/blob/main/tokenizer.json
将这个 tokenizer.json 重命名为 openchat_3.5_tokenizer.json
目录结构:
23-candle_chat/
Cargo.toml
src/
hf_hub/
openchat_3.5_tokenizer.json
openchat_3.5.Q8_0.gguf
运行演示
然后,进入 23-candle_chat/ 运行:
cargo run --release --bin simple
出现如下界面,就可以聊天了。

下面是我问的一个问题,bot的回答好像有点问题,这个模型用英文问的效果会好一些。

代码讲解
你可以看一下代码。
#![allow(unused)] use std::fs::File; use std::io::Write; use std::path::PathBuf; use tokenizers::Tokenizer; use candle_core::quantized::gguf_file; use candle_core::utils; use candle_core::{Device, Tensor}; use candle_transformers::generation::LogitsProcessor; use candle_transformers::models::quantized_llama as quantized_model; use anyhow::Result; mod token_output_stream; use token_output_stream::TokenOutputStream; struct Args { tokenizer: String, model: String, sample_len: usize, temperature: f64, seed: u64, repeat_penalty: f32, repeat_last_n: usize, gqa: usize, } impl Args { fn tokenizer(&self) -> Result<Tokenizer> { let tokenizer_path = PathBuf::from(&self.tokenizer); Tokenizer::from_file(tokenizer_path).map_err(anyhow::Error::msg) } fn model(&self) -> Result<PathBuf> { Ok(std::path::PathBuf::from(&self.model)) } } fn main() -> anyhow::Result<()> { println!( "avx: {}, neon: {}, simd128: {}, f16c: {}", utils::with_avx(), utils::with_neon(), utils::with_simd128(), utils::with_f16c() ); let args = Args { tokenizer: String::from("../hf_hub/openchat_3.5_tokenizer.json"), model: String::from("../hf_hub/openchat_3.5.Q8_0.gguf"), sample_len: 1000, temperature: 0.8, seed: 299792458, repeat_penalty: 1.1, repeat_last_n: 64, gqa: 8, }; // load model let model_path = args.model()?; let mut file = File::open(&model_path)?; let start = std::time::Instant::now(); // This is the model instance let model = gguf_file::Content::read(&mut file)?; let mut total_size_in_bytes = 0; for (_, tensor) in model.tensor_infos.iter() { let elem_count = tensor.shape.elem_count(); total_size_in_bytes += elem_count * tensor.ggml_dtype.type_size() / tensor.ggml_dtype.blck_size(); } println!( "loaded {:?} tensors ({}bytes) in {:.2}s", model.tensor_infos.len(), total_size_in_bytes, start.elapsed().as_secs_f32(), ); let mut model = quantized_model::ModelWeights::from_gguf(model, &mut file)?; println!("model built"); // load tokenizer let tokenizer = args.tokenizer()?; let mut tos = TokenOutputStream::new(tokenizer); // left for future improvement: interactive for prompt_index in 0.. { print!("> "); std::io::stdout().flush()?; let mut prompt = String::new(); std::io::stdin().read_line(&mut prompt)?; if prompt.ends_with('\n') { prompt.pop(); if prompt.ends_with('\r') { prompt.pop(); } } let prompt_str = format!("User: {prompt} <|end_of_turn|> Assistant: "); print!("bot: "); let tokens = tos .tokenizer() .encode(prompt_str, true) .map_err(anyhow::Error::msg)?; let prompt_tokens = tokens.get_ids(); let mut all_tokens = vec![]; let mut logits_processor = LogitsProcessor::new(args.seed, Some(args.temperature), None); let start_prompt_processing = std::time::Instant::now(); let mut next_token = { let input = Tensor::new(prompt_tokens, &Device::Cpu)?.unsqueeze(0)?; let logits = model.forward(&input, 0)?; let logits = logits.squeeze(0)?; logits_processor.sample(&logits)? }; let prompt_dt = start_prompt_processing.elapsed(); all_tokens.push(next_token); if let Some(t) = tos.next_token(next_token)? { print!("{t}"); std::io::stdout().flush()?; } let eos_token = "<|end_of_turn|>"; let eos_token = *tos.tokenizer().get_vocab(true).get(eos_token).unwrap(); let start_post_prompt = std::time::Instant::now(); let to_sample = args.sample_len.saturating_sub(1); let mut sampled = 0; for index in 0..to_sample { let input = Tensor::new(&[next_token], &Device::Cpu)?.unsqueeze(0)?; let logits = model.forward(&input, prompt_tokens.len() + index)?; let logits = logits.squeeze(0)?; let logits = if args.repeat_penalty == 1. { logits } else { let start_at = all_tokens.len().saturating_sub(args.repeat_last_n); candle_transformers::utils::apply_repeat_penalty( &logits, args.repeat_penalty, &all_tokens[start_at..], )? }; next_token = logits_processor.sample(&logits)?; all_tokens.push(next_token); if let Some(t) = tos.next_token(next_token)? { print!("{t}"); std::io::stdout().flush()?; } sampled += 1; if next_token == eos_token { break; }; } if let Some(rest) = tos.decode_rest().map_err(candle_core::Error::msg)? { print!("{rest}"); } std::io::stdout().flush()?; let dt = start_post_prompt.elapsed(); println!( "\n\n{:4} prompt tokens processed: {:.2} token/s", prompt_tokens.len(), prompt_tokens.len() as f64 / prompt_dt.as_secs_f64(), ); println!( "{sampled:4} tokens generated: {:.2} token/s", sampled as f64 / dt.as_secs_f64(), ); } Ok(()) }
我们分段讲解这100多行代码。
第19行,定义了Args参数,这是模型必要的参数配置定义。第42~48行,看看有哪些CPU特性支持。第50~59行,实例化Args,这些参数都是硬编码进去的,除了两个文件的路径外,需要LLM相关知识才能理解。
第62~81行,加载大模型文件,并生成模型对象。我们这个模型是GGUF格式的,因此需要用gguf_file模块来读。Tensor是LLM中的重要概念,它是一个多维数组,可以在CPU和GPU上计算,在GPU上还可以并行计算。一个大模型由很多的Tensor组成。我们这个模型中,加载进来了 291 个 Tensor。
第84行,加载tokenizer.json文件,并生成 tokenizer 实例。tokenizer 用于将输入和输出的文本转化为Tensor,变成大模型可理解的数据。第85行创建token输出流实例。第89~99行,建立问答界面,输入提示符为一个 > 号,输出为 bot: 开头。第101~104行将输入的问答转化为 tokens。这个tokens就是Tensor实例。
第106~122行,是用于处理输入,大模型对输入的token做一处理,你可以理解成大模型对你的输入问题先要进行一下理解,然后后面才能做出对应的回答。
LogitsProcessor 是一个用于修改模型输出概率分布的工具。我们可以看到,这个过程中使用的设备写死了,用的CPU。
第124行, "<|end_of_turn|>" 是 OpenChat 模式定义的一轮对话结束的标志。第125~156行,就是对问题的回答。用的设备仍然为CPU,我们可以猜测应该会很慢。它这里面还有对penalty机制的处理。细节也需要去查阅大模型NLP相关的知识。
第158~167行,是对本次处理性能的一个汇总。在我的电脑上,纯用CPU计算的话,只能达到1秒一个多token的速度,非常卡。有GPU加持的话,会快很多。
你可能发现了,第87行有个循环,它是用来实现 interactive 交互效果的,问完一句,回答完,还可以问下一句。
添加命令行参数
前面的simple示例,我们所有的参数都是写死在代码里面的。这样方便理解,但不方便使用。我们可以尝试为它添加命令行参数功能。
在Rust中,写一个命令行非常简单,直接用clap,改几行代码就可以了。将上面示例中的Args结构体的定义变成下面这样就可以了,然后在调用的时候使用 Args::parse() 生成 Args 实例。
#[derive(Parser, Debug)] #[command(author, version, about, long_about = None)] struct Args { #[arg(long, default_value = "../hf_hub/openchat_3.5_tokenizer.json")] tokenizer: String, #[arg(long, default_value = "../hf_hub/openchat_3.5.Q8_0.gguf")] model: String, #[arg(short = 'n', long, default_value_t = 1000)] sample_len: usize, #[arg(long, default_value_t = 0.8)] temperature: f64, #[arg(long, default_value_t = 299792458)] seed: u64, #[arg(long, default_value_t = 1.1)] repeat_penalty: f32, #[arg(long, default_value_t = 64)] repeat_last_n: usize, #[arg(long, default_value_t = 8)] gqa: usize, } fn main() { // ... let args = Args::parse(); // ... }
经过升级的命令有了下面这些参数:
$ cargo run --release --bin cli -- --help
Finished release [optimized] target(s) in 0.04s
Running `target/release/cli --help`
avx: false, neon: false, simd128: false, f16c: false
Usage: cli [OPTIONS]
Options:
--tokenizer <TOKENIZER> [default: ../hf_hub/openchat_3.5_tokenizer.json]
--model <MODEL> [default: ../hf_hub/openchat_3.5.Q8_0.gguf]
-n, --sample-len <SAMPLE_LEN> [default: 1000]
--temperature <TEMPERATURE> [default: 0.8]
--seed <SEED> [default: 299792458]
--repeat-penalty <REPEAT_PENALTY> [default: 1.1]
--repeat-last-n <REPEAT_LAST_N> [default: 64]
--gqa <GQA> [default: 8]
-h, --help Print help
-V, --version Print version
是不是很方便?谁说Rust生产力不行的!
点击 这里 可以找到源文件,你可以本地试试跑起一个大模型对话机器人。另外,Candle官方仓库中的 示例 功能更强大,但也更复杂,你可以继续深入研究。
小结
这节课我们一起探索了使用Rust利用Candle机器学习框架开发一个大模型聊天机器人的应用。Rust目前在AI界虽然还不够有影响力,但是未来是相当有潜力的,这也是为什么HuggingFace带头出一个Rust机器学习框架的原因。
不过这节课我们只是讲了怎么用起来,而如果要深入下去的话,机器学习、深度学习的基础知识就必不可少了。如果你有时间精力的话,你可以深入下去好好补充一下这方面的学术知识,毕竟未来几十年,AI是一个主要问题,也会是一个主要机会。目前AI发展速度太快了,有种学习跟不上业界发展速度的感觉。但是不管怎样,学好基础,永远不会过时。
另外,Rust AI这块儿,虽然已经小有起色,但是作为生态来讲,空白处还很多。所以这也正是学好Rust的机会,Rust可以在AI基建这块做大量的工作,这些工作可以服务于Rust社区,也可以服务于Python乃至整个AI社区。
思考题
你可以在我的示例上继续捣鼓,添加GPU的支持,在Linux、Windows、macOS多种平台上测试一下。欢迎你在评论区贴出你自己的代码,也欢迎你把这节课分享给其他朋友,我们下节课再见!
Rust 图像识别:利用 YOLOv8 识别对象
你好,我是 Mike。这节课我们来学习如何使用 Rust 对图片中的对象进行识别。
图像识别是计算机视觉领域中的重要课题,而计算机视觉又是 AI 的重要组成部分,相当于 AI 的眼睛。目前图像识别领域使用最广泛的框架是 YOLO,现在已经迭代到了 v8 版本。而基于 Rust 机器学习框架 Candle,可以方便地实现 YOLOv8 算法。因此,这节课我们继续使用 Candle 框架来实现图片的识别。
Candle 框架有一个示例,演示了 YOLOv8 的一个简化实现。我在此基础上,将这个源码中的示例独立出来,做成了一个单独的项目,方便你学习(查看 代码地址)。
注:这节课的代码适用于 candle_core v0.3 版本。
YOLO 简介
YOLO(You Only Look Once)是一种目标检测算法,它可以在一次前向传递中检测出图像中的所有物体的位置和类别。因为只需要看一次,YOLO 被称为 Region-free 方法,相比于 Region-based 方法,YOLO 不需要提前找到可能存在目标的区域(Region)。YOLO 在 2016 年被提出,发表在计算机视觉顶会 CVPR(Computer Vision and Pattern Recognition)上。YOLO 对整个图片进行预测,并且它会一次性输出所有检测到的目标信息,包括类别和位置。
YOLO 也使用神经网络进行图像识别,一般来说,如果是推理的话,我们需要一个神经网络的预训练模型文件。下面你会看到,在运行示例的时候,会自动从 HuggingFace 下载对应的预训练模型。
YOLOv8 的模型结构比起之前的版本,会复杂一些,我们来看一下官方整理的图片。
这节课我们主要是去使用,不展开关于这个模型的讲解。目前官方的预训练模型分成 5 个。
- N:nano。模型最小。探测速度最快,精度最低。
- S:small,模型比 nano 大。
- M:middle,模型比 small 大。
- L:large,模型比 middle 大,比 x 小。
- X:extra large,模型最大。探测速度最慢,精度最高。
在下面的示例中,我们可以通过参数来指定选择哪个模型。
YOLOv8 的能力
YOLO 发展到第 8 代已经很强大了。它可以对图像做分类、探测、分段、轨迹、姿势等。

了解了 YOLO 的能力,下面我们开始实际用起来。
动手实验
下载源码:
git clone https://github.com/miketang84/jikeshijian
cd jikeshijian/24-candle_yolov8
物体探测
假设我们有这样一张图片。

编译运行下面这行代码。
cargo run --release -- assets/football.jpg --which m
请注意,这个运行过程中,会联网从 HuggingFace 上下载模型文件,需要科学上网环境。
运行输出:
$ cargo run --release -- assets/football.jpg --which m
ProxyChains-3.1 (http://proxychains.sf.net)
Finished release [optimized] target(s) in 0.08s
Running `target/release/candle_demo_yolov8 assets/football.jpg --which m`
Running on CPU, to run on GPU, build this example with `--features cuda`
model loaded
processing assets/football.jpg
generated predictions Tensor[dims 84, 5460; f32]
person: Bbox { xmin: 0.15629578, ymin: 81.735344, xmax: 99.46689, ymax: 281.7202, confidence: 0.94353473, data: [] }
person: Bbox { xmin: 433.88196, ymin: 92.59643, xmax: 520.25476, ymax: 248.76715, confidence: 0.933658, data: [] }
person: Bbox { xmin: 569.20465, ymin: 34.737877, xmax: 639.8049, ymax: 269.4999, confidence: 0.927611, data: [] }
person: Bbox { xmin: 209.33649, ymin: 16.313568, xmax: 388.09424, ymax: 388.7763, confidence: 0.92696583, data: [] }
person: Bbox { xmin: 169.212, ymin: 15.2717285, xmax: 312.59946, ymax: 345.16046, confidence: 0.900463, data: [] }
person: Bbox { xmin: 626.709, ymin: 65.91608, xmax: 639.791, ymax: 86.72856, confidence: 0.33487964, data: [] }
sports ball: Bbox { xmin: 417.45734, ymin: 315.16333, xmax: 484.62384, ymax: 372.86432, confidence: 0.93880117, data: [] }
writing "assets/football.pp.jpg"
在 assets 目录下生成 football.pp.jpg 文件,打开后效果如下:

可以看到,Yolo 正确识别了 6 个人,和一个运动球。
姿势探测
我们来看一下,对同一张图片,运行姿势探测的效果。
cargo run --release -- assets/football.jpg --which m --task pose
我们的工具在 assets 目录下生成 football.pp.jpg 文件,打开后效果如下:

效果是不是很 cool。下面我们详细解释一下这次实战的代码。
源码解释
YOLOv8 神经网络模型的原理比较复杂,这节课我们主要讲解这个示例中 Rust 的用法,从中可以学到不少 Rust 相关知识。
// #[cfg(feature = "mkl")] // extern crate intel_mkl_src; // #[cfg(feature = "accelerate")] // extern crate accelerate_src; mod model; use model::{Multiples, YoloV8, YoloV8Pose}; mod coco_classes; use candle_core::utils::{cuda_is_available, metal_is_available}; use candle_core::{DType, Device, IndexOp, Result, Tensor}; use candle_nn::{Module, VarBuilder}; use candle_transformers::object_detection::{non_maximum_suppression, Bbox, KeyPoint}; use clap::{Parser, ValueEnum}; use image::DynamicImage; // Keypoints as reported by ChatGPT :) // Nose // Left Eye // Right Eye // Left Ear // Right Ear // Left Shoulder // Right Shoulder // Left Elbow // Right Elbow // Left Wrist // Right Wrist // Left Hip // Right Hip // Left Knee // Right Knee // Left Ankle // Right Ankle const KP_CONNECTIONS: [(usize, usize); 16] = [ (0, 1), (0, 2), (1, 3), (2, 4), (5, 6), (5, 11), (6, 12), (11, 12), (5, 7), (6, 8), (7, 9), (8, 10), (11, 13), (12, 14), (13, 15), (14, 16), ]; // 获取设备,Cpu还是Cuda或Metal pub fn get_device(cpu: bool) -> Result<Device> { if cpu { Ok(Device::Cpu) } else if cuda_is_available() { Ok(Device::new_cuda(0)?) } else if metal_is_available() { Ok(Device::new_metal(0)?) } else { #[cfg(all(target_os = "macos", target_arch = "aarch64"))] { println!( "Running on CPU, to run on GPU(metal), build this example with `--features metal`" ); } #[cfg(not(all(target_os = "macos", target_arch = "aarch64")))] { println!("Running on CPU, to run on GPU, build this example with `--features cuda`"); } Ok(Device::Cpu) } } // 报告对象探测的结果,以及用图像处理工具在图上画出来标注 pub fn report_detect( pred: &Tensor, img: DynamicImage, w: usize, h: usize, confidence_threshold: f32, nms_threshold: f32, legend_size: u32, ) -> Result<DynamicImage> { let pred = pred.to_device(&Device::Cpu)?; let (pred_size, npreds) = pred.dims2()?; let nclasses = pred_size - 4; let mut bboxes: Vec<Vec<Bbox<Vec<KeyPoint>>>> = (0..nclasses).map(|_| vec![]).collect(); // 选出符合置信区间的结果 for index in 0..npreds { let pred = Vec::<f32>::try_from(pred.i((.., index))?)?; let confidence = *pred[4..].iter().max_by(|x, y| x.total_cmp(y)).unwrap(); if confidence > confidence_threshold { let mut class_index = 0; for i in 0..nclasses { if pred[4 + i] > pred[4 + class_index] { class_index = i } } if pred[class_index + 4] > 0. { let bbox = Bbox { xmin: pred[0] - pred[2] / 2., ymin: pred[1] - pred[3] / 2., xmax: pred[0] + pred[2] / 2., ymax: pred[1] + pred[3] / 2., confidence, data: vec![], }; bboxes[class_index].push(bbox) } } } non_maximum_suppression(&mut bboxes, nms_threshold); // 在原图上标注,并打印标注的框的信息 let (initial_h, initial_w) = (img.height(), img.width()); let w_ratio = initial_w as f32 / w as f32; let h_ratio = initial_h as f32 / h as f32; let mut img = img.to_rgb8(); let font = Vec::from(include_bytes!("roboto-mono-stripped.ttf") as &[u8]); let font = rusttype::Font::try_from_vec(font); for (class_index, bboxes_for_class) in bboxes.iter().enumerate() { for b in bboxes_for_class.iter() { println!("{}: {:?