所有权(上):Rust是如何管理程序中的资源的?
你好,我是Mike。今天我们来讲讲Rust语言设计的出发点——所有权,它也是Rust的精髓所在。
在第一节课中,我们了解了Rust语言里的值有两大类:一类是固定内存长度(简称固定尺寸)的值,比如 i32、u32、由固定尺寸的类型组成的结构体等;另一类是不固定内存长度(简称非固定尺寸)的值,比如字符串String。这两种值的本质特征完全不一样。而 怎么处理这两种值的差异,往往是语言设计的差异性所在。
就拿数字类型来说,C、C++、Java 这些语言就明确定义了数字类型会占用内存中的几个字节,比如8位,也就是一个字节,16位,也就是两个字节。而JavaScript这种语言,就完全屏蔽了底层的细节,统一用一个Number表示数字。Python则给出了int整数、float浮点、complex复数三种数字类型。
Rust语言因为在设计时就定位为一门通用的编程语言(对标C++),它的应用范围很广,从最底层的嵌入式开发、OS开发,到最上层的Web应用开发,它都要兼顾。所以它的数字类型不可避免地就得暴露出具体的字节数,于是就有了i8、i16、i32、i64等类型。
前面我们说到,一种类型如果具有固定尺寸,那么它就能够在编译期做更多的分析。实际上固定尺寸类型也可以用来管理非固定尺寸类型。具体来说,Rust中的非固定尺寸类型就是靠指针或引用来指向,而指针或引用本身就是一种固定尺寸的类型。
栈与堆
现代计算机会把内存划分为很多个区。比如,二进制代码的存放区、静态数据的存放区、栈、堆等。
栈上的操作比堆高效,因为栈上内存的分配和回收只需移动栈顶指针就行了。这就决定了分配和回收时都必须精确计算这个指针的增减量,因此 栈上一般放固定尺寸的值。另一方面,栈的容量也是非常有限的,因此也不适合放尺寸太大的值,比如一个有1000万个元素的数组。