}", coco_classes::NAMES[class_index], b); let xmin = (b.xmin * w_ratio) as i32; let ymin = (b.ymin * h_ratio) as i32; let dx = (b.xmax - b.xmin) * w_ratio; let dy = (b.ymax - b.ymin) * h_ratio; if dx >= 0. && dy >= 0. { imageproc::drawing::draw_hollow_rect_mut( &mut img, imageproc::rect::Rect::at(xmin, ymin).of_size(dx as u32, dy as u32), image::Rgb([255, 0, 0]), ); } if legend_size > 0 { if let Some(font) = font.as_ref() { imageproc::drawing::draw_filled_rect_mut( &mut img, imageproc::rect::Rect::at(xmin, ymin).of_size(dx as u32, legend_size), image::Rgb([170, 0, 0]), ); let legend = format!( "{} {:.0}%", coco_classes::NAMES[class_index], 100. * b.confidence ); imageproc::drawing::draw_text_mut( &mut img, image::Rgb([255, 255, 255]), xmin, ymin, rusttype::Scale::uniform(legend_size as f32 - 1.), font, &legend, ) } } } } Ok(DynamicImage::ImageRgb8(img)) } // 报告姿态探测的结果,以及用图像处理工具在图上画出来标注 pub fn report_pose( pred: &Tensor, img: DynamicImage, w: usize, h: usize, confidence_threshold: f32, nms_threshold: f32, ) -> Result<DynamicImage> { let pred = pred.to_device(&Device::Cpu)?; let (pred_size, npreds) = pred.dims2()?; if pred_size != 17 * 3 + 4 + 1 { candle_core::bail!("unexpected pred-size {pred_size}"); } let mut bboxes = vec![]; // 选出符合置信区间的结果 for index in 0..npreds { let pred = Vec::<f32>::try_from(pred.i((.., index))?)?; let confidence = pred[4]; if confidence > confidence_threshold { let keypoints = (0..17) .map(|i| KeyPoint { x: pred[3 * i + 5], y: pred[3 * i + 6], mask: pred[3 * i + 7], }) .collect::<Vec<_>>(); let bbox = Bbox { xmin: pred[0] - pred[2] / 2., ymin: pred[1] - pred[3] / 2., xmax: pred[0] + pred[2] / 2., ymax: pred[1] + pred[3] / 2., confidence, data: keypoints, }; bboxes.push(bbox) } } let mut bboxes = vec![bboxes]; non_maximum_suppression(&mut bboxes, nms_threshold); let bboxes = &bboxes[0]; // 在原图上标注,并打印标注的框和姿势的信息 let (initial_h, initial_w) = (img.height(), img.width()); let w_ratio = initial_w as f32 / w as f32; let h_ratio = initial_h as f32 / h as f32; let mut img = img.to_rgb8(); for b in bboxes.iter() { println!("{b:?}"); let xmin = (b.xmin * w_ratio) as i32; let ymin = (b.ymin * h_ratio) as i32; let dx = (b.xmax - b.xmin) * w_ratio; let dy = (b.ymax - b.ymin) * h_ratio; if dx >= 0. && dy >= 0. { imageproc::drawing::draw_hollow_rect_mut( &mut img, imageproc::rect::Rect::at(xmin, ymin).of_size(dx as u32, dy as u32), image::Rgb([255, 0, 0]), ); } for kp in b.data.iter() { if kp.mask < 0.6 { continue; } let x = (kp.x * w_ratio) as i32; let y = (kp.y * h_ratio) as i32; imageproc::drawing::draw_filled_circle_mut( &mut img, (x, y), 2, image::Rgb([0, 255, 0]), ); } for &(idx1, idx2) in KP_CONNECTIONS.iter() { let kp1 = &b.data[idx1]; let kp2 = &b.data[idx2]; if kp1.mask < 0.6 || kp2.mask < 0.6 { continue; } imageproc::drawing::draw_line_segment_mut( &mut img, (kp1.x * w_ratio, kp1.y * h_ratio), (kp2.x * w_ratio, kp2.y * h_ratio), image::Rgb([255, 255, 0]), ); } } Ok(DynamicImage::ImageRgb8(img)) } // 选择模型尺寸 #[derive(Clone, Copy, ValueEnum, Debug)] enum Which { N, S, M, L, X, } // 对象探测任务还是姿势探测任务 #[derive(Clone, Copy, ValueEnum, Debug)] enum YoloTask { Detect, Pose, } // 命令行参数定义,基于Clap #[derive(Parser, Debug)] #[command(author, version, about, long_about = None)] pub struct Args { /// 是否运行在CPU上面 #[arg(long)] cpu: bool, /// 是否记录日志 #[arg(long)] tracing: bool, /// 模型文件路径 #[arg(long)] model: Option<String>, /// 用哪一个模型 #[arg(long, value_enum, default_value_t = Which::S)] which: Which, images: Vec<String>, /// 模型置信门槛 #[arg(long, default_value_t = 0.25)] confidence_threshold: f32, /// non-maximum suppression的阈值 #[arg(long, default_value_t = 0.45)] nms_threshold: f32, /// 要执行的任务 #[arg(long, default_value = "detect")] task: YoloTask, /// 标注的字体的大小 #[arg(long, default_value_t = 14)] legend_size: u32, } impl Args { fn model(&self) -> anyhow::Result<std::path::PathBuf> { let path = match &self.model { Some(model) => std::path::PathBuf::from(model), None => { let api = hf_hub::api::sync::Api::new()?; let api = api.model("lmz/candle-yolo-v8".to_string()); let size = match self.which { Which::N => "n", Which::S => "s", Which::M => "m", Which::L => "l", Which::X => "x", }; let task = match self.task { YoloTask::Pose => "-pose", YoloTask::Detect => "", }; api.get(&format!("yolov8{size}{task}.safetensors"))? } }; Ok(path) } } pub trait Task: Module + Sized { fn load(vb: VarBuilder, multiples: Multiples) -> Result<Self>; fn report( pred: &Tensor, img: DynamicImage, w: usize, h: usize, confidence_threshold: f32, nms_threshold: f32, legend_size: u32, ) -> Result<DynamicImage>; } // Yolov8为对象探测的类型载体 impl Task for YoloV8 { fn load(vb: VarBuilder, multiples: Multiples) -> Result<Self> { YoloV8::load(vb, multiples, /* num_classes=*/ 80) } fn report( pred: &Tensor, img: DynamicImage, w: usize, h: usize, confidence_threshold: f32, nms_threshold: f32, legend_size: u32, ) -> Result<DynamicImage> { report_detect( pred, img, w, h, confidence_threshold, nms_threshold, legend_size, ) } } // YoloV8Pose为姿势探测的类型载体 impl Task for YoloV8Pose { fn load(vb: VarBuilder, multiples: Multiples) -> Result<Self> { YoloV8Pose::load(vb, multiples, /* num_classes=*/ 1, (17, 3)) } fn report( pred: &Tensor, img: DynamicImage, w: usize, h: usize, confidence_threshold: f32, nms_threshold: f32, _legend_size: u32, ) -> Result<DynamicImage> { report_pose(pred, img, w, h, confidence_threshold, nms_threshold) } } // 主体运行逻辑 pub fn run<T: Task>(args: Args) -> anyhow::Result<()> { let device = get_device(args.cpu)?; // 选择模型尺寸,加载模型权重参数进来 let multiples = match args.which { Which::N => Multiples::n(), Which::S => Multiples::s(), Which::M => Multiples::m(), Which::L => Multiples::l(), Which::X => Multiples::x(), }; let model = args.model()?; let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model], DType::F32, &device)? }; let model = T::load(vb, multiples)?; println!("model loaded"); for image_name in args.images.iter() { println!("processing {image_name}"); let mut image_name = std::path::PathBuf::from(image_name); let original_image = image::io::Reader::open(&image_name)? .decode() .map_err(candle_core::Error::wrap)?; let (width, height) = { let w = original_image.width() as usize; let h = original_image.height() as usize; if w < h { let w = w * 640 / h; // (w / 32 * 32, 640) } else { let h = h * 640 / w; (640, h / 32 * 32) } }; let image_t = { let img = original_image.resize_exact( width as u32, height as u32, image::imageops::FilterType::CatmullRom, ); let data = img.to_rgb8().into_raw(); Tensor::from_vec( data, (img.height() as usize, img.width() as usize, 3), &device, )? .permute((2, 0, 1))? }; let image_t = (image_t.unsqueeze(0)?.to_dtype(DType::F32)? * (1. / 255.))?; let predictions = model.forward(&image_t)?.squeeze(0)?; println!("generated predictions {predictions:?}"); let image_t = T::report( &predictions, original_image, width, height, args.confidence_threshold, args.nms_threshold, args.legend_size, )?; image_name.set_extension("pp.jpg"); println!("writing {image_name:?}"); image_t.save(image_name)? } Ok(()) } // 程序入口 pub fn main() -> anyhow::Result<()> { use tracing_chrome::ChromeLayerBuilder; use tracing_subscriber::prelude::*; let args = Args::parse(); let _guard = if args.tracing { let (chrome_layer, guard) = ChromeLayerBuilder::new().build(); tracing_subscriber::registry().with(chrome_layer).init(); Some(guard) } else { None }; match args.task { YoloTask::Detect => run::<YoloV8>(args)?, YoloTask::Pose => run::<YoloV8Pose>(args)?, } Ok(()) }
我挑选里面一些重要的内容来讲解一下。
第 7 ~ 8 行,加载模型模块。YOLOv8 的模型实现都放在这里面,它在 Candle 的平台基础上实现了一个简易版本的 Darknet 神经网络引擎。第 9 行,加载 coco 数据集分类表。YOLOv8 对数据分成 80 种类别。你可以打开 coco_classes.rs 文件查看。
第 11 ~ 14 行,引入 Candle 基础组件。第 15 行引用 clap 赋能命令行功能。这个在上一讲中已经讲过了。第 16 行引入 image crate。我们在这个例子里处理图片使用的是 image 和 imageproc 两个 crate。
第 36 ~ 53 行是人体姿势的参数配置 KP_CONNECTIONS。
第 57 ~ 77 行,是在 candle 中获取能使用的设备的函数。可以看到,Linux 和 Windows 下我们可以使用 CUDA,mac 下我们可以使用 Metal。
第 79 ~ 167 行,report_detect 是第一个任务,对象探测的业务代码。第 169 ~ 258 行,report_pose 是第二个任务,姿势探测的业务代码。这两个任务我们等会儿还会再说到。
第 260 ~ 267 行,定义选用哪个模型,分别对应前面讲到的 N、S、M、L、X。第 269 ~ 273 行,定义对象探测和姿势探测两个不同的任务。第 275 ~ 311 行,定义命令行参数对象 Args,你可以关注一下各个字段的默认值。第 313 ~ 336 行,定义 model 函数,实际是加载到模型的正确路径,如果本地没有,就会从 HuggingFace 上下载。
第 338 ~ 349 行,定义 Task trait,它依赖另外两个 trait:Module 和 Sized。Module 来自 candle_nn crate,表示神经网络中的一个模块,有向前推理 forward 的功能。Sized 来自 Rust std 标准库,表示被实现的类型是固定尺寸的。
第 351 ~ 375 行,为 YOLOv8 实现 Task trait,YOLOv8 就是我们用于目标探测的任务承载类型。第 377 ~ 393,为 YOLOv8Pose 实现 Task trait,YOLOv8Pose 就是我们用于姿势探测的任务承载类型。
第 395 ~ 459 行是业务内容。第 461 ~ 480 行是 main 函数,里面做了一些日志配置,并且根据任务类型分配到 YOLOv8 或 YOLOv8Pose 两个不同的任务去。
我们看到,这里使用了 run::<YoloV8>(args) 这种写法,再对照 run 的函数签名:
pub fn run<T: Task>(args: Args) -> anyhow::Result<()> {
这个函数签名中有一个类型参数 T,被 Task 约束。根据 第 10 讲 的内容,我们可以说类型 T 具有 Task 的能力。 ::<> 是 turbofish 语法,用来将具体的类型传递进函数的类型参数中。
进入 run() 函数中,我们继续看。第 405、406 行,根据指定的不同的模型,将预训练模型的内容加载成 model 实例。第 407 行有个 T::load() 写法,实际就是 YOLOv8 和 YOLOv8Pose 上都实现了 load() 关联函数,它定义在 Task trait 中。
然后第 409 行可以批量对多个图片进行操作,这个需要你在命令行中传参数指定。我们前面的示例只处理一张图片。然后下面第 415 ~ 426 行,是对图片尺寸的规约化处理。因为 YOLOV8 只能在 640px x 640px 的图片上进行检测,所以需要在代码中预处理一下。
第 427 ~ 440 行是将处理后的图片加载成 Tensor 对象。第 441 ~ 442 行,执行推理预测。第 444 ~ 452 行,调用各自任务的汇报业务。第 453 ~ 455 行,生成处理后的图片,写入磁盘中。
第 444 行出现了 T::report(),解释跟前面一样,实际就是 YOLOv8 和 YOLOv8Pose 上都实现了 report() 关联函数,它定义在 Task trait 中。然后这个 T::report() 会进一步路由到 report_detect() 和 report_pose() 函数中,各自调用。
在各自的 report 函数中,会对上一步 YOLOv8 预测的边框值按置信区间进行筛选,然后对图片添加标注,也就是画那些线和框。这样就生成了我们看到的效果图的内存对象。
到这里为止,全部代码就讲解完成了。细节比较生硬,还是图片好玩!
小结
这节课我们使用 Rust 实现了 Yolov8 算法探测图像中的对象和人物的姿势。从实现过程来说,并不比 Python 版本的实现复杂多少。而且从部署上来讲,Rust 编译后就一个二进制可执行文件,对于做成一个软件(后面两讲我们会讲如何用 GUI 界面)要方便很多。
另一方面,代码中对于函数的返回值,使用了 anyhow::Result<T>。上节课我们讲过,使用 anyhow 的返回类型能够大大减少我们的心智负担。
这个版本的 Yolov8 的算法,是实现在 Candle 框架这个平台上的,你可以研究一下 model.rs 文件,可以看到,代码量非常少。因为有了 Candle 的基础设施,实现一个新的神经网络算法其实非常简单。
以前,当我们想学习图像识别的时候,我们就得求助于 Python 或 C++。以后你也可以使用 Rust 玩起来了,我以后会持续地输出关于 Rust 在 AI 领域的应用,你可以持续关注,我们一起推进 Rust 在 AI 领域的影响力。
思考题
请你开启 cuda 或 metal 特性尝试一下,使用不同的预训练模型看一下效果差异。另外你还可以换用不同的图片来测试一下各种识别效果。
欢迎你把你实验的结果分享到评论区,也欢迎你把这节课的内容分享给其他朋友,邀他一起学习 Rust,我们下节课再见!
Rust GUI编程:用Slint为Chatbot实现一个界面
你好,我是Mike。今天我们一起来学习如何用Rust进行GUI开发,我们用的GUI库是Slint。
GUI开发非常有趣,它能让你看到立竿见影的效果。这是为什么很多人学习编程喜欢从GUI开发开始(Web开发也是类似的道理)。而且GUI库还能用来做点小游戏什么的,非常有趣。而这两年,Rust生态中冒出来几个非常不错的GUI库,比如Slint、egui、Makepad等,今天我们就以Slint为例来讲讲。
学完这节课的内容,你就能使用Rust动手编写GUI程序了。
Slint简介
Slint是一个轻量级的GUI框架,使用Rust实现,提供了Rust、CPP、JavaScript接口。对,你没看错,你也可以用JavaScript来调用Slint库做GUI开发。Slint的架构简洁优美,你可以在1~2天的时间里掌握它的理念和编程方法。
Slint的两位创始人之前是QT的核心开发者,因此从Slint上可以看到非常浓厚的QT(主要是QML)风格。QT是目前IT业界最流行的品质最好的开源跨平台GUI库,可以说Slint继承了QT的最佳实践,同时又与编程语言界的最佳实践Rust结合起来,得到了一个相当优美的GUI框架。
Slint可以在Windows、macOS、Linux、浏览器,以及各种嵌入式平台上运行,现在也在做Android和iOS的适配工作。Slint支持多国语言,它是使用gettext这种传统的Linux方式来做的。
这是Slint的 官方地址,你可以在浏览器里面体验它的 demos,还有2个比较重要的资料,就是 reference 和 Rust API,你可以点击链接了解一下。
注:这一讲的代码适用于 Slint v1.3 版本。
界面语言 slint
Slint自己设计了一门界面描述语言 slint,界面描述文件以 .slint 后缀结尾。slint看起来是下面这个样子:
component MyButton inherits Text {
color: black;
// ...
}
export component MyApp inherits Window {
preferred-width: 200px;
preferred-height: 100px;
Rectangle {
width: 200px;
height: 100px;
background: green;
}
MyButton {
x:0;y:0;
text: "hello";
}
MyButton {
y:0;
x: 50px;
text: "world";
}
}
slint 这门“新语言”只是用于界面描述的,并不是真正的编程语言,因此你可以把它当作HTML这种Markup语言来看待。
界面相关的基础设施在slint里面都有,比如用来布局的 HorizontalLayout、VerticalLayout、GridLayout、对齐、stretch、字体、各种属性设置、各种基本控件等等。
Component
你的所有界面都应该放在一棵Component组件树里面。比如上面的示例中,MyApp 继承自 Slint 提供的 Window 组件,也叫基础元素 Element,MyButton 继承自Text基础元素。MyApp中可以包含Slint基础元素或自定义的其他组件。这样就形成了一棵界面的组件树。
export 关键字用来表明这个组件可以被外部 .slint 文件使用,这样就可以用来开发界面库,供其他应用使用。
Property
属性分为基础预定义属性和自定义属性。
export component Example inherits Window {
width: 42px;
height: 42px;
}
例子里的width和height就是基础属性。
export component Example {
property<int> my-property;
property<int> my-second-property: 42;
}
代码里的 my-property 和 my-second-property 就是自定义属性,用 property<T> 的形式来定义。属性可以用 in、out、in-out、private等修饰符修饰。
export component Button {
in property <string> text;
out property <bool> pressed;
in-out property <bool> checked;
private property <bool> has-mouse;
}
其中:
- in:表示这个属性只能被这个组件的用户(比如Rust代码)修改,或者以绑定的形式被修改,在.slint文件内不能用赋值语句修改这个属性。
- out:表示这个属性只能被这个组件内部修改,也就是在.slint文件中定义的逻辑去修改,在外部使用的时候,比如Rust语言中,只能读,不能改。
- in-out:内部外部都能改,也都能读。
- private:这个属性只能由本组件在内部访问,不能由这个组件的父组件访问,也不能在Rust中访问。
绑定
与React等现代Web前端框架类似,Slint中也有绑定概念。绑定给编程带来了很好的体验,比如下面代码:
import { Button } from "std-widgets.slint";
export component Example inherits Window {
preferred-width: 50px;
preferred-height: 50px;
Button {
property <int> counter: 3;
clicked => { self.counter += 3 }
text: self.counter * 2;
}
}
Button的text属性,就随着 counter 属性的变化而自动变化,Slint在内部自动做了重新计算和更新状态的通知,不用我们操心。
更棒的是还有双向绑定这个东西,看下面的示例:
export component Example {
in property<brush> rect-color <=> r.background;
r:= Rectangle {
width: parent.width;
height: parent.height;
background: blue;
}
}
双向绑定用 <=> 符号,表示这两个属性始终同步。上面的示例里,Example component的rect-color属性和它的子元素 Rectangle r 的background 双向绑定上了,因此它们任何一方变化了,另一方就会自动跟着变化。这里 r := Rectangle 这个语法表示给这个子元素命名为 r,然后这个 r 就可以在这个 component 里的其他地方引用,用来指代这个子元素。
有了绑定,我们写业务就能节省大量样板代码,而且不容易出错。
Callback
回调用于这个component内部元素之间,以及和外部Rust代码之间进行交互。看下面代码:
export component Example inherits Rectangle {
callback hello;
area := TouchArea {
clicked => {
root.hello()
}
}
}
代码定义了callback hello。TouchArea 子元素有个 clicked 预定义的 callback,点击的时候会触发,触发时执行Example组件中的hello回调,就是我们刚才定义那个callback hello。
可以看到 hello 回调还没有回调体实现,我们可以使用下面这种形式,在这个组件内部或者在 Rust 侧进行实现。
ui_handle.on_hello(move || {
//
});
写的时候在Rust侧自动加上 on_ 前缀,给这个组件定义一个回调的函数内容。
内置Widgets
Slint内置了一些控件,它们就是预定义的组件实现。现在控件不算多,还需要继续努力开发。目前就是下面这些。
- AboutSlint
- Button
- CheckBox
- ComboBox
- GridBox
- GroupBox
- HorizontalBox
- LineEdit
- ListView
- ProgressIndication
- ScrollView
- Slider
- SpinBox
- Spinner
- StandardButton
- StandardListView
- StandardTableView
- Switch
- TabWidget
- TextEdit
- VeticalBox
如果你以前有过GUI开发的经验,通过这些名字应该能知道它们是什么。如果没有,可以看看Slint官方的详细说明。这些控件虽然不算太多,但是基本够用。并且在Slint中开发新控件很简单,你可以看 自定义控件介绍,参考 这个链接 里的内容为Slint做一个第三方的控件库扩展库。
编程范式
Slint的编程范式和其他很多GUI框架有些不同,整体显得非常扁平。比如,在Slint中你无法在Rust代码中通过查找拿到某一个element的handle,而是要把element需要交互的属性映射到顶层component的属性上去,通过顶层 App 的 handle 去交互。
Slint页面描述语言显得相当内聚,在Rust代码里(目前)只能通过顶层 App handle 与页面进行交互,而在页面内部则可以充分展开绑定、更新、callback调用等工作。我们在后面的示例里可以充分感受到。
扩展样式
一般,Slint编译出来的界面样式是地道的,也就是说,在哪个平台上就是哪个平台的风格,但是也可以手动选择样式。目前支持 fluent、material、cupertino、qt等几种样式。你可以点击 链接 了解更多。
在了解了Slint的基本概念之后,下面我们开始实操。
IDE插件
VS Code有Slint的插件,对于编写界面和Rust逻辑代码来说非常方便,一定得用。
Chatbot实战
我们要把 第 23 讲 的chatbot命令行程序做成一个GUI程序,双击就可以运行。下面的示例我在Windows上实现,但是代码是跨平台的,不用做任何改动,你可以在其他系统上做实验,如果有问题可以在评论区留言反馈。
创建项目
Slint官方提供了一个Rust项目模板,我们直接用那个。
我们使用 cargo-generate 下载这个模板。如果没有安装这个工具,请执行下面这行命令。
cargo install cargo-generate
安装后下载模板。
cargo generate --git https://github.com/slint-ui/slint-rust-template --name my-project
cd my-project
这里面实现了一个简单的计数器示例。你可以用 cargo run 运行一下,看一下能否弹出来窗口界面。
cargo run
只要你之前安装好了Rust,运行这个命令会自动下载依赖并编译,最后能顺利弹出GUI App程序。你可以回忆一下,以前为了开发Windows GUI程序,是不是得下载一堆玩意儿,还得自己一个一个安装并配置。所以这里你就能看到,用Rust开发真的是太方便了。
依赖库
我们打开 Cargo.toml 文件看一下,发现依赖只有下面两个。
[dependencies]
slint = "1.0"
[build-dependencies]
slint-build = "1.0"
添加代码
我做了一份 样例代码,你可以把代码和对应的模型文件下载下来,然后执行命令。
cargo run --release
运行效果

可以看到,这只是一个简单的聊天对话窗口,一个简单的GUI应用。它也是一个单机版的大语言模型聊天机器人,用的LLM是OpenChat 3.5 量子化Q4版本。请一定要按照这个仓库里的指令下载相关模型文件。
代码详解
appwindow.slint
import { Button, VerticalBox, TextEdit } from "std-widgets.slint";
export component AppWindow inherits Window {
title: "OpenChat Bot";
width: 500px;
height: 550px;
forward-focus: ed2;
in-out property<string> dialog;
in-out property<string> input-ask;
callback send-ask-content(string);
VerticalBox {
Text {
text: "Model: openchat_3.5.Q4_K_M.gguf";
}
ed1 := TextEdit {
font-size: 15px;
width: parent.width - 20px;
vertical-stretch: 1;
read-only: true;
text: root.dialog;
}
ed2 := TextEdit {
font-size: 15px;
width: parent.width - 20px;
height: 100px;
text <=> root.input-ask;
}
Button {
text: "Send";
clicked => {
root.send-ask-content(root.input-ask);
ed2.text = "";
}
}
}
}
我来解释一下这段代码。
代码开头,也就是第1行,从 std-widgets.slint 基础控件库中引入Button、VerticalBox、TextEdit三种控件。然后第3行定义 AppWindow,从Window中继承过来。
第4~6行,设置窗口相关基本属性。第7行的作用是把窗口打开后的焦点传递到ed2里,往下看,ed2就是我们的聊天语句输入框。
第9~10行,定义两个应用级别的属性(顶层自定义属性),dialog表示信息窗口的内容,input-ask表示问题窗口的输入内容。第12行定义一个callback,这里只有签名,没有具体实现,具体实现在后面的Rust代码中来填充。第14行使用VerticalBox进行垂直布局。第15~17是文本标签控件,用于显示当前用的什么模型。
第18~24,用TextEdit控件表示对话消息显示窗口。可以看到,它的text属性被绑定到了上层属性 root.dialog。dialog属性的更新会导致这个TextEdit的text显示内容自动更新。这里这个root表示当前component的顶层,这里也可以用 parent.dialog,表示当前元素的上一层。这里的 vertical-stretch 表示扩展填充,方便布局。这个控件元素用 := 符号命名为 ed1。
第25~30行,用TextEdit控件表示聊天输入窗口。它的text属性被绑定到了 root.input-ask。用的双向绑定 <=> 符号。这个意思是,聊天输入窗口的内容变了, root.input-ask 属性自动同步,反过来也是这样。
第31~37行,定义了一个按钮Button。实现了其clicked回调,当被点击的时候,会调用这个回调。这个回调里面,调用了顶层定义的回调函数 root.send-ask-content(root.input-ask),同时将聊天输入框中的内容清空。
只有这么三十几行代码,所以这个界面本身是比较简单的。下面我们来看一下对应的 Rust 文件。
main.rs
#![allow(unused)] use std::sync::mpsc::channel; mod token_output_stream; mod llmengin; slint::include_modules!(); fn main() -> Result<(), slint::PlatformError> { let ui = AppWindow::new()?; let ui_handle = ui.as_weak(); let (sender, receiver) = channel::<String>(); let sender1 = sender.clone(); let _thread = std::thread::spawn(move || { if let Err(_) = llmengin::start_engine(ui_handle, receiver) { // process before exit. } }); let ui_handle = ui.as_weak(); ui.on_send_ask_content(move |content| { update_dialog(ui_handle.clone(), content.to_string()); sender.send(content.to_string()).unwrap(); }); ui.window().on_close_requested(move || { sender1.send("_exit_".to_string()).unwrap(); slint::CloseRequestResponse::HideWindow }); ui.run() } fn update_dialog(ui_handle: slint::Weak<AppWindow>, msg: String) { _ = slint::invoke_from_event_loop(move || { let ui_handle = ui_handle.unwrap(); let old_content = ui_handle.get_dialog(); ui_handle.set_dialog(old_content + &msg + "\n"); }); } fn update_dialog_without_ln(ui_handle: slint::Weak<AppWindow>, msg: String) { _ = slint::invoke_from_event_loop(move || { let ui_handle = ui_handle.unwrap(); let old_content = ui_handle.get_dialog(); ui_handle.set_dialog(old_content + &msg); }); }
第4~5行引入大模型引擎实现模块。第7行用 slint::include_modules!() 将编译后的slint界面资源文件加载进来。
第10行创建 AppWindow 实例,这个 AppWindow 就是前面 slint 文件中定义的 AppWindow 组件,也就是当前应用。第12行获得 AppWindow 实例的弱引用。弱引用在Rust中是一种智能指针,用来防止产生循环引用。我们这里照做就行了。
第13~14行创建一个 MPSC 的 channel。这个channel 是Rust 标准库里的,用于在线程间进行通信。
第16~20行启动一个新的系统线程。我们这个是一个本地大模型推理应用,大模型的推理是非常消耗资源的,我们不应该放在主线程(主循环,同时负责渲染UI)中,而应该放在后台信息中执行。 llmengin::start_engine() 就用于启动这个后台任务。可以看到,我们将弱引用 ui_handle 传了进去,用于在后台任务中拿到主线程的句柄,方便更新内容。同时,我们把 receiver 传了进去,这样后台任务就可以接收UI主线程发来的消息了。
第22~26行的 on_send_ask_content() 用来填充 slint 界面文件中定义的 send-ask-content(string) 回调函数,给这个回调函数填充具体的执行逻辑。这个函数名是按映射规则由slint自动为我们生成的,也就是在前面加了 on_ 前缀,并且把 - 号替换成了 _ 号。具体来说执行了两个任务,一是把聊天输入框的内容更新到消息对话窗口中,二是用channel 的 sender 向后台任务发送消息。
第28~31行用来处理当窗口关闭时的行为,因为我们有后台任务,后台任务与前台main loop任务都是两个loop在无限跑,我们不能对后台任务用 join 方法,因为那样会阻塞主线程循环。在主线程循环退出的时候,也要通知后台任务退出,这样才安全。
剩下的 update_dialog() 和 update_dialog_without_ln() 就是用来更新消息对话窗口的内容的。 slint::invoke_from_event_loop() 可以在任何线程中调用,它保证这个函数中的闭包会在主线程循环中被调用。
这里其实在它内部用了一个 channel queue 来实现。也就是说,后台任务的输出结果,不需要我们手动地传回到主线程中来操作了,只需要调用这个函数,就可以将界面上对应的内容更新。更新UI的逻辑,实际的执行还是在主线程中做的。 ui_handle.get_dialog() 和 ui_handle.set_dialog() 是 slint 自动帮我们生成的,就是在顶层属性 dialog 上自动生成了 getter 和 setter。
llmengin.rs
llmengin.rs 代码行数比较多,你可以打开 链接 查看。代码大体上和 第 23 讲 是一样的,不过有几处更改。
// 这几行代码片段从llmengin.rs文件中的第99行开始
super::update_dialog_without_ln(ui_handle.clone(), "> ".to_string());
let ask = receiver.recv().unwrap();
if ask == "_exit_" {
return Err(anyhow::anyhow!("exit".to_string()));
}
let prompt_str = format!("User:{ask}<|end_of_turn|>Assistant:");
第101行 使用了 let ask = receiver.recv().unwrap(); 来从channel中接收信息,也就是从主线程中接收聊天输入消息。第102~104行是用来处理退出后台线程的指令。在这里你可以看到 anyhow! 的用法。
其他的就是把 print!() 代码全部换成了 super::update_dialog_*() 相关代码,用来把输出结果更新到界面上去。
整体来说,还是非常简单的。
小结
这节课我们通过这短短几十行代码,就使用Slint框架,用Rust做了一个GUI应用。而且整个过程中,我们甚至不需要手动下载额外的依赖安装包,一个命令 cargo run 就搞定了。这就是Rust相比于C++甚至Python更方便的地方。
在这个示例里,我们对 第 23 讲 的chatbot代码做了一些改造,主要的变化在输入和输出上面。改的也不多,只有几行。
后台任务是一个重要概念,因为GUI界面需要有一个系统线程主循环来负责更新,耗时比较多的任务不应该放在这个线程里运行,不然会让界面显得很卡。 我们应该使用 std::thread::spawn 创建一个新的系统级线程来运行。
通过这个示例,我们了解了Slint GUI框架的基本概念、编程范式。Slint确实是一个非常简单明了的框架。在熟悉它的规则之后,用它来开发GUI程序是非常快速便捷的。更可喜的是,用Slint编程的程序可以在各大主流平台上运行,还能在网页上运行,快速分发部署,非常方便。
Slint的设计风格延续了Qt(QML)的风格,可以说是业界的最佳实践。使用 Rust + Slint,我们能非常快速地实现我们的想法。还等什么,用Slint做一些有趣的东西吧!
思考题
这节课的示例非常原型化,代码还有很多可以改进的地方,请你思考一下并指出一两处。欢迎你把你的想法分享到评论区,也欢迎你把这节课的内容分享给需要的朋友,邀他一起学习Rust,我们下节课再见!
Rust GUI编程:用Slint为YOLOv8实现一个界面
你好,我是Mike。
今天我们继续用Slint做一个小项目。这个项目的目标是为我们 第 24 讲 实现的用YOLOv8从图片中识别出对象及姿势的小应用提供一个GUI界面。
这个GUI程序非常实用,可以以一种真观对比的形式让你看到对原始图片经过AI加工后的效果。比如像下面这样:

原理解析
根据我们上节课学到的知识及第24讲里的操作流程,我们的实现应该分成4步。
- 选择一张图片,加载显示在界面左边。
- 点击 “Detect Objects”或 “Detect Poses”。
- 经过YOLOv8引擎计算和标注,生成一张新的图片。
- 在界面右边加载这张新图片。
下面让我们开始动手操作。
注:这节课的代码适用于 Slint v1.3 版本。
分步骤实现
创建项目
我们还是使用官方提供的Slint模板来创建,先下载模板。
cargo generate --git https://github.com/slint-ui/slint-rust-template --name slint-yolov8-demo
cd slint-yolov8-demo
运行 cargo run 测试一下。
设计界面
这个应用其实不复杂,你可以这样来分解这个界面。
- 从上到下使用一个 VerticalBox,分成三部分:Model说明、图片显示区、按钮区。
- 图片显示区使用一个 HorizontalBox,分成三部分:左边图片显示区、中间分隔线、右边图片显示区。图片使用 Image 基础元素来显示。
- 按钮区,使用HorizontalBox排列三个按钮:选择图片、探测对象、探测姿势,并且左对齐。
这样界面就设计好了。
设计回调
这个小工具的回调任务的步骤也很清晰。
-
界面刚打开的时候,显示空白界面。
-
点击 “Select Picture”后,弹出图片选择对话框,选择一张图片,并显示在左侧。
-
点击“Detect Objects”,生成新图片,显示在右侧。
-
点击“Detect Poses”,生成新图片,显示在右侧。

整个项目回调的逻辑就描述完成了。
下载模型
我们最好先手动下载YOLOv8的两个模型文件,下载方式如下:
HF_HUB_ENABLE_HF_TRANSFER=1 HF_ENDPOINT=https://hf-mirror.com huggingface-cli download lmz/candle-yolo-v8 yolov8m.safetensors
HF_HUB_ENABLE_HF_TRANSFER=1 HF_ENDPOINT=https://hf-mirror.com huggingface-cli download lmz/candle-yolo-v8 yolov8m-pose.safetensors
这是为 HuggingFace candle框架定制的两个模型文件,我们下载的是 object 和 pose medium 大小的 safetensors 格式的模型文件,我们需要把它们拷贝到当前项目的根目录下。像下面这样:
$ ls -lh
total 101M
-rwxr-xr-x 1 mike mike 150K Dec 9 14:58 Cargo.lock
-rwxr-xr-x 1 mike mike 615 Dec 9 14:58 Cargo.toml
-rwxr-xr-x 1 mike mike 1.1K Dec 9 14:58 LICENSE
-rwxr-xr-x 1 mike mike 747 Dec 9 18:29 README.md
drwxr-xr-x 2 mike mike 4.0K Dec 9 18:27 assets
-rwxr-xr-x 1 mike mike 71 Dec 9 14:58 build.rs
-rwxr-xr-x 1 mike mike 168K Dec 9 14:58 football.jpg
drwxr-xr-x 3 mike mike 4.0K Dec 9 14:58 src
drwxr-xr-x 4 mike mike 4.0K Dec 9 15:03 target
drwxr-xr-x 2 mike mike 4.0K Dec 9 14:58 ui
-rw-r--r-- 1 mike mike 51M Dec 9 17:45 yolov8m-pose.safetensors
-rw-r--r-- 1 mike mike 50M Dec 9 17:45 yolov8m.safetensors
下面我们就开始动手写代码吧!
代码实现和解析
有了前面几讲的经验,我们应该能比较轻松地完成这次任务。
界面文件
我们先来看一下界面描述文件 ui/appwindow.slint 内容。
import { Button, VerticalBox , HorizontalBox} from "std-widgets.slint";
export component AppWindow inherits Window {
width: 900px;
height: 480px;
in-out property <image> orig-image;
in-out property <string> orig-image-path;
in-out property <image> generated-image;
callback select-orig-pic();
callback probe-objects();
callback probe-poses();
VerticalBox {
width: 100%;
vertical-stretch: 1;
Text {
text: "Model Size: Medium";
}
HorizontalBox {
width: 98%;
vertical-stretch: 1;
Image {
width: 49%;
source: root.orig-image;
}
Rectangle {
width: 1px;
background: gray;
}
Image {
width: 49%;
source: root.generated-image;
}
}
HorizontalBox {
alignment: start;
height: 50px;
Button {
text: "Select Picture..";
clicked => {
root.select-orig-pic();
}
}
Button {
text: "Detect Objects";
clicked => {
root.probe-objects();
}
}
Button {
text: "Detect Poses";
clicked => {
root.probe-poses();
}
}
}
}
}
我们设计了三个顶层应用属性。
in-out property <image> orig-image;
in-out property <string> orig-image-path;
in-out property <image> generated-image;
注意,orig-image 和 generated-image 类型是 image,是slint语言中的图像类型。orig-image-path 类型是 string,是slint语言中的字符串类型,它与 Rust 中的字符串类型可以通过下面的代码互相转换。
slint string -> Rust String: .to_string()
Rust String -> slint string: .into()
根据前面设计回调部分,我们对应地设计了三个回调函数。
callback select-orig-pic();
callback probe-objects();
callback probe-poses();
然后,你还要注意代码里 主体内容区的属性。我们使用 vertical-stretch: 1; 来让这个区域尽量填充,占领能够占领的最大区域,不留空白。然后我们使用 Image widget 来承载图片显示,并把它的 source 属性绑定到 root.orig-image 和 root.generated-image 上面。
然后下面的按钮区,我们使用 alignment: start; 将三个按钮左对齐,并给三个按钮的 clicked 回调写逻辑,调用到对应的顶层回调上面去。
这就是界面描述包含的内容。
main.rs
接下来,我们看main文件内容。
use std::{path::PathBuf, sync::mpsc::channel}; use native_dialog::FileDialog; use slint::{Image, Rgba8Pixel, SharedPixelBuffer}; slint::include_modules!(); mod yolov8engine; fn main() -> Result<(), slint::PlatformError> { let ui = AppWindow::new()?; let ui_handle = ui.as_weak(); ui.on_select_orig_pic(move || { let ui = ui_handle.unwrap(); let path = FileDialog::new() .set_location("~") .add_filter("Pics", &["png", "jpg", "jpeg"]) .show_open_single_file() .unwrap(); // if selected pic file if let Some(path) = path { ui.set_orig_image_path(path.to_string_lossy().to_string().into()); ui.set_orig_image(load_image(path)); } }); let (sender, receiver) = channel::<(String, String)>(); let sender1 = sender.clone(); let sender2 = sender.clone(); let ui_handle = ui.as_weak(); let _thread = std::thread::spawn(move || { loop { let ui_handle = ui_handle.clone(); let (task, img_path) = receiver.recv().unwrap(); if task.as_str() == "_exit_" { // end of this thread return; } let (task, model) = if task.as_str() == "detect" { ( yolov8engine::YoloTask::Detect, Some("yolov8m.safetensors".to_string()), ) } else { ( yolov8engine::YoloTask::Pose, Some("yolov8m-pose.safetensors".to_string()), ) }; if let Ok(path) = yolov8engine::start_engine(task, model, img_path) { _ = slint::invoke_from_event_loop(move || { let ui = ui_handle.unwrap(); ui.set_generated_image(load_image(PathBuf::from(path))); }); } else { } } }); let ui_handle = ui.as_weak(); ui.on_probe_objects(move || { let ui = ui_handle.unwrap(); let img_path = ui.get_orig_image_path().to_string(); println!("{}", img_path); _ = sender.send(("detect".to_string(), img_path)); }); let ui_handle = ui.as_weak(); ui.on_probe_poses(move || { let ui = ui_handle.unwrap(); let img_path = ui.get_orig_image_path().to_string(); println!("{}", img_path); _ = sender1.send(("pose".to_string(), img_path)); }); ui.window().on_close_requested(move || { sender2 .send(("_exit_".to_string(), "".to_string())) .unwrap(); slint::CloseRequestResponse::HideWindow }); ui.run() } fn load_image(path: std::path::PathBuf) -> slint::Image { let mut a_image = image::open(path).expect("Error loading image").into_rgba8(); image::imageops::colorops::brighten_in_place(&mut a_image, 20); let buffer = SharedPixelBuffer::<Rgba8Pixel>::clone_from_slice( a_image.as_raw(), a_image.width(), a_image.height(), ); let image = Image::from_rgba8(buffer); image }
main文件整体结构和上一讲差不多。这里我重点讲一下不同的地方。Slint里没有现成的文件选择组件,因此我们使用了 native_dialog 这个 crate,它是一个跨平台的文件选择组件。FileDialog 这一段返回后的 path 是一个 Option<PathBuf>。如果选择了文件,就会是 Some(path),如果没有选择文件,比如打开了文件选择框,但是又点击了取消按钮或者关闭按钮,就返回 None。
选择图片文件后,用这种 set_* API 把返回的完整路径填充到应用的顶层属性orig-image-path 和 orig-image 上去。
ui.set_orig_image_path(path.to_string_lossy().to_string().into());
ui.set_orig_image(load_image(path));
load_image 会把文件从磁盘里读出来,转换成 Slint 的 image 类型。
后台任务和channel架构也和上节课差不多,我就不赘述了。注意这里使用了模式匹配语法来析构元组消息内容。
yolov8engine::start_engine(task, model, img_path) 是YOLOv8任务的执行器,分别传入任务类型 task、模型名字 model 和原始图片地址 img_path 三个参数,并返回处理后的图片路径 path。然后调用 slint::invoke_from_event_loop() 来更新UI界面。
注意,由于我们的主要逻辑是在后台任务中处理的,不能直接在后台任务中更新 UI 界面,必须使用 slint::invoke_from_event_loop() 把更新界面的逻辑包起来。在slint内部,它还是通过一个 channel queue 把里面的相关值发送到主UI线程来处理。看起来整个过程是自动的,如果不加这个函数,而是直接调用 UI 对象指针,会出现什么问题呢?
没错,所有权问题!这可以看成是Rust的所有权系统在GUI领域的一次实践和验证,它可以在编译期间帮助我们发现和阻绝界面更新上的竞争问题。
这里,你可以想象一下,如果不创建后台任务,而是直接把业务逻辑写在回调函数里会怎样?也就是放在 on_probe_objects() 和 on_probe_poses() 中,你可以试一下。这里我分享一下我试验的结果:对于长时间执行的任务,Slint框架会主动把这些任务kill掉,以免对界面操作造成卡顿。
改造 YOLOv8 示例
剩下的主要工作就是看 yolov8engine::start_engine(task, model, img_path) 是怎么实现的了。
我们在 第 24 讲 实现的YOLOv8的工具是一个命令行界面工具,使用 clap 实现。为了能够整合进现在这个GUI程序,我们首先应该对它的Args类型进行转换,转换成普通的结构体,结构体的字段一部分固定下来,一部分从UI界面传进来。
let args = Args {
cpu: true,
tracing: false,
model,
which: Which::M,
images: vec![img_path],
confidence_threshold: 0.25,
nms_threshold: 0.45,
task,
legend_size: 14,
};
如果你想让所有参数都可定制,完全可以在界面上做得更复杂,让这些参数可以通过界面上的控件来调整数值。
然后,我们再看一下模块的目录组织结构。
$ tree src/
src/
├── main.rs
└── yolov8engine
├── coco_classes.rs
├── mod.rs
├── model.rs
└── roboto-mono-stripped.ttf
1 directory, 5 files
你会发现我们使用的是 2015 edition 的风格。这样做不丢人,很多人喜欢这种目录组织风格。这种风格还有一个好处是可以把第24讲的src代码直接拷贝进来,重命名成 yolov8engine,然后把里面的 main.rs 重命名成 mod.rs。整个代码的结构就重构完成了。
然后把 mod.rs 里面的 fn main() 函数改成 start_engine(task, model, img_path) 即可,这样整个代码结构也改造完成了,剩下的就是要处理一下函数参数的输入和返回值的类型。
在第24讲的代码中, run() 函数没有把生成的新图片的path返回回来,我们将其返回回来,并进一步通过 start_engine() 函数的返回值返回给这个GUI程序的 main() 函数。然后整个业务就完成了。
我把完成代码整理到 这个地址 了,你可以下载下来,按照说明运行一下看看效果,也可以基于这个代码随意改改,实现你的任何想法。
小结
这节课我们使用Slint GUI框架为 YOLOv8 对象和姿势引擎实现了一个图形化界面。有了这个GUI工具,任何人都可以来体验Rust的图像识别能力了。相比于命令行界面,我们将用户群体扩大到了普通用户。
Rust应用的分发也很简单,将编译后的文件拷贝到另一台电脑上就可以运行了,只需要针对不同的平台分别编译不同的目标格式可执行文件。它不像Python实现的对象和姿势识别工具需要先安装一大堆依赖。
我们花了两节课的时间来熟悉使用Slint GUI框架。它是Rust社区冉冉升起的一个明星框架,目前虽然说不上成熟,但是胜在 小巧、灵活,可定制性很强。如果它缺失一些控件什么的,你也可以自己实现。
我们这两节课与第23、24讲结合在一起,做了两组Rust的AI工具。 AI时代刚刚来临,Rust在AI领域有着巨大的潜力和机会。 AI本身覆盖面非常广,比如学术研究、算法实现、训练、推理、部署、云端计算、单机版模型、集群应用、工业应用、行业工具、终端设备、用户界面等等。未来使用Rust作为工具,也是一个相当好的切入点。
思考题
这节课的代码实现有一个性能上的问题,就是每次点击 Detect Objects 或 Detect Poses 的时候,实际上都重复加载了模型,你想一想如何优化这个点?欢迎你把你的想法和优化代码分享到评论区,如果你觉得对你有帮助的话,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
Rust Bevy游戏开发:用300行代码做一个贪吃蛇游戏
你好,我是Mike。今天我们一起来学习Rust游戏编程技术。这节课我们会基于Bevy游戏框架来开发一个入门版的贪吃蛇游戏。
Rust生态内目前已经有不少很不错的游戏开发框架,而Bevy是其中最热门的那一个,目前(2023年12月)最新版本是 0.12,还处在积极开发的过程中。Bevy框架和Axum Web框架、Slint框架给人的感觉有点儿像,都很简单、优美、灵活。用Bevy框架写游戏非常惬意,已经有不少人在尝试使用Bevy开发自己的独立游戏,目前有三款(Molecoole、Tiny Glade、Roids)已经上架或即将上架 Steam。
用Bevy开发的游戏能够运行在Windows、macOS、Linux, Web浏览器等平台。
Bevy框架
Bevy 框架是一个数据驱动的游戏开发框架(引擎),其核心是一个ECS。
ECS
ECS是 Entity Component System 的缩写,意思是实体-组件-系统。它是一种编程范式,这种范式非常有趣,也非常有潜力,现在的主流游戏引擎都开始支持这种编程范式了。这种范式是与传统的OOP(面向对象编程)范式相对的,跟Rust的 trait 的设计理念有一些相似之处。
我们用一个例子来说明ECS是怎样对问题进行建模的。假如现在有这样一幅画面:一个下午,在温暖的家里面,爸爸D正在边吃甜点边看书,妈妈M在边吃甜点边玩手机,儿子S在和狗狗B玩。你想一想,这个场景如果用OOP方式,应该如何建模呢?而用ECS范式可以这样建立模型:

Systems:
system1: dad_task(query: Query<>)
system2: mom_task(query: Query<>)
system3: son_task(query: Query<>)
system4: dog_task(query: Query<>)
这样这个模型就建立好了。
我们用类似数据库table或者Excel的datasheet的形式来描述 Entity 与 Component 之间的关系。Entity 就用简单的数字来表示,只要能区分不同的实体就可以。然后我们定义了Role、Name、Snack、Book、Phone、Playmat 6种Component。
这些Components就像数据库table的列。但是与数据库不同的是,在ECS范式中,这个table的列是可以随着程序的运行而动态增加、减少的。另外一个重要的不同是,并不是所有的Entity都强制拥有所有的Component(列),每个Entity其实只关心自己需要的Components就行了。因此,这里的table表示在数据上的话,更像一个稀疏矩阵或集合。
这其实体现了一种设计哲学: 将所有的信息铺平,用组合的方式来建模。是不是与Rust的trait设计哲学有相似性?
你可以把组件 Component 看作一组属性的集合,将属性按Component拆开来放置有利于复用。在这个例子里,4个实体都复用 Role 组件和 Name组件,Dad和Mommy复用Snack组件,Son和Dog复用Playmate组件。
而System就是行为或逻辑,用来处理上面建好的表格数据。一个System对应在Bevy中,就是普通的Rust函数。当然,这个函数首先要有办法拿到上述表格(世界状态)的操作权力才行,操作的方法就是Query检索。
关于ECS与OOP的对比,你可以参考 这里。
资源(Resource)
对于在整个系统中,只会存在一份的,可以把它定义为 Resource。比如外部的图片素材、模型文件、音频素材等。另外还包含定时器实例、设备抽象等。你可以将资源想象成编程范式中的 Singleton (单例)。
事件(Event)
游戏世界中,有无处不在的并行任务,比如 10 辆坦克同时寻路前进,任务之间的通信,最好是通过事件来沟通。这是一种用于解耦逻辑的编程范式。
世界状态
基于ECS的设计,那张大表table其实就是一个世界状态。基于ECS的游戏引擎,就需要在内部维护这样一个世界状态。这个世界状态的维护非常关键,需要用高效的数据结构和算法实现。在Bevy中具体用什么数据结构来维护的,你可以参考 这里。
固定帧率
游戏一般会以固定帧率运行,比如每秒60帧。游戏引擎通常会封装好这个,将你从帧率刷新的任务中释放出来,专注于游戏逻辑的设计。你只需要知道,你写的游戏逻辑会每秒执行60次,也就是60个滴答 tick。
坐标系统
Bevy的2D默认的坐标系统是原点在窗口正中间的一个正坐标系,像下面这样:
摄相机(Camera)
游戏引擎中都会有Camera的概念,3D游戏的画面渲染严重依赖于Camera。2D游戏不太关心Camera,但使用Camera也会有放大缩小的效果,默认Bevy的Camera在坐标系的Z轴上,也就是当前你眼睛所处的位置。
性能
借助于ECS范式,加上Rust强大的无畏并发能力,Bevy能够让你的systems尽可能地运行在多个CPU核上,也就是并行运算。所以Bevy的基础性能是非常棒的,关于benchmarks的讨论,你可以看 这里。
有了这些基础知识的铺垫,我们下面进入实战环节吧。
实战贪吃蛇
这里我先给出完整代码的 链接,你最好下载下来边运行边对照下面的内容学习。
第1步:引入Bevy库
很简单,引入Bevy库,创建一个App实例。
use bevy::prelude::*; fn main() { App::new().run(); }
这个程序运行后马上就结束了,没有任何输出,也没有窗口打开。
第2步:创建窗口
加入默认Plugin集合,里面有个主事件循环,还有个创建窗口的功能。然后我们需要设置2D的Camera。
use bevy::prelude::*; fn main() { App::new() .add_plugins(DefaultPlugins) .add_systems(Startup, setup_camera) .run(); } fn setup_camera(mut commands: Commands) { commands.spawn(Camera2dBundle::default()); }
由于引擎本身是一个托管系统(带主循环的Runtime),我们要在这个引擎所维护的世界状态里添加(或删除)新的东西,必须使用 Commands 这种任务指令形式。你可以把它想象成总线或消息队列编程模型。
这一步运行后,弹出一个窗口,并且渲染默认背景色。
第3步:画出蛇的头
这一步我们添加一个新函数,创建蛇的头,然后用 add_systems 添加到bevy runtime 中。你可以看一下代码发生的变化。
const SNAKE_HEAD_COLOR: Color = Color::rgb(0.7, 0.7, 0.7);
#[derive(Component)]
struct SnakeHead;
//
.add_systems(Startup, (setup_camera, spawn_snake))
//
fn spawn_snake(mut commands: Commands) {
commands
.spawn(SpriteBundle {
sprite: Sprite {
color: SNAKE_HEAD_COLOR,
..default()
},
transform: Transform {
scale: Vec3::new(10.0, 10.0, 10.0),
..default()
},
..default()
})
.insert(SnakeHead);
}
我们用 struct 定义了 SnakeHead Component,它没有任何字段。没关系,目前一个类型名字符号就能表达我们的意思,当一个tag用。你继续往后面看。
你可以看到,一个system就是一个普通的Rust函数。SpriteBundle 是一个Component Bundle,也就是组件包,可以把一组 components 组合在一起,SpriteBundle 里面就有 Sprite、Transform 等 components。Sprite 就是图片精灵的意思,是游戏里面表达角色的基本方法。Transform 抽象的是角色的运动,有位移、旋转和拉伸变换三种形式。
spawn_snake() system 目的就是创建这个蛇的头,它作为一个entity被插入到世界状态中。 .insert(SnakeHead) 把 SnakeHead 这个 Component 添加到这个刚创建好的 entity 上面。
add_systems() 中的第一个参数 Startup,用来表示这是游戏启动的时候执行的 systems。它们只执行一次,多个systems写在元组里面,更简洁。
你可以看一下这一步的运行效果,窗口中间出现了一个小方块,那就是蛇的头。
第4步:让这条蛇动起来
这里我给出这一步添加的代码,我们边看边解读。
.add_systems(Update, snake_movement)
fn snake_movement(mut head_positions: Query<(&SnakeHead, &mut Transform)>) {
for (_head, mut transform) in head_positions.iter_mut() {
transform.translation.y += 2.;
}
}
这个 snake_movement() 就是处理蛇运动的system,请注意参数
是 Query<(&SnakeHead, &mut Transform)> 类型,它的意思是从世界状态中去查找同时拥有 SnakeHead、Transform 两种 Components 的entity,它定义了一个迭代器,并且 Transform 的实例还是可以修改的。遍历这个迭代器,其实目前只有一个entity,更新负责管理它运动的 transform 实例。 transform.translation.y += 2. 就是纵向坐标向上移动 2 个像素。
add_systems() 的第一个参数Update,表示这个system是运行在游戏运行过程中的,每一帧都需要更新一次(执行一次这个system),也就是这个函数1秒会执行60次。
运行后你会发现这个小方块在自动向上移动,效果如下:
第5步:控制这条蛇的方向
下面我们需要控制蛇的方向,上下左右四个方向。这一步就是给 snake_movement system 填充内容。
fn snake_movement(
keyboard_input: Res<Input<KeyCode>>,
mut head_positions: Query<&mut Transform, With<SnakeHead>>,
) {
for mut transform in head_positions.iter_mut() {
if keyboard_input.pressed(KeyCode::Left) {
transform.translation.x -= 2.;
}
if keyboard_input.pressed(KeyCode::Right) {
transform.translation.x += 2.;
}
if keyboard_input.pressed(KeyCode::Down) {
transform.translation.y -= 2.;
}
if keyboard_input.pressed(KeyCode::Up) {
transform.translation.y += 2.;
}
}
}
Input<KeyCode> 是Bevy系统级的资源,用于表示输入设备,这里是键盘设备。要访问资源就在system里用 Res<T> 这种参数类型。 keyboard_input.pressed() 用于判断是否键盘按下了。
运行后,你就可以用方向键控制这个小方块的运动方向了。
第6步:将窗口网格化
默认Bevy的窗口坐标粒度是以屏幕的逻辑像素为单位的。而像贪吃蛇这种游戏,会将整个画布分成一个个正方形的小方格。具体怎么做,你可以看一下这一步变化的代码。
const ARENA_WIDTH: u32 = 10;
const ARENA_HEIGHT: u32 = 10;
#[derive(Component, Clone, Copy, PartialEq, Eq)]
struct Position {
x: i32,
y: i32,
}
#[derive(Component)]
struct Size {
width: f32,
height: f32,
}
impl Size {
pub fn square(x: f32) -> Self {
Self {
width: x,
height: x,
}
}
}
//
.add_systems(Update, (snake_movement, size_scaling, position_translation))
//
.insert(Position { x: 3, y: 3 })
.insert(Size::square(0.8));
//
// 计算方块元素的大小
fn size_scaling(primary_query: Query<&Window, With<bevy::window::PrimaryWindow>>, mut q: Query<(&Size, &mut Transform)>) {
let window = primary_query.get_single().unwrap();
for (sprite_size, mut transform) in q.iter_mut() {
transform.scale = Vec3::new(
sprite_size.width / ARENA_WIDTH as f32 * window.width() as f32,
sprite_size.height / ARENA_HEIGHT as f32 * window.height() as f32,
1.0,
);
}
}
// 计算位移
fn position_translation(primary_query: Query<&Window, With<bevy::window::PrimaryWindow>>, mut q: Query<(&Position, &mut Transform)>) {
fn convert(pos: f32, bound_window: f32, bound_game: f32) -> f32 {
let tile_size = bound_window / bound_game;
pos / bound_game * bound_window - (bound_window / 2.) + (tile_size / 2.)
}
let window = primary_query.get_single().unwrap();
for (pos, mut transform) in q.iter_mut() {
transform.translation = Vec3::new(
convert(pos.x as f32, window.width() as f32, ARENA_WIDTH as f32),
convert(pos.y as f32, window.height() as f32, ARENA_HEIGHT as f32),
0.0,
);
}
}
这一步,我们添加了 Position 和 Size 两种Components。用来控制蛇头的逻辑位置和显示大小。新增了 size_scaling 和 position_translation 两个system,用来在每一帧计算蛇头的尺寸和位置。
具体的算法理解上要注意的就是,坐标的原点是在窗口正中央,转换后的网格grid的坐标原点在窗口左下角。
你可以看一下这一步运行后的效果。
你可以看到,蛇的头的大小(为一个网格大小的0.8)和位置已经变化了。这里的位置在 (3, 3),网格总大小为 (10, 10),左下角为 (0, 0)。
第7步:让蛇按网格移动
下面要让蛇的运动适配网格。你看一下这一步改动的代码。
fn snake_movement(
keyboard_input: Res<Input<KeyCode>>,
mut head_positions: Query<&mut Position, With<SnakeHead>>,
) {
for mut pos in head_positions.iter_mut() {
if keyboard_input.pressed(KeyCode::Left) {
pos.x -= 1;
}
if keyboard_input.pressed(KeyCode::Right) {
pos.x += 1;
}
if keyboard_input.pressed(KeyCode::Down) {
pos.y -= 1;
}
if keyboard_input.pressed(KeyCode::Up) {
pos.y += 1;
}
}
}
这一步我们要更新蛇头的逻辑坐标,也就是上一步定义那个Position component的实例。现在你可以通过方向键将这个小矩形块移动到其他位置。
第8步:配置窗口比例和尺寸
默认打开的窗口是长方形的,我们要给它配置成方形。你可以看一下这一步的变化代码。
const ARENA_WIDTH: u32 = 25;
const ARENA_HEIGHT: u32 = 25;
//
.add_plugins(DefaultPlugins.set(WindowPlugin {
primary_window: Some( Window {
title: "Snake!".to_string(),
resolution: bevy::window::WindowResolution::new( 500.0, 500.0 ),
..default()
}),
..default()
})
)
.insert_resource(ClearColor(Color::rgb(0.04, 0.04, 0.04)))
//
这一步我们做了4件事情。
- 设置窗口尺寸为500px x 500px。
- 设置窗口标题为 Snake!。
- 设置窗口填充背景颜色为 Color::rgb(0.04, 0.04, 0.04)。
- 分割窗口grid为更大一点的数字,比如25x25。
你看一下这一步的效果。
离我们期望的样子越来越近了。
第9步:随机产生食物
下面要开始产生食物。食物我们也用另一种小方块来表示。你看一下这一步变化的代码。
const FOOD_COLOR: Color = Color::rgb(1.0, 0.0, 1.0);
#[derive(Component)]
struct Food;
.add_systems(Update, food_spawner)
fn food_spawner(mut commands: Commands) {
commands
.spawn(SpriteBundle {
sprite: Sprite {
color: FOOD_COLOR,
..default()
},
..default()
})
.insert(Food)
.insert(Position {
x: (random::<f32>() * ARENA_WIDTH as f32) as i32,
y: (random::<f32>() * ARENA_HEIGHT as f32) as i32,
})
.insert(Size::square(0.8));
}
食物随机产生,所以需要用到random函数。同样,我们定义了 Food 这个 Compoment,然后定义了 food_spawner system,并添加到runtime中去。创建的食物entity上带有 Sprite、Food、Position、Size 等 components。
可以想象,这个创建食物的system1秒会执行60次,也就是1秒钟会创建60个食物,速度太快了。
第10步:使用定时器产生食物
下面我们要控制食物的产生速度,比如2秒产生一颗食物。我们来看这一步变化的代码。
#[derive(Resource)]
struct FoodSpawnTimer(Timer);
.insert_resource(FoodSpawnTimer(Timer::from_seconds(
1.0,
TimerMode::Repeating,
)))
fn food_spawner(
mut commands: Commands,
time: Res<Time>,
mut timer: ResMut<FoodSpawnTimer>,
) {
// 如果时间未到 2s 就立即返回
if !timer.0.tick(time.delta()).finished() {
return;
}
commands
.spawn(SpriteBundle {
sprite: Sprite {
color: FOOD_COLOR,
..default()
},
..default()
})
.insert(Food)
.insert(Position {
x: (random::<f32>() * ARENA_WIDTH as f32) as i32,
y: (random::<f32>() * ARENA_HEIGHT as f32) as i32,
})
.insert(Size::square(0.8));
}
Timer 类型是Bevy提供的定时器类型,我们用newtype模式定义一个自己的定时器,它是一种资源(全局唯一)。我们使用 insert_resource() 将这个资源初始化并插入到托管系统中去。
然后在 food_spawner system 中使用 ResMut<FoodSpawnTimer> 这种形式来使用资源。同时用 Res<Time> 这种形式来获取游戏中的时间,这个也是Bevy引擎提供的。细心的你可能发现了,Bevy采用的也是声明式参数实现,和前面课程讲到的Axum风格一样。这些参数顺序是可以变的!在这里你可以体会到Rust强大的表达能力。
我们再来看一句。
if !timer.0.tick(time.delta()).finished() {
return;
}
这一句表示每次执行这个 food_spawner system(1秒执行60次)时,先判断当前流逝了多少时间,如果定时器的一次间隔还没到,就直接返回,不执行这个函数后面的部分,也就不产生一个食物了。这样就实现了控制食物产生速率的目的。
你可以看一下运行效果。
现在2秒产生一颗食物,速度比刚才慢多了。
第11步:让蛇自动前进
下面我们要让蛇自己动起来,而且也要控制它的运动速率。同样的我们会用定时器方法。
你来看这一步改动的代码。
#[derive(Resource)]
struct BTimer(Timer);
#[derive(Component)]
struct SnakeHead {
direction: Direction,
}
#[derive(PartialEq, Copy, Clone)]
enum Direction {
Left,
Up,
Right,
Down,
}
impl Direction {
fn opposite(self) -> Self {
match self {
Self::Left => Self::Right,
Self::Right => Self::Left,
Self::Up => Self::Down,
Self::Down => Self::Up,
}
}
}
// 插入定时器资源
.insert_resource(BTimer(Timer::from_seconds(
0.20,
TimerMode::Repeating,
)))
// 更新Update模式下的system集
.add_systems(Update, (
snake_movement_input.before(snake_movement),
snake_movement,
size_scaling,
position_translation))
// 根据用户键盘行为,预处理蛇的前进方向
fn snake_movement_input(
keyboard_input: Res<Input<KeyCode>>,
mut heads: Query<&mut SnakeHead>) {
if let Some(mut head) = heads.iter_mut().next() {
let dir: Direction = if keyboard_input.just_pressed(KeyCode::Left) {
Direction::Left
} else if keyboard_input.just_pressed(KeyCode::Down) {
Direction::Down
} else if keyboard_input.just_pressed(KeyCode::Up) {
Direction::Up
} else if keyboard_input.just_pressed(KeyCode::Right) {
Direction::Right
} else {
head.direction
};
if dir != head.direction.opposite() {
head.direction = dir;
}
}
}
// 蛇的运动system
fn snake_movement(
mut heads: Query<(&mut Position, &SnakeHead)>,
time: Res<Time>,
mut timer: ResMut<BTimer>,
) {
// 如果时间未到 0.2s 就立即返回
if !timer.0.tick(time.delta()).finished() {
return;
}
if let Some((mut head_pos, head)) = heads.iter_mut().next() {
match &head.direction {
Direction::Left => {
head_pos.x -= 1;
}
Direction::Right => {
head_pos.x += 1;
}
Direction::Up => {
head_pos.y += 1;
}
Direction::Down => {
head_pos.y -= 1;
}
};
}
}
类似地,我们定义了BTimer来控制蛇的自动行走,0.2秒走一格。同时,我们现在可以给蛇指定行走的方向了,因此新定义了 Direction 枚举,并在 SnakeHead Component里添加了 direction 字段。
代码中的 snake_movement_input.before(snake_movement) 表示明确指定 snake_movement_input 在 snake_movement system 之前处理。因为bevy默认会尽可能并行化,所以这样指定能够明确system的执行顺序,不然可能是乱序执行的。
第12步:定义蛇身
下面是定义蛇的身子,这是整个模型相对困难的一步。但其实把结构定义好了就会很简单。
你可以看一下这步变化的代码。
#[derive(Component)]
struct SnakeSegment;
#[derive(Resource, Default, Deref, DerefMut)]
struct SnakeSegments(Vec<Entity>);
// 插入蛇的结构,定义为资源
.insert_resource(SnakeSegments::default())
// 创建蛇,用SnakeSegments来维护蛇的结构
fn spawn_snake(mut commands: Commands, mut segments: ResMut<SnakeSegments>) {
*segments = SnakeSegments(vec![
commands
.spawn(SpriteBundle {
sprite: Sprite {
color: SNAKE_HEAD_COLOR,
..default()
},
..default()
})
.insert(SnakeHead {
direction: Direction::Up,
})
.insert(SnakeSegment)
.insert(Position { x: 3, y: 3 })
.insert(Size::square(0.8))
.id(),
spawn_segment(commands, Position { x: 3, y: 2 }),
]);
}
// 创建蛇的一个segment,也就是一个小方块
fn spawn_segment(mut commands: Commands, position: Position) -> Entity {
commands
.spawn(SpriteBundle {
sprite: Sprite {
color: SNAKE_SEGMENT_COLOR,
..default()
},
..default()
})
.insert(SnakeSegment)
.insert(position)
.insert(Size::square(0.65))
.id()
}
这里,最关键的是定义了 SnakeSegment Component 和 SnakeSegments(Vec<Entity>) 这个 Resource。我们把蛇的头和每一节身子小方块都视为一个 SnakeSegment,整条蛇由多个 SnakeSegment 组成,因此用 SnakeSegments(Vec<Entity>) 这个资源来维护这条蛇的结构。 SnakeSegments(Vec<Entity>) 里面需要存下每个 SnakeSegment 的 Entity id。
默认开始的时候,蛇有一节身子,位置在 (3, 2)。蛇的运动方向是向上的。蛇身小方块是 0.65 个网格单元大小。
你可以看一下这一步运行后的效果。
可以看到,这一节蛇身没有跟着头一起动。
第13步:让蛇身跟着蛇的头一起运动
让蛇身跟着蛇头一起动,模型上其实就是让蛇身的每一节跟着蛇头的移动一起变换坐标就行了。我们看一下这一步的代码变化。
fn snake_movement(
time: Res<Time>,
mut timer: ResMut<BTimer>,
segments: ResMut<SnakeSegments>,
mut heads: Query<(Entity, &SnakeHead)>,
mut positions: Query<&mut Position>,
) {
// 不到0.2s立即返回
if !timer.0.tick(time.delta()).finished() {
return;
}
if let Some((head_entity, head)) = heads.iter_mut().next() {
let segment_positions = segments
.iter()
.map(|e| *positions.get_mut(*e).unwrap())
.collect::<Vec<Position>>();
// 处理蛇的头的位移
let mut head_pos = positions.get_mut(head_entity).unwrap();
match &head.direction {
Direction::Left => {
head_pos.x -= 1;
}
Direction::Right => {
head_pos.x += 1;
}
Direction::Up => {
head_pos.y += 1;
}
Direction::Down => {
head_pos.y -= 1;
}
};
// 处理蛇身每一段的位置变化
segment_positions
.iter()
.zip(segments.iter().skip(1))
.for_each(|(pos, segment)| {
*positions.get_mut(*segment).unwrap() = *pos;
});
}
}
这个算法的精华在这一句:
segment_positions
.iter()
.zip(segments.iter().skip(1))
.for_each(|(pos, segment)| {
*positions.get_mut(*segment).unwrap() = *pos;
});
意思就是,当蛇动一步的时候,第一节蛇身的坐标值填充蛇头的坐标值,第二节蛇身的坐标值填充第一节蛇身的坐标值,以此类推,直到遍历完整个蛇身。
可以看到,Rust可以把问题表达得相当精练。
你看一下这一步运行后的效果。
第14步:边吃边长大
下面就该处理吃食物并长大的效果了。吃食物的原理就是当蛇头占据了那个食物的位置时,就在系统中注销掉那个食物,然后在蛇身的尾巴位置处添加一个小方块。
你看一下这一步变化的代码。
#[derive(Event)]
struct GrowthEvent;
#[derive(Default, Resource)]
struct LastTailPosition(Option<Position>);
// 更新Update system集合
.add_systems(Update, (
snake_movement_input.before(snake_movement),
snake_movement,
snake_eating,
snake_growth,
size_scaling,
position_translation))
*last_tail_position = LastTailPosition(Some(*segment_positions.last().unwrap()));
// 处理蛇吃食物的system
fn snake_eating(
mut commands: Commands,
mut growth_writer: EventWriter<GrowthEvent>,
food_positions: Query<(Entity, &Position), With<Food>>,
head_positions: Query<&Position, With<SnakeHead>>,
) {
for head_pos in head_positions.iter() {
for (ent, food_pos) in food_positions.iter() {
// 通过遍历来判断有没有吃到一个食物
if food_pos == head_pos {
commands.entity(ent).despawn();
growth_writer.send(GrowthEvent);
}
}
}
}
// 处理蛇长大的system
fn snake_growth(
commands: Commands,
last_tail_position: Res<LastTailPosition>,
mut segments: ResMut<SnakeSegments>,
mut growth_reader: EventReader<GrowthEvent>,
) {
// 通过事件机制来解耦蛇长大的逻辑
if growth_reader.read().next().is_some() {
segments.push(spawn_segment(commands, last_tail_position.0.unwrap()));
}
}
我们添加了 LastTailPosition(Option<Position>) 这个蛇尾的位置坐标作为资源来实时更新,好知道蛇长长的时候,应该在哪个位置添加segment。然后新增了 snake_eating 和 snake_growth 两个 system。
我们新定义了 GrowthEvent 长大的事件。
snake_eating system 处理吃食物的业务,就是当蛇头的位置与食物位置重合时,就调用 commands.entity(ent).despawn() 将食物给注销掉。然后用 growth_writer.send(GrowthEvent) 向系统总线发送一个“长大”的事件。
snake_growth system 处理蛇长大的业务,通过 EventReader<GrowthEvent> 定义的 growth_reader,读取系统中的长大事件,使用 spawn_segment() 和 segments.push() 把尾巴添加到蛇的全局维护资源中去。
snake_eating 和 snake_growth 在每一帧更新时都会执行。
可以看到,通过这样的事件总线,Bevy系统把业务解耦得相当漂亮。每个system就专注于处理一件“小”事情就行了。这样对于构建复杂的游戏系统来说,大大减轻了我们的心智负担。
你可以看一下这一步执行后的效果。
第15步:撞墙和自身Game Over
好了,我们的贪吃蛇的主体功能基本实现好了,下面需要加入撞墙和撞自身死的判断。你看一下这一步变化的代码。
#[derive(Event)]
struct GameOverEvent;
// 注册事件到world中
.add_event::<GameOverEvent>()
.add_systems(Update, (
snake_movement_input.before(snake_movement),
snake_movement,
game_over.after(snake_movement),
snake_eating,
snake_growth,
size_scaling,
position_translation))
// 判断撞墙的逻辑
if head_pos.x < 0
|| head_pos.y < 0
|| head_pos.x as u32 >= ARENA_WIDTH
|| head_pos.y as u32 >= ARENA_HEIGHT
{
game_over_writer.send(GameOverEvent);
}
// 判断撞自己身子的逻辑
if segment_positions.contains(&head_pos) {
game_over_writer.send(GameOverEvent);
}
//
// game over 子system
fn game_over(
mut commands: Commands,
mut reader: EventReader<GameOverEvent>,
segments_res: ResMut<SnakeSegments>,
food: Query<Entity, With<Food>>,
segments: Query<Entity, With<SnakeSegment>>,
) {
if reader.read().next().is_some() {
for ent in food.iter().chain(segments.iter()) {
commands.entity(ent).despawn();
}
spawn_snake(commands, segments_res);
}
}
撞墙这个只需要判断有没有超出grid边界就可以了。撞自身判断用 segment_positions.contains(&head_pos) 看所有蛇身的 segment 的position Vec里有没有包含蛇头的位置。
我们添加了 GameOverEvent 事件和 game_over system,也是用的异步事件的方式。当收到 GameOverEvent 的时候,把所有的蛇的entity和食物的entity全部清理(despawn)掉。注意这里用了两个迭代器的 .chain() 方法,让清理工作表达得更紧凑,你可以体会一下。
清理完后,再重新创建蛇,游戏重新开始。到这一步,游戏已经基本能玩了,还写什么代码,先玩几把吧。
目前为止,整个代码不过330行左右。
小结
这节课我们通过自己动手编写一个贪吃蛇小游戏,学习了Rust游戏开发引擎Bevy的基本使用方式。Bevy游戏引擎充分利用Rust语言的无忧并发和强大的表达能力,让开发游戏变得跟游戏一样好玩。整个过程下来,心情愉快、舒畅。你可以跟着我一步一步敲代码,体会这种感觉。
Bevy的核心是一套ECS系统,ECS本质上来说是一套编程范式,不仅限于在游戏中使用,它也可以在其他的业务系统中使用。你有必要多花点时间查阅相关资料去理解它。后面有机会我也会继续出相关的研究内容。
写Bevy代码的时候,我们要理解Bevy是一种Runtime,我们写的代码实际会被这个Runtime托管运行。我们要做的就是按照ECS规范定义Component、Resource、Event等,实现 system 添加到这个 Runtime 中。底层那些脏活累活Bevy全帮我们做了,我们只需要专心抽象模型、定义结构、处理业务。
然后,通过这节课的内容我们可以体会到,写小游戏其实也是一种相当好的建模能力的训练,我们可以通过这种有趣的方法提升自己在这方面的能力。
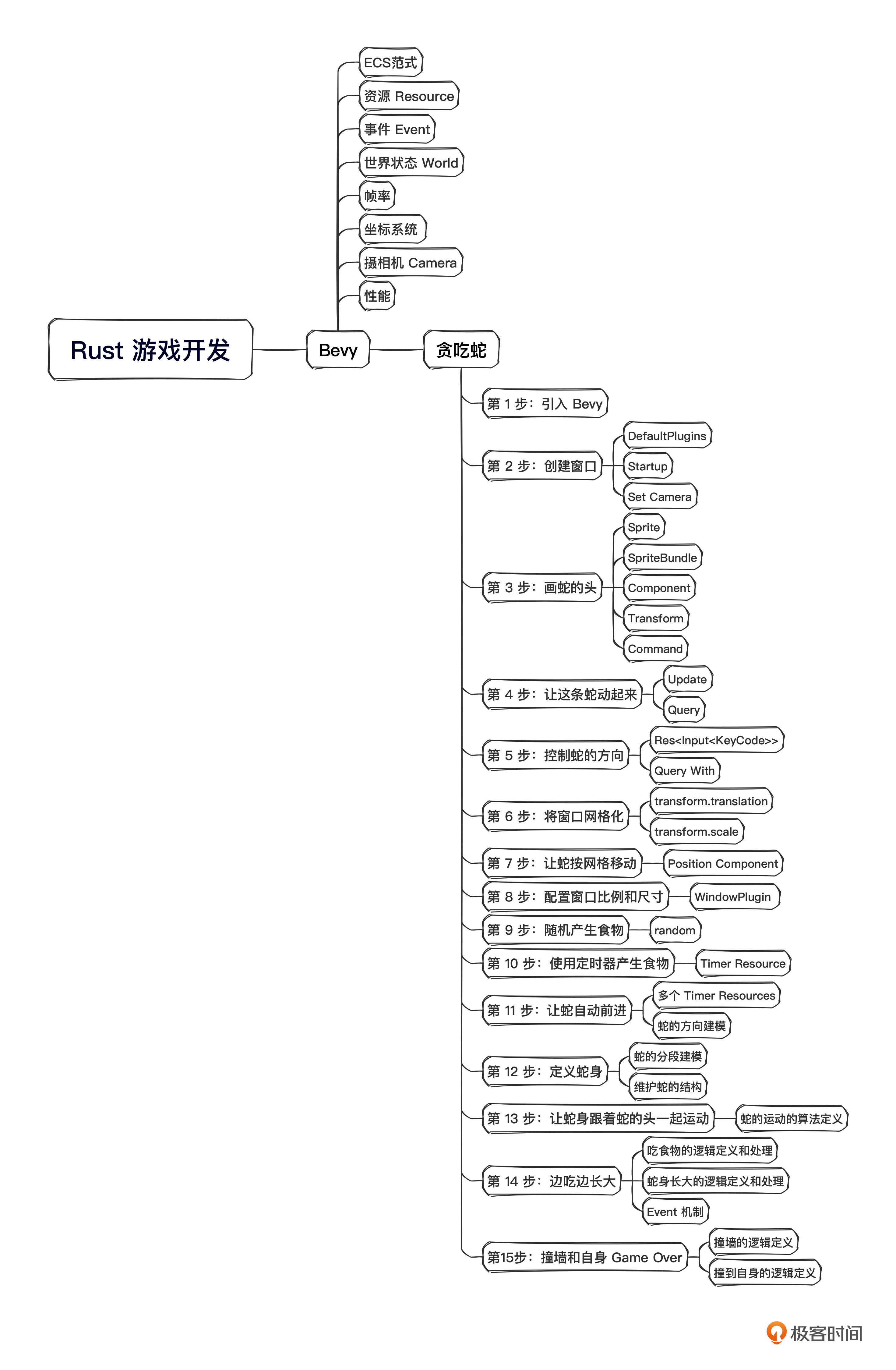
本讲源代码: https://github.com/miketang84/jikeshijian/tree/master/27-bevy_snake
必读的两个Bevy资料:
思考题
这节课的代码还有个问题,就是食物有可能在已经产生过的地方产生,也有可能在蛇身上产生,请问如何处理这个Bug?欢迎你把你的处理思路和实现代码分享出来,我们一起探讨,如果你觉得这节课对你有帮助的话,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
Nom:用Rust写一个Parser解析器
你好,我是Mike。今天我们来一起学习如何用Rust写一个Parser解析器。
说到解析器,非计算机科班出身的人会一脸懵,这是什么?而计算机科班出身的人会为之色变,曾经熬夜啃“龙书”的痛苦经历浮现眼前。解析器往往跟“编译原理”这个概念一起出现,谈解析器色变完全可以理解。
实际上,解析器也没那么难,并不是所有需要“解析”的地方都与编程语言相关。因此我们可以先把“编译原理”的负担给卸掉。在开发过程中,其实经常会碰到需要解析的东西,比如自定义配置文件,从网络上下载下来的一些数据文件、服务器日志文件等。这些其实不需要很深的背景知识。更加复杂一点的,比如网络协议的处理等等,这些也远没有达到一门编程语言的难度。
另一方面,虽然我们这门课属于入门级,但是对于未来的职业规划来说,如果你说你能写解析器,那面试官可能会很感兴趣。所以这节课我会从简单的示例入手,让你放下恐惧,迈上“解析”之路。
解析器是什么?
解析器其实很简单,就是把一个字符串或字节串解析成某种类型。对应的,在Rust语言里就是把一个字段串解析成一个Rust类型。一个Parser其实就是一个Rust函数。
这个转换过程有很多种方法。
- 最原始的是完全手撸,一个字符一个字符吞入解析。
- 对一些简单情况,直接使用String类型中的find、split、replace等函数就可以。
- 用正则表达式能够解析大部分种类的文本。
- 还可以用一些工具或库帮助解析,比如Lex、Yacc、LalrPop、Nom、Pest等。
- Rust语言的宏也能用来设计DSL,能实现对DSL文本的解析。
这节课我们只关注第4点。在所有辅助解析的工具或库里,我们只关心Rust生态辅助解析的库。
Rust生态中主流的解析工具
目前Rust生态中已经有几个解析库用得比较广泛,我们分别来了解下。
- LalrPop 类似于Yacc,用定义匹配规则和对应的行为方式来写解析器。
- Pest 使用解析表达式语法(Parsing Expression Grammar,PEG)来定义解析规则,PEG已经形成了一个成熟的标准,各种语言都有相关的实现。
- Nom是一个解析器组合子(Parser-Combinator)库,用函数组合的方式来写规则。一个Parser就是一个函数,接收一个输入,返回一个结果。而组合子combinator也是一个函数,用来接收多个Parser函数作为输入,把这些小的Parser组合在一起,形成一个大的Parser。这个过程可以无限叠加。
Nom库介绍
这节课我们选用Nom库来讲解如何快速写出一个解析器,目前(2023年12月)Nom库的版本为 v7.1。选择Nom的原因是,它可以用来解析几乎一切东西,比如文本协议、二进制文件、流数据、视频编码数据、音频编码数据,甚至是一门完整功能的编程语言。
Nom 的显著特性在安全解析、便捷的解析过程中的错误处理和尽可能的零拷贝上。因此用Nom解析库写的代码是非常高效的,甚至比你用C语言手撸一个解析器更高效,这里有一些 评测 你可以参考。Nom能够做到这种程度主要是因为站在了Rust的肩膀上。
解析器组合子是一种解析方法,这种方法不同于PEG通过写单独的语法描述文件的方式进行解析。Nom的slogan是“nom, eating data byte by byte”,也就是一个字节一个字节地吞,顺序解析。
使用Nom你可以写特定目的的小函数,比如获取5个字节、识别单词HTTP等,然后用有意义的模式把它们组装起来,比如识别 'HTTP',然后是一个空格、一个版本号,也就是 'HTTP 1.1' 这种形式。这样写出的代码就非常小,容易起步。并且这种形式明显适用于流模式,比如网络传输的数据,一次可能拿不完,使用Nom能够边取数据边解析。
解析器组合子思路有5个优势。
- 解析器很小,很容易写。
- 解析器的组件非常容易重用。
- 解析器的组件非常容易用单元测试进行独立测试。
- 解析器组合的代码看起来接近于你要解析的数据结构,非常直白。
- 你可以针对你当前的特定数据,构建部分解析器,而不用关心其他数据部分。
Nom的工作方式
Nom的解析器基本工作方式很简单,就是读取输入数据流,比如字符串,返回 (rest, output) 这样一个tuple,rest就是没有解析到的字符串的剩余部分,output就是解析出来的目标类型。很多时候,这个返回结果就是(&str, &str)。解析过程中,可以处理解析错误。
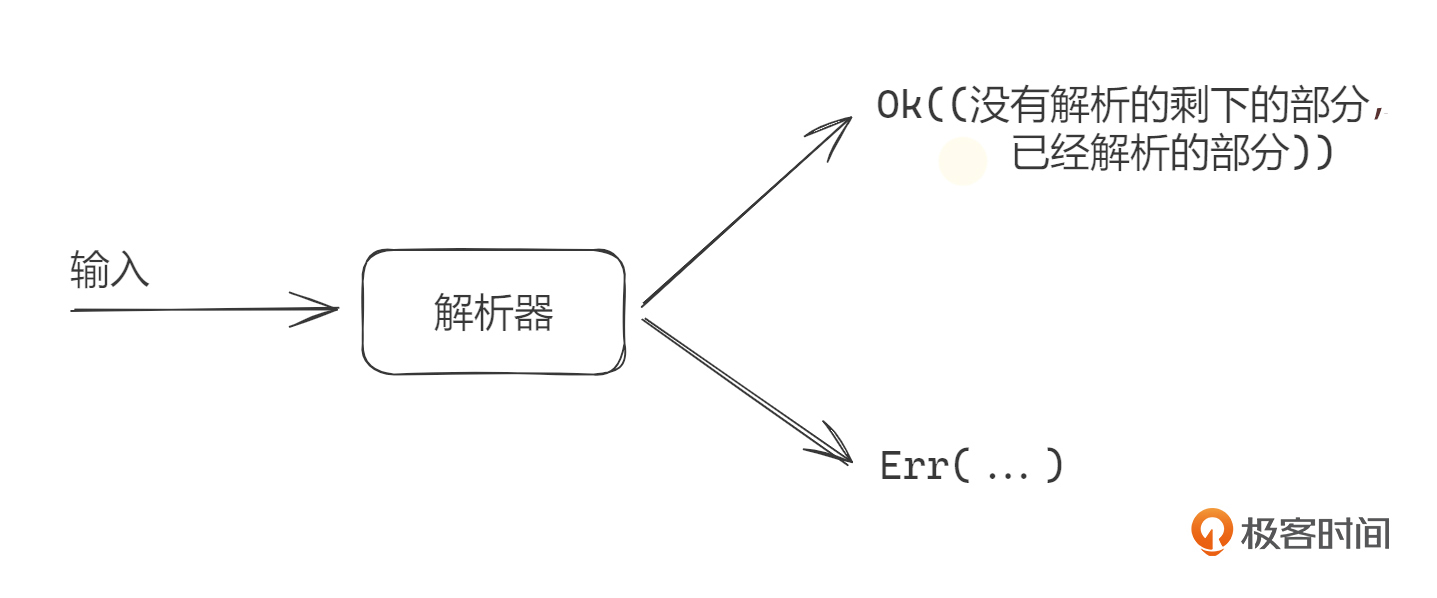
基本解析器和组合子
在Nom中,一个Parser其实就是一个函数。Nom提供了一些最底层的Parser。相当于构建房屋的砖块,我们掌握了这些砖块后,就可以把这些砖块组合使用,像乐高积木,一层层越搭越高。
这里我们列举一些常用的解析器,案例基本上都是对字符串的解析。
Tag
tag非常常用,用来指代一个确定性的字符串,比如 “hello”。
- tag:识别一个确定性的字符串。
- tag_no_case:识别一个确定性的字符串,忽略大小写。
基本类别解析器
下面是Nom提供的用来识别字符的基本解析器,可以看到,都是我们熟知的解析器。
- alpha0:识别 a-z, A-Z 中的字符 0 个或多个。
- alpha1:识别 a-z, A-Z 中的字符 1 个或多个(至少1个)。
- alphanumeric0:识别 0-9, a-z, A-Z 中的字符 0 个或多个。
- alphanumeric1:识别 0-9, a-z, A-Z 中的字符 1 个或多个(至少1个)。
- digit0:识别 0-9 中的字符 0 个或多个。
- digit1:识别 0-9 中的字符 1 个或多个(至少1个)。
- hex_digit0:识别 0-9, A-F, a-f 中的字符 0 个或多个。
- hex_digit1:识别 0-9, A-F, a-f 中的字符 1 个或多个(至少1个)。
- space0:识别 空格和tab符 \t 0 个或多个。
- space1:识别 空格和tab符 \t 0 个或多个(至少1个)。
- multispace0:识别 空格、tab符 \t 、回车符 \r、换行符\n, 0 个或多个。
- multispace1:识别 空格、tab符 \t 、回车符 \r、换行符\n, 1 个或多个(至少1个)。
- tab:识别确定的制表符 \t。
- newline:识别确定的换行符 \n。
- line_ending:识别 ‘\n’ 和‘\r\n’。
- not_line_ending:识别 ‘\n’ 和‘\r\n’之外的其他字符(串)。
- one_of:识别给定的字符集合中的一个。
- none_of:识别给定的字符集合之外的字符。
完整的列表请看这里: https://docs.rs/nom/latest/nom/character/complete/index.html
基本组合子
- alt:Try a list of parsers and return the result of the first successful one或组合子,满足其中的一个解析器就可成功返回。
- tuple:和组合子,并且按顺序执行解析器,并返回它们的值为一个tuple。
- delimited:解析左分界符目标信息右分界符这种格式,比如
"{ ... }",返回目标信息。 - pair:tuple的两元素版本,返回一个二个元素的 tutple。
- separated_pair:解析目标信息分隔符目标信息这种格式,比如
"1,2"这种,返回一个二个元素的 tutple。 - take_while_m_n:解析最少m个,最多n个字符,这些字符要符合给定的条件。
更多Nom中的解析器和组合子的信息请查阅 Nom 的 API。
Nom实战
我们从最简单的解析器开始。
0号解析器
0号解析器就相当于整数的0,这是一个什么也干不了的解析器。
use std::error::Error; use nom::IResult; pub fn do_nothing_parser(input: &str) -> IResult<&str, &str> { Ok((input, "")) } fn main() -> Result<(), Box<dyn Error>> { let (remaining_input, output) = do_nothing_parser("abcdefg")?; assert_eq!(remaining_input, "abcdefg"); assert_eq!(output, ""); Ok(()) }
上面的 do_nothing_parser() 函数就是一个Nom的解析器,对,就是一个普通的Rust函数,它接收一个 &str 参数,返回一个 IResult<&str, &str>,IResult<I, O> 是 Nom 定义的解析器的标准返回类型。你可以看一下它的 定义。
pub type IResult<I, O, E = Error<I>> = Result<(I, O), Err<E>>;
可以看到,正确返回情况下,它的返回内容是 (I, O),一个元组,元组第一个元素是剩下的未解析的输入流部分,第二个元素是解析出的内容。这正好对应 do_nothing_parser() 的返回内容 (input, "")。这里是原样返回,不做任何处理。
注意, E = Error<I> 这种写法是类型参数的默认类型,请回顾课程 第 10 讲 找到相关知识点。
看起来这个解析器没有啥作用,但不可否认,它让我们直观感受了Nom中的parser是个什么东西,我们已经有了基本模板。
1号解析器
这次我们必须要做点什么事情了,那就把 "abcedfg" 的前三个字符识别出来。我们需要用到 tag 解析器。代码如下:
pub use nom::bytes::complete::tag; pub use nom::IResult; use std::error::Error; fn parse_input(input: &str) -> IResult<&str, &str> { tag("abc")(input) } fn main() -> Result<(), Box<dyn Error>> { let (leftover_input, output) = parse_input("abcdefg")?; assert_eq!(leftover_input, "defg"); assert_eq!(output, "abc"); assert!(parse_input("defdefg").is_err()); Ok(()) }
在这个例子里, tag("abc") 的返回值是一个 parser,然后这个parser再接收 input 的输入,并返回 IResult<&str, &str>。前面的我们看到,tag识别固定的字符串/字节串。
tag实际返回一个闭包,你可以看一下它的定义。
pub fn tag<T, Input, Error: ParseError<Input>>(
tag: T
) -> impl Fn(Input) -> IResult<Input, Input, Error>
where
Input: InputTake + Compare<T>,
T: InputLength + Clone,
也就是返回下面这行内容。
impl Fn(Input) -> IResult<Input, Input, Error>
这里这个 Fn 就是用于描述闭包的 trait,你可以回顾一下课程 第 11 讲 中关于它的内容。
这个示例里 parse_input("abcdefg")? 这个解析器会返回 ("defg", "abc"),也就是把 "abc" 解析出来了,并返回了剩下的 "defg"。而如果在待解析输入中找不到目标pattern,那么就会返回Err。
解析一个坐标
下面我们再加大难度,解析一个坐标,也就是从 "(x, y)" 这种形式中解析出x和y两个数字来。
代码如下:
use std::error::Error; use nom::IResult; use nom::bytes::complete::tag; use nom::sequence::{separated_pair, delimited}; #[derive(Debug,PartialEq)] pub struct Coordinate { pub x: i32, pub y: i32, } use nom::character::complete::i32; // 解析 "x, y" 这种格式 fn parse_integer_pair(input: &str) -> IResult<&str, (i32, i32)> { separated_pair( i32, tag(", "), i32 )(input) } // 解析 "( ... )" 这种格式 fn parse_coordinate(input: &str) -> IResult<&str, Coordinate> { let (remaining, (x, y)) = delimited( tag("("), parse_integer_pair, tag(")") )(input)?; Ok((remaining, Coordinate {x, y})) } fn main() -> Result<(), Box<dyn Error>> { let (_, parsed) = parse_coordinate("(3, 5)")?; assert_eq!(parsed, Coordinate {x: 3, y: 5}); let (_, parsed) = parse_coordinate("(2, -4)")?; assert_eq!(parsed, Coordinate {x: 2, y: -4}); // 用nom,可以方便规范地处理解析失败的情况 let parsing_error = parse_coordinate("(3,)"); assert!(parsing_error.is_err()); let parsing_error = parse_coordinate("(,3)"); assert!(parsing_error.is_err()); let parsing_error = parse_coordinate("Ferris"); assert!(parsing_error.is_err()); Ok(()) }
我们从 parse_coordinate() parser 看起。首先遇到的是 delimited 这个 combinator,它的作用我们查一下上面的表格,是解析左分界符目标信息右分界符这种格式,返回目标信息,也就是解析 (xxx), <xxx>, {xxx} 这种前后配对边界符的pattern,正好可以用来识别我们这个 (x, y),我们把 "(x, y)" 第一步分解成 "(", "x, y", ")" 三部分,用 delimited 来处理。同样的,它也返回一个解析器闭包。
然后,对于中间的这部分 "x, y",我们用 parse_integer_pair() 这个 parser 来处理。继续看这个函数,它里面用到了 separated_pair 这个 combinator。查一下上面的表,你会发现它是用来处理左目标信息分隔符右目标信息这种pattern的,刚好能处理我们的 "x, y"。中间那个分隔符就用一个 tag(", ") 表示,两侧是 i32 这个parser。注意,这里这个 i32 是代码中引入的。
use nom::character::complete::i32;
不是Rust std中的那个i32,它实际是Nom中提供的一个parser,用来把字符串解析成 std 中的 i32 数字。 separated_pair 也返回一个解析器闭包。可以看到,返回的闭包调用形式和 delimited 是一样的。其实整个Nom解析器的签名都是固定的,可以以这种方式无限搭积木。
parse_integer_pair 就返回了 `(x, y) 两个i32数字组成的元组类型,最后再包成 Coordinate 结构体类型返回。整个任务就结束了。
可以看到,这实际就是标准的 递归下降 解析方法。先识别大pattern,分割,一层层解析小pattern,直到解析到最小单元为止,再组装成需要的输出类型,从函数中一层层返回。整个过程就是普通的Rust函数栈调用过程。
解析16进制色彩编码
下面我们继续看一个示例:解析网页上的色彩格式 #2F14DF。
对于这样比较简单的问题,手动用String的方法分割当然可以,用正则表达式也可以。这里我们来研究用Nom怎样做。
use nom::{
bytes::complete::{tag, take_while_m_n},
combinator::map_res,
sequence::Tuple,
IResult,
};
#[derive(Debug, PartialEq)]
pub struct Color {
pub red: u8,
pub green: u8,
pub blue: u8,
}
fn from_hex(input: &str) -> Result<u8, std::num::ParseIntError> {
u8::from_str_radix(input, 16)
}
fn is_hex_digit(c: char) -> bool {
c.is_digit(16)
}
fn hex_primary(input: &str) -> IResult<&str, u8> {
map_res(take_while_m_n(2, 2, is_hex_digit), from_hex)(input)
}
fn hex_color(input: &str) -> IResult<&str, Color> {
let (input, _) = tag("#")(input)?;
let (input, (red, green, blue)) = (hex_primary, hex_primary, hex_primary).parse(input)?;
Ok((input, Color { red, green, blue }))
}
#[test]
fn parse_color() {
assert_eq!(
hex_color("#2F14DF"),
Ok((
"",
Color {
red: 47,
green: 20,
blue: 223,
}
))
);
}
执行 cargo test,输出 :
running 1 test
test parse_color ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
我们来详细解释这个文件。
代码从 hex_color 入手,输入就是 "#2F14DF" 这个字符串。
let (input, _) = tag("#")(input)?;
这句执行完,返回的 input 变成 "2F14DF"。
接下来就要分析三个 16 进制数字,两个字符一组。
(hex_primary, hex_primary, hex_primary).parse(input)?;
我们在元组上直接调用了 .parse() 函数。这是什么神奇的用法?别慌,你在std标准库文档里面肯定找不到,实现在 这里。它将常用的元组变成了parser。但是这样的实现需要手动调用一下 .parse() 函数来执行解析。
这里我们意图就是把颜色解析成独立的三个元素,每种元素是一个16进制数,这个16进制数进一步用 hex_primary 来解析。我们再来看 hex_primary 的实现。
map_res(
take_while_m_n(2, 2, is_hex_digit),
from_hex
)(input)
其中,代码第二行表示在input中一次取2个字符(前面两个参数2,2,表示返回不多于2个,不少于2个,因此就是等于2个),取出每个字符的时候,都要判断是否是16进制数字。是的话才取,不是的话就会返回Err。
map_res 的意思是,对 take_while_m_n parser 返回的结果应用一个后面提供的函数,这里就是 from_hex,它的目的是把两个16进制的字符组成的字符串转换成10进制数字类型,这里就是u8类型。因此 hex_primary 函数返回的结果是 IResult<&str, u8>。 u8::from_str_radix(input, 16) 是 Rust std 库中的u8类型的自带方法,16表示16进制。
let (input, (red, green, blue)) = (hex_primary, hex_primary, hex_primary).parse(input)?;
因此这一行,正常返回后,input就为 "" 了, (red, green, blue) 这三个是u8类型的三元素tuple,实际这里相当于定义了red、green、blue三个变量。
然后下面一行,就组装成 Color 对象返回了,目标完成。
Ok((input, Color { red, green, blue }))
更多示例
前面我们说过,Nom非常强大,可应用领域非常广泛,这里有一些链接,你有兴趣的话,可以继续深入研究。
- 解析HTTP2协议: https://github.com/sozu-proxy/sozu/blob/main/lib/src/protocol/h2/parser.rs
- 解析flv文件: https://github.com/rust-av/flavors/blob/master/src/parser.rs,你还可以对照C实现体会Nom的厉害之处: https://github.com/FFmpeg/FFmpeg/blob/master/libavformat/flvdec.c。
- 解析 Python 代码: https://github.com/progval/rust-python-parser
- 自己写一个语言: https://github.com/Rydgel/monkey-rust
小结
这节课我们学习了如何用Nom解决解析器任务。在计算机领域,需要解析的场景随处可见,以前的 lexer、yacc 等套路其实已经过时了,Rust的Nom之类的工具才是业界最新的成果,你掌握了 Nom等工具,就能让这类工作轻松自如。
我们需要理解Nom这类解析器库背后的 解析器-组合子 思想,它是一种通用的解决复杂问题的构建方法,也就是递归下降分解问题,从上到下分割任务,直到问题可解决为止。然后先解决基本的小问题,再把这些成果像砖块那样组合起来,于是便能够解决复杂的系统问题。
可以看到,Nom的学习门槛其实并不高,其中很关键的一点是学完一部分就能应用一部分,不像其他有些框架,必须整体学完后才能应用。一旦你通过一定的时间掌握了Nom的基本武器零件后,就会收获到一项强大的新技能,能够让你在以后的工作中快速升级,解决你以前不敢去解决的问题。
这节课你应该也能感受到Rust打下的扎实基础(安全编程、高性能等),Rust生态已经构建出强大框架和工具,这些框架和工具能够让我们达到前所未有的生产力水平,已经完全不输于甚至超过其他编程语言了。
这节课所有可运行代码在这里: https://github.com/miketang84/jikeshijian/tree/master/28-nom
思考题
请尝试用Nom解析一个简单版本的CSV格式文件。欢迎你把你解析的内容分享出来,我们一起看一看,如果你觉得这节课对你有帮助的话,也欢迎你分享给其他朋友,我们下节课再见!
Unsafe编程(上): Unsafe Rust中那些被封印的能力
你好,我是Mike。
这门课目前已接近尾声,剩下的两节课我准备讲讲Rust中看起来有点黑魔法的部分——Unsafe Rust。这一节课我们先来聊聊相关的概念。
在前面课程的学习中,你有没有感觉到,Rust编译器就像是一个严厉的大师傅,或者一个贴心的小助手,在你身边陪你结对编程,你写代码的时候,他盯着屏幕,时不时提醒你。如果某个时刻,这个大师傅或小助手突然离开了,你会不会慌?就像刚提车,第一次独自上路的那种感觉。
三个王国
Unsafe Rust 就是这样一个领域,进入这个领域,你突然拥有了几种必杀技能,但是身边已经没有大师傅同行了,只能靠你自己完全控制这几种技能的使用。使用得好,威力无穷。使用不好,对自己也会造成巨大伤害。Unsafe Rust就是这样一个相对独立的领域。前面我们讲到过,Async Rust也是相对独立的一个附属王国,现在又多了一个Unsafe Rust这样的附属王国。
Rust语言可以看作是这三块疆域的合体,它们共同组成了一个联盟Rust王国。你甚至可以把Rust语言看成包含上面三种编程语言的一种混合语言。所以很多人抱怨Rust难学,也是可以理解的。
现在让我们把注意力集中在Unsafe Rust这个王国里面。它到底是什么样的?简单地说,你可以把它理解成这个王国里面住着一个C语言族的国王。也就是说,C语言能做的事情,Unsafe Rust都能做。C语言能做哪些事情呢?理论上来说,它能做计算机中的任何事情。因此,在Unsafe Rust中,你也能做计算机中的任何事情。C的强大威力来源于它锋利的指针,而在Unsafe Rust中也提供了这种能力。
被封印的能力
Safe Rust王国有些技能被封印了,而这些技能进入到Unsafe Rust王国后,就可以被揭开使用。具体来说,有5种技能。
- 解引用原始指针
- 调用unsafe函数或方法
- 访问或修改可变的静态变量
- 实现一个unsafe trait
- 访问 union 中的字段
这里我们简单提一下这5个方面,我们从第5点讲起。union我们在课程里没有讲,这里我们简单了解下。它是一个类似于C中union的设计,也就是所有字段共同占有同一块存储空间。访问它的字段时,需要在 Unsafe Rust 中使用。
union IntOrFloat {
i: u32,
f: f32,
}
let mut u = IntOrFloat { f: 1.0 };
// 读取union字段时需要用 unsafe {} 包起来
assert_eq!(unsafe { u.i }, 1065353216);
// 更新了i,结果f字段的值也变化了。
u.i = 1073741824;
assert_eq!(unsafe { u.f }, 2.0);
我们一般用不到 union,如果需要深入研究,可以查看我给出的 链接。
第4点,我们可以给 trait 实现 unsafe,这块内容比较深,所以在我们这门初级课程里不要求了解,如果你有兴趣可以查看我给出的 链接。
第3点也就是全局静态变量,前面我不提倡修改它,因为它是一种不太好的编程模型。但是如果你非要改的话,也是有办法的,那就留下足迹,加个 unsafe {} 套起来,比如 the book 里的 示例。
// 这里修饰为 mut static mut COUNTER: u32 = 0; fn add_to_count(inc: u32) { // 修改全局可变静态变量需要用 unsafe unsafe { COUNTER += inc; } } fn main() { add_to_count(3); // 访问全局可变静态变量也需要用 unsafe unsafe { println!("COUNTER: {}", COUNTER); } } // 输出 COUNTER: 3
下面我来重点讲解一下前2种场景。
unsafe关键字
Rust中有一个 unsafe 关键字,用来显式地标明我们要进入 unsafe Rust 的领地。unsafe 关键字可以修饰 fn、trait,还可以在后面跟一个 {} 表明这是一个 unsafe 块,把可能不安全的逻辑包起来,像下面这样:
unsafe {
//...
}
这里,需要说明一下,被 unsafe 标识或包起来的代码,并不是说一定有问题。它的准确意思是: Rustc编译器不保证被unsafe标识的代码是安全的,你应该保证你写的代码是安全的。
也就是说,unsafe 这个标识符,在代码中留下了明确的足迹,将交由Rustc全权保证安全的代码,和不交由Rustc全权保证安全的代码,分隔开了。
请注意上面这句话的用词,“不交由Rustc全权保证安全的代码部分”并不是说Rustc编译器就完全不检查 unsafe 里的代码了,实际Rustc只是对上面提到的5种技能不加检查。对于Safe Rust里的内容还是要做检查,跟之前一样。我们来看一个示例。
fn main() { let v = [1,2,3]; unsafe { println!("COUNTER: {}", v[3]); } } // 编译输出 warning: unnecessary `unsafe` block --> src/main.rs:4:5 | 4 | unsafe { | ^^^^^^ unnecessary `unsafe` block | = note: `#[warn(unused_unsafe)]` on by default error: this operation will panic at runtime --> src/main.rs:5:33 | 5 | println!("COUNTER: {}", v[3]); | ^^^^ index out of bounds: the length is 3 but the index is 3
示例中,我们需要重点关注 array 的下标索引越界的问题。我们在 第 1 讲 里已经讲过,array的下标索引越界会在编译期被检查出来,可以看到,即使放在 unsafe block 中,它仍然执行了检查。这印证了我们上面的说法: 被 unsafe 标识的代码,并不是让Rustc完全不管,而只是某几种技能让Rustc不管。Safe Rust中的那些元素,Rustc该管的还是要管。
所以即使是Unsafe Rust,看上去也要比写 C 代码来得“安全”,犯错的风险更小一些。另外编译器指出这里 unsafe 块没什么用,可以去掉,我们确实没使用它。
原始指针
Rust中有两种原始指针(raw pointer), *const T 和 *mut T。用法如下:
fn main() { let my_num: i32 = 10; let my_num_ptr: *const i32 = &my_num; let mut my_speed: i32 = 88; let my_speed_ptr: *mut i32 = &mut my_speed; unsafe { println!("my_num is: {}", *my_num_ptr); println!("my_speed is: {}", *my_speed_ptr); } } // 输出 my_num is: 10 my_speed is: 88
也就是可以将不可变引用 &T 转换成 *const T 指针。将可变引用 &mut T 转换成 *mut T 指针。你也可以用 as 操作符 来转换。
之前我们讲过,引用是必须有效的指针,而指针不一定是引用,在这里就得到了充分的体现。原始指针指向的数据不对的话,解引用有可能会导致段错误或其他未定义行为。因此引用转换为原始指针的时候,不需要包unsafe,解引用原始指针的时候,要用unsafe包起来。这就是我们上面说的那5种被封印的能力中的第一种能力: 在 unsafe Rust 中,可以解引用原始指针。
一旦接触到了原始指针,也就开启了计算机底层系统的大门。你可以看我放在这里的两个链接,感受一下原始指针的复杂性。
Box<T> 转成原始指针
Box<T> 是带所有权的智能指针,它有一个 into_raw() 函数可以转换成原始指针。这个转换对于内存里的资源没有影响。但是要再从raw pointer转回Box就要放在 unsafe 里包起来, Box::from_raw() 是 unsafe 的。
fn main() { let my_speed: Box<i32> = Box::new(88); let my_speed: *mut i32 = Box::into_raw(my_speed); unsafe { let _ = Box::from_raw(my_speed); } }
这实际上也是对原始指针解引用的一个变形,所以要放在 unsafe 块里。
null指针
之前我们说过,Rust中不存在null/nil值,所有的变量都必须初始化。这在Safe Rust里是正确的。但是在Unsafe Rust中,却提供了null指针的表示。
可以用 std::ptr 里的 null() 和 null_mut() 生成两种原始空指针。
fn main() { use std::ptr; let p: *const i32 = ptr::null(); assert!(p.is_null()); let p: *mut i32 = ptr::null_mut(); assert!(p.is_null()); }
Rust中为什么会有空指针存在?有什么作用呢?那是因为C语言中有空指针这个东西。为了与C打交道,Rust中要有对应的设计,好与C库或者C应用程序对接,毕竟在Rust出来之前,C/C++ 已经建成了这个软件世界的地基。
Safe与Unsafe的边界
在Rust中,unsafe函数必须在 unsafe 函数中调用,或使用 unsafe {} 块包起来调用。因此下面的代码是可以的:
fn foo() { let my_num_ptr = &10 as *const i32; let my_speed_ptr = &mut 88 as *mut i32; unsafe { println!("my_num is: {}", *my_num_ptr); println!("my_speed is: {}", *my_speed_ptr); } } fn main() { foo(); }
可以看到, foo() 函数中包含了 unsafe 块的调用。但是从 main() 函数的角度来看,它调用 foo() 时不需要在外面再套一层 unsafe {} 来调用了。这里实际体现了重要的一点, Unsafe 与 Safe 的边界。示例代码里两者的边界就在 foo() 函数中。
从 main() 的视角来看,它调用的 foo() 有可能是第三方库暴露出来的接口,并不知道里面具体的实现,只知道这个函数可以按Safe Rust的形式安全调用。这里的这个 foo() 就是 对unsafe代码的safe封装。
我们再来看一个实际一点的例子。
use std::slice; fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) { let len = values.len(); let ptr = values.as_mut_ptr(); assert!(mid <= len); unsafe { ( slice::from_raw_parts_mut(ptr, mid), slice::from_raw_parts_mut(ptr.add(mid), len - mid), ) } } fn main() { let mut vector = vec![1, 2, 3, 4, 5, 6]; let (left, right) = split_at_mut(&mut vector, 3); }
上面函数将一个 i32 数组的 slice 可变引用分成了前后两段slice可变引用。这在 Safe Rust 是做不到的,因为同时对原数组存在了两个可变引用,详情请看 官方书。
在Unsafe Rust中可以做到,但是 slice::from_raw_parts_mut() 只能用 unsafe {} 包起来调用。而对业务开发者来说,在 main() 函数中以Safe Rust的形式直接使用 split_at_mut() 就行了,一切就好像 split_at_mut() 是真正safe的一样。在这里,它确实是safe的,只不过这个safe不是由Rustc来保证的safe,而是由我们程序员自己保证的safe。我们知道我们在干什么,两个 slice 并不重叠,不会有问题。
如果打破砂锅问到底的话,是不是几乎所有的Rust底层都有这个问题?跟踪到最底层代码的话,是不是都是 unsafe 的?如果是,那么Rust所标榜的 safe,岂不是一个虚幻的空中楼阁?
你的猜测大体是正确的。
极小化Unsafe层
从本质来说,世界是建立在unsafe上面的。
从硬件来说,我们编写程序来操作各种设备,内存、硬盘、显卡、网络设备等等,对它们的操作完全有可能是不安全的,这个错误可能来自各种层次,比如电源波动引起的故障、线路老化故障、晶体管损坏故障,甚至是太阳黑子爆发引起的故障等等。
从软件指令来说,当代码编译成二进制后,这个二进制可执行序列的威力是无穷大的,理论上可以对计算机内存和设备地址做任意访问,这也是hack行为的源头。只要hacker找到了你程序中的漏洞,它就可能在你的计算机中做任何危险的事情。这就是C这种靠指针吃饭的语言强大且危险的原因。
不管是从硬件层面还是软件层面,你的一个操作完全可能会得到一个未知的行为或未定义行为 Undefined Behaviour。 从Safe Rust的观点来看,一个会产生未定义行为的操作,就是Unsafe的。而unsafe的操作,都必须明确地放在 unsafe {} 块中隔离。
因此,在Safe Rust看来,威力过大的技能,比如原始指针的解引用,可能访问到未初始化的地址,或者是已经释放后的地址,因此它是Unsafe的;外部的C/C++代码,它们都得靠程序员自己来保证安全性,因此它们是不可信任的,把它们都归类到 Unsafe 中;对外部设备的操作,已经超过内存资源的管理权限了,Rust自己鞭长莫及,因此把它归为不信任,归类到 Unsafe 中。
于是我们可以看到,Rust将所有代码分割成了 Safe 的和 Unsafe的两块,两块之间就通过明确的 unsafe {} 标识来隔离,这是Rust的基本世界观。
在这个世界观之上,基于Rust的软件体系还有一套抽象哲学——当需要Unsafe时,应该把它封装在一个极小层(minimalist layer),然后在它的上面建立上层建筑。
也就是说,如果不得不用Unsafe代码,那请封装尽量薄的一层unsafe layer,而在其之上完全使用safe rust编写。这个时候就可以回答这个问题了:如果是,那么Rust所标榜的 safe,岂不是一个虚幻的空中楼阁?
Rust通过这套方法学,让Safe Rust的代码部分可以自证安全,而Unsafe Rust的代码部分由程序员来保证安全。你可以想象一下,如果一个系统有10万行Rust代码,98%的代码是 Safe Rust,2%的代码是 Unsafe Rust,那么需要由人来审计的代码就只有2千行。那我们就可以把所有精力集中在这2千行代码的审计上,确保它们不会出问题。或者说即使出了问题,也可以去这2千行代码中去找原因。
而如果同样的这套系统,由10万行C/C++代码来实现,那么审计的时候,就必须审计 10万行代码,也就是 50 倍的审计工作量。遇到问题,也是在10万行代码里面去找原因。这个成本完全不可比拟。
因此,Rust 所标榜的 safe,完全不是空中楼阁。不仅不是空中楼阁,还是非常切实可行的一套软件工程方法学。
标准库中的unsafe示例
Rust标准库中有一些unsafe函数,我们来看两个。
Slice的 get_unchecked() 函数
fn main() { let x = &[1, 2, 4]; unsafe { assert_eq!(x.get_unchecked(1), &2); } }
在有 get() 的情况下,Rust标准库还提供这个 get_unchecked() 函数,原因其实也很简单,因为 get() 会进行边界检查,而 get_unchecked() 不会。在有些密集运算的情况下,边界检查对性能影响比较大,因此提供一个不做边界检查的版本,用来追求极致的速度。毕竟,Rust是一门与C/C++在同一层次的语言,不应该给Rust人为呆板地设置障碍,比如必须使用边界检查的安全版本。
str的 from_utf8_unchecked() 函数
fn main() { use std::str; // some bytes, in a vector let sparkle_heart = vec![240, 159, 146, 150]; let sparkle_heart = unsafe { str::from_utf8_unchecked(&sparkle_heart) }; assert_eq!("💖", sparkle_heart); }
这个函数我们在 第 4 讲 聊字符串的时候提到过,它不检查字节序列为有效的UTF8编码,因此转出来可能不是有效的字符串。原因也很简单,还是为了性能。在有些场合下,绝对的性能就是绝对的王道,Rust不给你设置天花板。
外部函数接口 FFI
这里我提出一个问题,你来想一下。 一门编程语言如何与另一门编程语言在语言层面交互呢? 这个问题还真不好办。
事实上,像JavaScript就不太可能直接与Python进行交互。大部分语言之间是没办法直接交互的。但是,历史却留下一个有趣且可贵的遗产——所有主流语言基本都能与C语言交互,因为它们都需要用C来写扩展,提升性能。当然 C++ 是在语言层面直接包含了 C,这个另当别论。
Rust在设计之初, 与C实现二进制级的兼容 就是一项重要目标。二进制兼容的意思其实就是Rust可以选择编译目标为符合C语言 ABI(Application Binary Interface)的二进制格式。
ABI包含数据结构怎么对齐、存储,函数如何传参、返参、调用二进制格式信息等,而Rust就支持编译到遵循 C ABI 的二进制库目标上。这意味着用Rust编写的共享动态库 .so、 .dll 等在外界看来,与用C编译成的 .so、 .dll 动态库没什么区别,你甚至不知道是什么语言写成的。因此,Rust编写的动态库也能被 Python、JavaScript、Go、Java 等其他语言调用,它们都支持C ABI动态库。
另一方面, C实现的动态库也能被Rust无缝调用,因为Rust能识别C ABI。一个C的库函数,在C应用中运行和在Rust应用中运行没什么区别,性能也没有损失,就好像没有跨语言一样,这就是Rust的魔法所在。
这点与其他动态语言如 Python、JavaScript 等就有很大差别。这些动态语言到C语言的FFI边界会有不小的额外消耗。究其原因,就是因为入参与返参会有类型转换的工作,而在这些动态语言中,类型是被GC托管的,这里面就有很多细节要处理,会带来额外的消耗。而Rust就不存在这个问题,前面我们提示,Unsafe Rust里面住着一位C国王,就好像一家人一样,或者至少是关系很近的亲戚。
尽管如此,有关Rust与C的FFI的知识点还是非常多的,有许多要注意的地方,也不是一下子就能掌握的,需要在实际需求产生时抠各种细节。另外,Rust中的Unsafe其实要求你考虑更多,因为它比传统的C语言工程更详尽地考虑了 未定义行为 的概念,它要求你尽可能地考虑周全, 因为封装给Safe Rust的功能被要求不能产生任何未定义行为。所以Rust不仅是工程上的创新,在学术理论上也有一定程度的创新,目标就是写出更健壮的代码。
小结
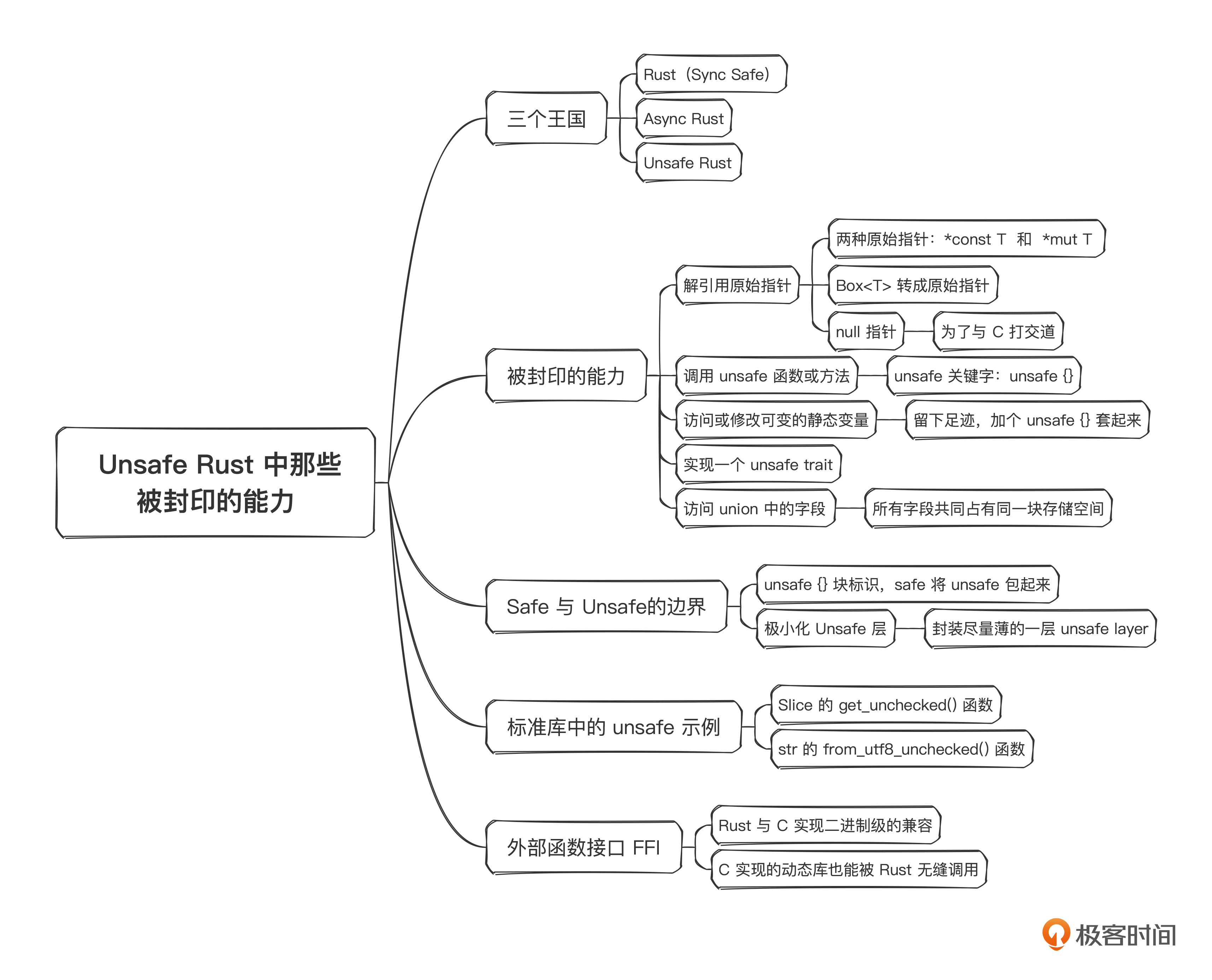
这节课我们了解了有关Rust中Unsafe和FFI的基础概念。我们进入Unsafe Rust后,就可以使用一些必杀技能了。这些技能威力巨大,但是也充满风险,需要由程序员自己来保证使用上的安全性。
我们说Rust由三个王国组成,既然是王国,那么内容铁定不会少。从 unsafe {} 这个大门进入Unsafe Rust,实际就进入了计算机体系结构的底层,你会发现一片美丽新世界。这个世界中有 OS、内存结构、对齐、锁、ABI、调度、指令集、总线协议等等眼花缭乱的新东西。我们之前提到过一种观点, 学习Rust就是学习CS计算机科学,Unsafe Rust就是下沉之门。
Rust与C有正统的血脉关系,可以实现真正的双向互通,而没有边界性能损失。这预示着未来在嵌入式、工业控制、航空航天、自动驾驶等领域,Rust都有非常大的潜力成为主流选手。绝大部分的人写熟了Rust以后就再也不想写C了,编程体验完全不可同日而语。长期来看,C语言的份额会逐渐缓慢地萎缩到一个比较小的范围,而Rust则会担当起C语言之前的重任。
我们要理解Rust将Safe建立在Unsafe的这套方法之上,这也是软件工业界几十年探索的一个重要成果。所以你会听到NASA、微软等机构呼吁新的软件开发不要再使用C/C++了,而应该用“安全编程”的语言来取代。从这个意义上来讲,Rust是划时代的语言。以后的语言可能会这么分类:Rust之后的语言与Rust之前的语言。
下节课我们会将Rust代码导出给C语言使用,并且进一步导出给Python使用,给Python实现一个自定义扩展。
思考题
Unsafe Rust比C语言更安全吗,为什么?欢迎你把自己的思考分享到评论区,也欢迎你把这节课的内容分享给需要的朋友,我们下节课再见!
Unsafe编程(下):使用Rust为Python写一个扩展
你好,我是Mike。
上一讲我们了解了Unsafe Rust的所属定位和基本性质,这一讲我们就来看看Rust FFI编程到底是怎样一种形式。
FFI是与外部语言进行交互的接口,在Safe Rust看来,它是不可信的,也就是说Rust编译不能保证它是安全的,只能由程序员自己来保证,因此在Rust里调用这些外部的代码功能就需要把它们包在 unsafe {} 中。
Rust和C有血缘关系,具有ABI上的一致性,所以 Rust和C之间可以实现双向互调,并且不会损失性能。
Rust调用C
我们先来看在Rust中如何调用C库的代码。
一般各个平台下都有 libm 库,它是操作系统基本的数学math库。下面我们以Linux为例来说明。下面的示例代码来自 Rust By Example。
use std::fmt; // 连接到系统的 libm 库 #[link(name = "m")] extern { // 这是一个外部函数,计算单精度复数的方根 fn csqrtf(z: Complex) -> Complex; // 计算复数的余弦值 fn ccosf(z: Complex) -> Complex; } // 对unsafe调用的safe封装,从此以后,就按safe函数方式使用这个接口 fn cos(z: Complex) -> Complex { unsafe { ccosf(z) } } fn main() { // z = -1 + 0i let z = Complex { re: -1., im: 0. }; // 调用m库中的函数,需要用 unsafe {} 包起来 let z_sqrt = unsafe { csqrtf(z) }; println!("the square root of {:?} is {:?}", z, z_sqrt); // 调用安全封装后的函数 println!("cos({:?}) = {:?}", z, cos(z)); } // 用 repr(C) 标注,定义Rust结构体的ABI格式,按C的ABI来 #[repr(C)] #[derive(Clone, Copy)] struct Complex { re: f32, im: f32, } // 实现复数的打印输出 impl fmt::Debug for Complex { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { if self.im < 0. { write!(f, "{}-{}i", self.re, -self.im) } else { write!(f, "{}+{}i", self.re, self.im) } } }
libm 库是用C语言实现的,我们要调用它,需要用这样的标注。
#[link(name = "m")]
extern {
}
用 lnk 属性宏将libm库连接进来,以便去里面找对应的函数。然后把需要的外部函数导入进来。你可以看一下 csqrtf() 函数和 ccosf() 的C语言签名。
float complex csqrtf(float complex z);
float complex ccosf (float complex z);
导入的时候,要翻译成Rust函数的签名形式。
fn csqrtf(z: Complex) -> Complex;
fn ccosf(z: Complex) -> Complex;
调用这两个函数的时候,都需要用 unsafe {} 包起来。
然后我们仔细看一下在Rust中对应到libm中的复数的定义。
#[repr(C)]
#[derive(Clone, Copy)]
struct Complex {
re: f32,
im: f32,
}
对应的C语言中的结构定义在 complex.h 头文件 中,它是C99标准引入的数据类型。
本身这个定义非常简单,就是定义复数的实部和虚部就可以了,不过一定要用 #[repr(C)] 标注。它的意思是这个类型编译的时候,要使用C语言的ABI格式。我们一般都使用C语言ABI格式,但是也有一些其他的ABI格式,你可以点击我给出的 链接,查到Rust中支持的ABI格式列表。
一般来讲,我们会使用Rust函数对这些外部unsafe函数做一下封装。像cos函数这样,你可以参看一下示例代码。
fn cos(z: Complex) -> Complex {
unsafe { ccosf(z) }
}
执行 cargo run,输出了下面这两行代码。
the square root of -1+0i is 0+1i
cos(-1+0i) = 0.5403023+0i
注:项目代码链接 https://github.com/miketang84/jikeshijian/tree/master/30-ffi/rust_call_c
bindgen
Rust官方出了一个 bindgen 项目,可以帮助我们快速从C库的头文件生成Rust FFI绑定层代码。之所以能这样做,是因为我们发现,C的接口转换成Rust的接口形式是非常固定的,转换的过程需要写大量的样板代码,所以就可以用 bindgen 这种工具自动转换。
比如某个C头文件里定义了这样的类型和函数:
typedef struct Doggo {
int many;
char wow;
} Doggo;
void eleven_out_of_ten_majestic_af(Doggo* pupper);
使用 bindgen 自动生成FFI绑定后,可以生成类似这样的代码:
/* automatically generated by rust-bindgen 0.99.9 */
#[repr(C)]
pub struct Doggo {
pub many: ::std::os::raw::c_int,
pub wow: ::std::os::raw::c_char,
}
extern "C" {
pub fn eleven_out_of_ten_majestic_af(pupper: *mut Doggo);
}
你可能发现了,Rust里有一批类型,以 c_ 前缀开头。比如 C语言的 int 类型,对应 std 中的类型你可以通过我给出的 链接 找到。
这些就是Rust里定义的与C完全相同的类型。我们可以看一下 c_char 的定义。
pub type c_char = i8;
竟然直接是一个 i8。因为C语言里的char就是一个普通字节,和Rust里的char完全不同。这是在Rust中完全兼容C必要的一步,就是 把C中的类型全部映射过来,并加上c_ 前缀。这样单独搞一批类型就是因为有的类型没办法直接映射到 Rust 的 char 上来,比如刚刚说的这个 c_char。
典型的,还有 C 语言中的 void 类型,它在Rust里没有对应物,所以就映射成了 c_void,在Rust中定义成了一个 enum。
#[repr(u8)]
pub enum c_void {
// some variants omitted
}
下面我们继续看,反过来,在C中如何调用Rust代码。
C调用Rust
在C中调用Rust代码的基本思路是,Rust代码编译成 .so 或 .dll 动态链接库,在C语言里面编译的时候,连接就可以了。
在 lib.rs 文件中,写这样一个函数:
#[no_mangle]
pub extern "C" fn hello_from_rust() {
println!("Hello from Rust!");
}
注意属性宏 #[no_mangle],在Rust中,no_mangle 用于告诉Rust编译器不要修改函数的名称,这种修改叫做Mangling,它是编译器在解析名称时,修改我们定义的函数名称,增加一些用于其编译过程的额外信息。但在和其他语言交互时,如果函数名称被编译器修改,程序开发者就没办法知道修改后的函数名称了,其他语言也无法按原名称调用。因此,#[no_mangle] 在这种场景下就非常有用了。
Cargo.toml 要加个配置,表示编译的这个库是 C ABI 格式的动态链接库。
[lib]
crate-type = ["cdylib"]
然后用 cargo build 编译输出。你可以在 target/debug 目录下面看到你的 .so 库文件,比如下面这个样子:
$ ls target/debug/
build deps examples incremental libc_call_rust.d libc_call_rust.so
这里这个 libc_call_rust.so 就是我们的动态链接库,其中 c_call_rust 是我们这个 crate 的名字。
下面是C的部分,代码如下:
extern void hello_from_rust();
int main(void) {
hello_from_rust();
return 0;
}
存成 call_rust.c 文件。用下面这种形式编译:
gcc call_rust.c -o call_rust -lc_call_rust -L./target/debug
运行:
LD_LIBRARY_PATH=./target/debug ./call_rust
你可以看到输出内容 Hello from Rust!。
注:完整可测试代码 https://github.com/miketang84/jikeshijian/tree/master/30-ffi/c_call_rust
当然,这只是最简单的形式,万里长征我们刚踏出第一步,还有各种复杂的FFI场景等着你去探索。
Cbindgen
在实际工作中,当你需要以Rust仓库为主,为其他语言导出C接口的时候,一般还需要生成C的头文件,这时,你应该会对 cbindgen 项目很感兴趣,它也算半官方的(在Mozilla名下),它的作用与前面的 bindgen 刚好相反,是从Rust代码中生成C可以调用的代码签名。
Rust与C的交互我们先讨论到这里,下面我们要研究一下如何用Rust给Python写扩展。
使用Rust给Python写扩展
标准的Python扩展是用 C/C++ 写的,Python 官方有 教程,感兴趣的话你可以研究一下。我们这节课聚焦于如何用Rust给Python写扩展。
其实,只要你将Rust的代码扩展到C可以调用,那么再进一步,按Python官方教程那样,继续将C代码封装成Python扩展就可以了,下面我们讲的基本思路也是这样。
在实际实现的时候,我们会写非常多的样板代码,写起来比较痛苦。但是Rust社区有非常优秀的项目:PyO3,它可以帮助我们减轻这种烦恼,自动帮我们处理好中间样板封装过程。
PyO3
PyO3是Rust社区里非常火的与Python绑定的框架,它不仅可以实现用Rust给Python写扩展,还能在Rust的二进制程序中直接执行Python代码。所以实际 PyO3 是一个双向绑定库。
PyO3封装了底层FFI绑定的各种细节。这些细节其实不是那么简单,你可以想一下,如何将Python的Class正确映射到Rust中对应的类型,如何正确处理模块、函数、参数、返回值类型,这里面有各种细节,想想就头痛。
而 PyO3 把这一切都封装在了Rust属性宏里面。我们来看一个示例。
use num_bigint::BigUint;
use num_traits::{One, Zero};
use pyo3::prelude::*;
// Calculate large fibonacci numbers.
fn fib(n: usize) -> BigUint {
let mut f0: BigUint = Zero::zero();
let mut f1: BigUint = One::one();
for _ in 0..n {
let f2 = f0 + &f1;
f0 = f1;
f1 = f2;
}
f0
}
#[pyfunction]
fn calc_fib(n: usize) -> PyResult<()> {
let _ = fib(n);
Ok(())
}
#[pymodule]
fn rust_fib(_py: Python<'_>, m: &PyModule) -> PyResult<()> {
m.add_function(wrap_pyfunction!(calc_fib, m)?)?;
Ok(())
}
这个示例的作用是计算斐波那契数列的第N项。当这个N值比较大的时候,斐波那契数是一个非常大的数,一个u64装不下,因此我们要使用大数类型。在Rust中,num-bigint是一个常用的大数类型实现库。而在Python中,int默认就支持大数。
代码中, fib() 函数是真正计算斐波那契数的函数,然后在 calc_fib() 中封装给了 Python 使用,请注意这个函数头上的 #[pyfunction] 标注,它表明这个函数会导出给 Python 使用,是一个函数。
而下面的 rust_fib() 函数,则是标准的样板代码,它表示创建一个 Python 的模块,这个模块的名字叫做 rust_fib,这个名字会在Python代码中以 import rust_fib 的形式导入。 #[pymodule] 就起这个自动转化的作用。这个函数中的 m 参数就表示模块实例, m.add_function() 将 calc_fib() 添加到这个模块中。所以我们这个 crate 库会被编译成一个共识库,并被导入为 Python 的一个模块。
你可以看一下 Cargo.toml 的新增配置。
[lib]
name = "rust_fib"
crate-type = ["cdylib"]
在Python中这样调用:
import rust_fib
rust_fib.calc_fib(2000000)
注:完整的可运行代码 https://github.com/miketang84/jikeshijian/blob/master/30-ffi/bigint-pyo3
这样PyO3项目的一个关键是,需要使用 maturin 这种构建工具。你可以下载代码后,按下面的脚本准备好虚拟环境,并在这个虚拟环境里安装好 maturin。
$ cd bigint-pyo3
$ python -m venv .env
$ source .env/bin/activate
$ pip install maturin
在项目目录下运行:
maturin develop -r
这个指令会编译Rust代码为 release 模式,并把编译后的文件安装到 Python module 库的目录组织里去。
然后运行:
$ time python fib_rust.py
real 0m12.452s
user 0m12.431s
sys 0m0.020s
我们对比一下纯Python版本运行的时间。
$ time python fib.py
real 0m21.730s
user 0m21.490s
sys 0m0.240s
这是计算第200万项斐波那契数,可以看到用Rust实现的版本快将近一倍。
PyO3给我们提供的编程界面非常清爽,只要你跟着操作一遍,很快就能用Rust给Python写扩展了。PyO3的 文档 也写得非常好,上面有更全面的功能介绍,一定要读一读。
性能优化示例:文本单词统计
Python的GIL(Global Interpreter Lock)是一个被人诟病的特性,它限制很多Python代码只能以单线程的形式来跑。因此也就大大限制了Python的性能。而Rust原生支持系统级多线程(thread)以及轻量级线程(tokio task 等),能够非常方便地充分压榨所有CPU核。既然我们可以使用Rust给Python写扩展,那一个点子就顺理成章冒出来了——可以使用Rust给Python写扩展实现并行计算。
下面我们就以官方的示例 word_count 来说明如何使用。这个程序要解决这样一个问题:统计出一个文本文件里,某一个单词出现的次数。这个文本文件是按换行符分隔成一行一行的,行与行之间互不干涉。因此可以采用按行分割的形式来并行化处理。
Rust中有一个著名的并行化库Rayon,可以将串行迭代器转换成一个并行化版本的迭代器,从而实现程序的并行化。下面我们来看代码:
use pyo3::prelude::*;
use rayon::prelude::*;
/// 并行化版本的搜索功能实现
#[pyfunction]
fn search(contents: &str, needle: &str) -> usize {
contents
.par_lines()
.map(|line| count_line(line, needle))
.sum()
}
/// 将行按空格分割,统计目标单词数目
fn count_line(line: &str, needle: &str) -> usize {
let mut total = 0;
for word in line.split(' ') {
if word == needle {
total += 1;
}
}
total
}
// 导出到Python module
#[pymodule]
fn word_count(_py: Python<'_>, m: &PyModule) -> PyResult<()> {
m.add_function(wrap_pyfunction!(search, m)?)?;
Ok(())
}
代码中, search() 函数中 contents.par_lines() 这一行就是使用的 Rayon 里的 par_lines() 迭代器,它是 lines() 迭代器的并行化版本。上面的 search 实现对应下面的 Python 版本。
def search_py(contents: str, needle: str) -> int:
total = 0
for line in contents.splitlines():
for word in line.split(" "):
if word == needle:
total += 1
return total
你可以看一下 项目代码,这个项目使用 pytest-benchmark 来做性能评测。要运行性能评测,你需要安装 nox。
// 先安装项目依赖
pip install .
// 再安装 nox 工具
pip install nox
然后在项目根目录下运行:
nox -s bench
稍等片刻,我们会得到如下输出:
$ nox -s bench
nox > Running session bench
nox > Creating virtual environment (virtualenv) using python3 in .nox/bench
nox > python -m pip install '.[dev]'
nox > pytest --benchmark-enable
=========================================================== test session starts ============================================================
platform linux -- Python 3.10.12, pytest-7.4.3, pluggy-1.3.0
benchmark: 4.0.0 (defaults: timer=time.perf_counter disable_gc=False min_rounds=5 min_time=0.000005 max_time=1.0 calibration_precision=10 warmup=False warmup_iterations=100000)
rootdir: /home/mike/works/pyo3works/word-count
configfile: pyproject.toml
plugins: benchmark-4.0.0
collected 2 items
tests/test_word_count.py .. [100%]
----------------------------------------------------------------------------------------- benchmark: 2 tests ----------------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_word_count_rust_parallel 19.6740 (1.0) 50.2725 (1.0) 27.9049 (1.0) 9.7562 (2.27) 22.9368 (1.0) 8.5993 (1.13) 2;2 35.8360 (1.0) 13 1
test_word_count_python_sequential 78.4158 (3.99) 91.5790 (1.82) 84.4852 (3.03) 4.3023 (1.0) 84.7501 (3.69) 7.6210 (1.0) 5;0 11.8364 (0.33) 13 1
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Legend:
Outliers: 1 Standard Deviation from Mean; 1.5 IQR (InterQuartile Range) from 1st Quartile and 3rd Quartile.
OPS: Operations Per Second, computed as 1 / Mean
============================================================ 2 passed in 2.78s =============================================================
nox > Session bench was successful.
可以看到,Rust并行化版本比Python顺序化版本的平均性能提升了3倍左右(并行化版本消耗时间为顺序化版本的1/3左右),实际上被处理的文件越大,这个性能提升就越明显。
业界知名PyO3绑定项目介绍
目前,Rust生态和Python之间已经有一些知名的项目使用 PyO3 实现绑定了,我选了几个比较不错的放在下面,你可以点击链接深入了解一下。
- OpenDAL 的 Python 绑定: https://github.com/apache/incubator-opendal/tree/main/bindings/python
- Polars 的 Python 绑定: https://github.com/pola-rs/polars/tree/main/py-polars
- Delta Lake 的 Python 绑定: https://github.com/delta-io/delta-rs/tree/main/python
- Arrow-Datafusion 的 Python 绑定: https://github.com/apache/arrow-datafusion-python
- tokenizers 的 Python 绑定: https://github.com/huggingface/tokenizers/tree/main/bindings/python
小结
这节课我们通过4个示例展示了如何在Rust中调用C函数,如何在C函数中调用Rust函数,以及在Python中调用Rust实现的模块和函数。并且通过对比Rust的实现版本与Python原生的实现版本,我们发现使用Rust写Python扩展性能更好。
Unsafe Rust编程大量出现在底层性能的优化和与其他语言交互的场景中,体现了Rust这门语言一个奇特的地方:Rust语言本身对安全性和性能的追求,不但让Rust本身脱颖而出,而且还反哺了C语言的生态,用Rust重新实现一部分模块,同时还能无缝地接入之前的C系统中,提升了之前C系统的安全性。并且这是一种渐进的做法,非常有利于历史遗留系统的迭代更新。
此外,Unsafe Rust编程还可以赋能其他语言社区,将Rust的澎湃动力和安全扩展到了Python、JavaScript等其他语言。它们之前的扩展使用C/C++编写,同样会存在安全性和稳定性的问题,而Rust解决了这个问题。
不过涉及到Unsafe Rust和FFI的场景,想要封装一个真正好用的库或扩展,还有大量的细节知识待你探索。不管怎样,我们已经踏上了安全提升和性能提升之路,有Rust为你输出动力,保驾护航,你便可以放开手脚,大胆去干。
思考题
请你聊一聊,C语言中的char与Rust中的char的区别在哪里?C语言的字符串与Rust中的String区别在哪里?如何将C语言的字符串类型映射到Rust的类型中来?欢迎你把自己的思考分享到评论区,也欢迎你把这节课的内容分享给其他朋友,我们下节课再见!
结束语|未来让Rust带你“锈”到起飞
你好,我是你的老朋友 Mike。
30讲的课程很快就结束了,感谢你一路的支持与陪伴,每一次评论区的互动都能让我感觉到写这门课的重要意义。我看到了你在不断思考中对Rust的理解越来越深,畏难情绪也随之一分分减少,很长一段时间我一起床就会打开评论,看看你有哪些新思考、新困惑,这也成了我每天的动力来源。
看到越来越多的朋友加入学习,逐渐“锈”化,我想我写这门课程最基本的目标达到了——让你以比较轻松的心态去掌握Rust的基础知识,为你以后用Rust去解决生产上的难题打下坚实的基础。
在这几个月里我们了解了Rust很多非常重要的特性,对所有权、Trait、类型还有异步编程和Unsafe编程等重要概念有了更深的理解,此外还转变了对Rust小助手的态度,真正把它当成了我们的好伙伴。这都是我们共同努力的结果。
而这最后一节课也同样珍贵,所以我还是想再“唠叨唠叨”,带你回顾我们课程里最重要的一些东西。希望你不仅能够掌握基本的Rust代码应该怎么写,还能理解Rust为什么要这样设计。
Rust所有权是怎么来的?
要说 Rust 里最重要的东西,一定少不了所有权,都说重要的事情说三遍,在课程中我说了又何止三遍,所以我想用这最后一点点宝贵的时间再来讲一讲所有权从何而来,又何以至此的。我们都知道Rust成长于巨人的肩膀上,所以我们可以从C语言说起。
C语言的手动内存管理
C的做法是完全交给程序员自己来管理堆内存,也就是分配内存及释放内存。比如:
- 你malloc了一块内存,但是如果忘了写 free 的话,就会造成内存泄露。
- 如果你在不同的地方 free 了两次的话(指针的多次free),就会造成未定义行为,比如段错误。
- 你定义了一个指针,但是没有初始化的话,对指针的解引用(未初始化指针访问)也会生成未定义行为。
- 你用一个指针指向了一个分配的堆内存,但是在某个地方被free掉了,但是你又对这个指针解引用的话(释放后访问),又会出现未定义行为。
- ……
因此在C语言中,出现了一套避坑的最佳实践总结,其中最重要的一条原则就是 谁分配谁释放,这是一条人为的约定。
看起来C语言里的内存管理完全是手动的,其实不尽然,手动管理的主要是堆内存部分。栈上内存的管理其实是自动的。因为栈上的内存管理只涉及到一个栈顶指针和计算偏移量,会以函数栈帧为单元压栈出栈,这块儿内存会随着函数层次的调用自动分配和回收。编译器保证了这块的内存不会发生错误的管理。
Java的GC
由于C语言内存管理非常痛苦,总是避免不了各种内存崩溃的问题。人们想出了另一种方案,用一个管家自动帮我们清理那些不要的“垃圾”,这正是Java 等后面一系列语言的做法。这个管家就是 GC(垃圾回收器)。这种方案的思路就是,程序员只管分配内存,用完就不管了,GC会自动跟踪这些资源,在适当的时候自动回收。这大大释放了程序员的心智负担,有人给你负责收尾了,多大的好事儿呀!
但是GC方案的代价也是明显的,比如不管使用什么跟踪回收算法,它始终存在STW(Stop the World)的问题。它总是在程序员与底层之间隔离了一层,很难做到精确控制。这两点在做上层应用开发的时候问题不明显。但是在涉及到一些关键系统的时候,影响就很大了。大部分情况下,运行性能也会有影响。
C++的智能指针
C++是一门很牛的语言,它一方面做到了完全兼容C。另一方面又在现代语言的方向上做了很多探索。 RAII(Resource acquisition is initialization)或者 SBRM(Scope-based Resource Management)就是在C++里面提出的。
它的思路其实就基于上面提到的那个情况: 既然栈上的内存管理是自动的,那如果找到一种办法将堆上的资源与栈上的内存资源绑定,那不就可以自动管理堆上的内存资源了吗? 让堆上的内存资源随着栈上的资源一起创建一起回收,同时这也是使用固定尺寸的结构管理非固定尺寸的结构的方法。
既然是绑定,那就会存在一个指向的关系,也就是需要在栈上的一个固定尺寸的结构中有一个指向待管理的堆内存资源的指针,这个指针存的就是那个堆内存资源的内存地址。这个固定尺寸的结构就是 智能指针。因此在C++中你会看到 unique_ptr、 shared_ptr 等智能指针。
Rust的所有权
Rust完全沿用了这个优秀的思想和方法,却没有从语法上兼容C的负担。Rust进一步把这个负责管理资源的智能指针冠以 所有权。对应的,Rust中的原始指针raw pointer就没有所有权的概念,因为它并不参与负责释放的工作。
智能指针有很多种策略,与C++版本对应的,Rust的 Box<T> 就对应 unique_ptr,独占所有权, Arc<T> 就对应 shared_ptr,共享所有权。从前面的学习可以看到,String、Vec其实也是智能指针,它们具有所有权属性。Box就是泛化版本的String、Vec,String、Vec 是特化版本的 Box。当然还存在其他智能指针,你甚至可以构思自定义策略,定义自己的智能指针。
当然所有权不仅涵盖智能指针和堆上的资源。栈上的资源也有所有权。比如 i8、固定尺寸的结构体等等,默认都放在栈上,它们也是具有所有权的。所有权概念的核心在于一个栈上变量(当然是固定尺寸的)是否负责管理资源。对于i8这样固定尺寸的结构体等类型来说,它们本身的值就存在栈上分配的那一小块内存空间中,因此会随着栈的回收自动被回收掉,因此也相当于这些变量也管理了资源。因此它们也是具有所有权的。
所有权之上:Move与Copy
而Move语义与Copy语义是另一码事,你可以把它理解成所有权之上的上层概念。在Rust中,只要某种类型实现了Copy trait,那么在使用 = 号再赋值时,就会执行 Copy 语义。反之,会执行Move语义。
为了方便操作,Rust对语言和标准库里很多固定尺寸的基础类型实现了 Copy 语义,而对同样是固定尺寸的结构体却默认没有实现Copy语义。 Move语义就是移动所有权,防止过大的内存复制开销。Copy语义就是复制所有权,创建新的所有权,原来那个所有权仍然被原来的变量持有。
'a 生命期标注
Rust通过所有权机制,实现了对资源的“自动”管理。但是这种管理方式也会带来一些新的负担,那就是对所有权变量的引用生命期的有效性分析就会比较复杂,因为需要确保这些引用不能超出所有权型变量的生命期。这块目前业界还无法做到逻辑级别的分析,只是从函数的签名定义上进行分析。 因此在必要的时候,Rust编译器还需要程序员来提供一些信息,这就是 'a 生命期标注的来源。
严格的引用生命期分析是Rust开辟的新领域,比C++更进一步。所以说Rust不仅是工程上的创新,也在计算机语言理论上做了一些创新。
所有权有三态: 所有权变量、不可变引用、可变引用。 这三种形态几乎贯穿Rust语言的所有方面。 Box<Self>、 Arc<Self> 等实际只是所有权变量的变体。其实Rust的所有权就是这么一回事儿,就是这些内容了。
Rust难学的点在哪儿?
除了所有权这一块之外,Rust普遍被认为难学的还有它 严格的类型系统,很多人不习惯。
- 类型化与类型参数(泛型)各种形式的组合。
- 类型嵌套的洋葱结构会让类型变得很长,一旦出现类型不匹配的问题,初学者容易被编译器给出的信息吓住。
- 全新的trait理念。
Rust中的类型确实比较严格,比如字符串,C里就一个 char *,而Rust中有那么多不同的分类。但是实际上,C 的 char * 在真正在使用的时候,还需要在不同的场景中学习那个场景中的知识,并在 char * 基础上继续小心翼翼地处理。而Rust中的这些字符串类型其实已经包含了很多场景信息了,你直接用就行了,如果用得不对,在编译期间就会被指出。 类型化其实就是囊括更多规范信息的过程,让我们在编程的时候减少出错的几率。
Rust的错误处理也完全建立在标准化的类型系统上( Result<T, E>),这是一种与之前的主流语言完全不同的思路,因此开始学起来可能不太适应。但是其实一旦思路转换过来,会发现Rust的这套标准的错误处理思想更优美,更能降低我们的心智负担。
类型系统与传统的OOP
trait理论是一种平铺的理念,它与传统的OOP理念完全不同,甚至是完全对立的。你可以这样来理解,OOP就像传统血缘社会,做什么都要看出身,而trait是现代法治社会,大家都平等。 在 Rust中,所有 trait 都是平等的。 不管是std标准库中的trait,还是你自定义的trait,它们都是平等关系,不存在什么继承。
trait可以类比为社会中的法律,给实体(自然人、法人等)以约束。法律约束你的同时,其实也给你界定了能做的事情,也就是你具有某些能力。因此类比过来,trait 体系实际是一种约束 + 能力体系。从社会的发展来看,Rust 这种 trait 架构下的类型体系,相比于OOP,生产力可以更高。或者说 Rust 的 trait 体系,实际更容易准确描述现实世界,因为现代世界主体就是按这种方式运行的。
当然我们并不是说 OOP 就是错的。在某些场合,比如族谱模型、GUI界面描述等,它确实是更适合的抽象方法。因此你可以看到Slint这种GUI框架,在Rust中造出一个具有继承能力的描述性语言slint。这就相当于把两种抽象方法的优势结合起来了。
从难度来讲,其实trait体系比完整的OOP体系更简单、知识点更少。开始时感觉难学,可能主要是思维需要转变。毕竟OOP思想占据了软件开发核心地位几十年了。
因此 学习Rust的两大核心就是所有权体系与trait 体系。它们就好像一根绳子的两头,只要你把两个头提起来了,那么其他东西很快就跟着起来了。并不是说其他东西不重要,它们都是构成Rust这个整体的重要组成部分。我们这里说的是学习方法,一定要把这两个主要的东西搞懂,其他的知识点相对比较独立,可以被这两样特性有效地串起来。
最后的寄语
你学习Rust的时候更重要的是学会转变思维,毕竟前面几十年的主流语言都采用了不同的思维模型。只要你花上一定时间适应了它,你就会发现Rust是如此优美、高效、富有创意。
Rust是一位多面手,知识点很多。你可以先选择一个方向切入,使用Rust实现你最熟悉的或者最感兴趣的业务系统,产生价值回馈,然后再扩展到其他感兴趣的方面。就像我常说的, 学习和应用 Rust 没有天花板,天花板就是你的想象力。
Rust能应用在广泛的行业,我们这门课程只是刚起了个头,后面还有大量的知识点需要深入探索。学Rust就是学CS计算机科学,希望你与我一起持续探索,用Rust赋能各行各业。
听我说了这么多,最后我也想听听你的想法,这里我特别准备了一份 结课问卷,你可以花几分钟填写一下,希望能够听到你的“声音”。

结课测试|来赴一场满分之约
你好,我是唐刚。
《Rust语言从入门到实战》正式结课了,非常开心能和你交流技术、共同进步,为认真学习的你点赞!为了帮你检验自己的学习成果,我特意准备了一套结课测试题。题目共有 20 道,11 道单选题,9 道多选题,满分 100 分,快来挑战一下吧!