那么非固定尺寸的值怎么处理呢?在计算机体系架构里面,专门在内存中拿出一大块区域来存放这类值,这个区域就叫“堆”。
栈空间与堆空间
在一般的程序语言设计中,栈空间都会与函数关联起来。每一个函数的调用,都会对应一个帧,也叫做 frame 栈帧,就像图片栈空间里的方块 main、fn1、fn2等。一个函数被调用,就会分配一个新的帧,函数调用结束后,这个帧就会被自动释放掉。因此 栈帧是一个运行时的事物。函数中的参数、局部变量之类的资源,都会放在这个帧里面,比如图里fn2中的局部变量a,这个帧释放时,这些局部变量就会被一起回收掉。
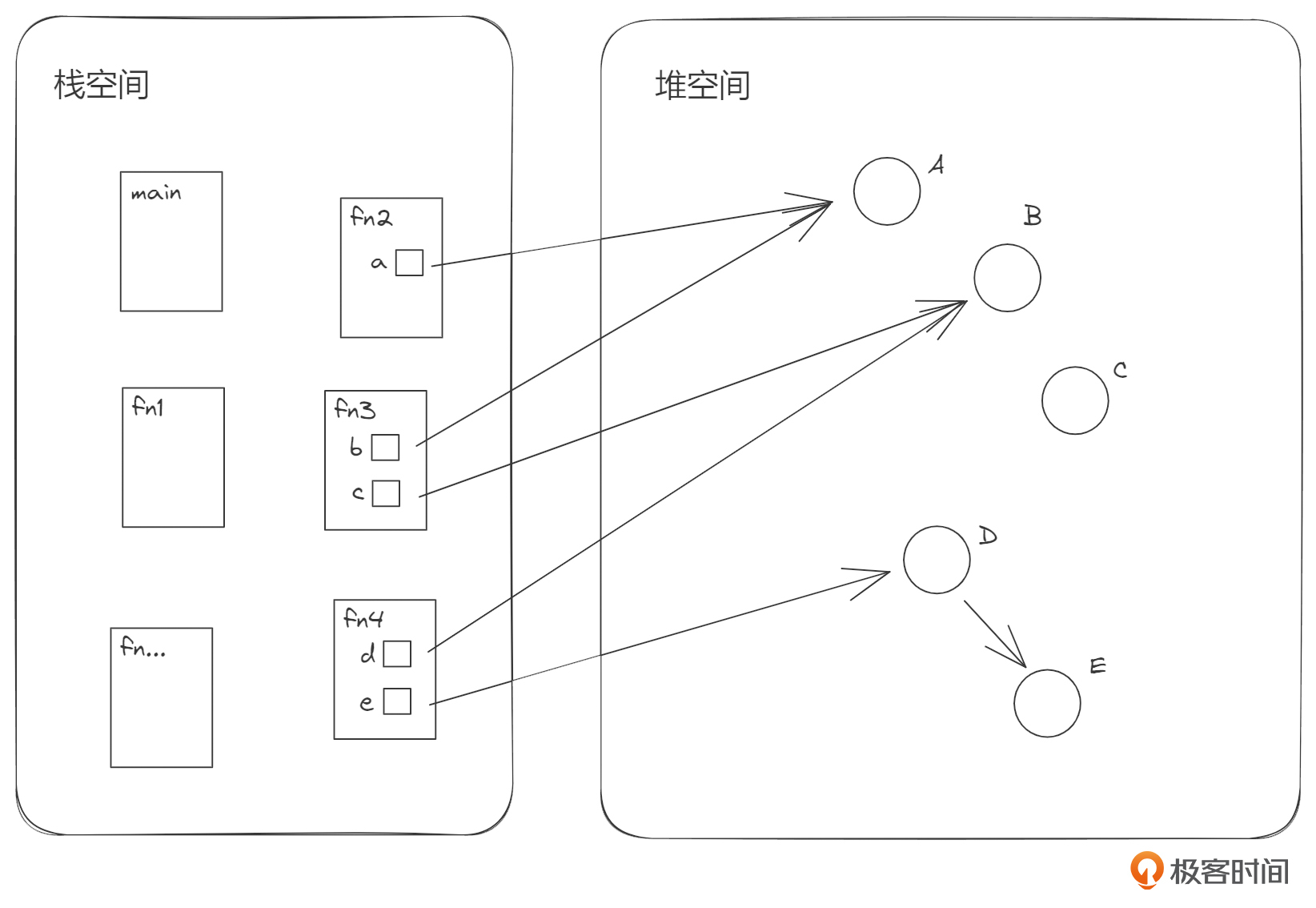
函数的调用会形成层级关系,因此栈空间中的帧可能会同时存在很多个,并且在它们之间也对应地形成层级关系。如上图所示,可能的函数调用关系为,main函数中调用了函数fn1,fn1中调用了函数fn2,fn2中调用了函数fn3,fn3中调用了函数fn4,fn4调用了更深层次的其他函数。这样的话,在程序执行的某个时刻,main函数、fn1、fn2、fn3、fn4 等对应的帧副本就同时存在于栈中了。
图中右边堆空间里面的一些小圈表示堆空间中资源,也就是被分配的内存。从图中可以看到,栈空间中函数帧的局部变量是可以引用这些堆上资源的。一个栈帧中的多个局部变量可以指向堆中的多个资源,如fn3中的b指向资源A,c指向资源B;同时存在的多个栈帧中的局部变量还可以指向堆上的同一个资源,如图中的a和b,c和d;堆上的资源也可以存在引用关系,如图中的D和E。
如果一个资源没有被任何一个栈帧中的变量引用或间接引用,如图中的C,那么它实际是一个被泄漏的资源,也就是发生了内存泄漏。被泄漏的资源会一直伴随程序的运行,直到程序自身的进程被停止时,才会一起被OS回收掉。
而计算机程序内存管理的复杂性,主要就在于 堆内存的管理比较复杂——既要高效,又要安全。
这里我们稍微提及了一点计算机的结构知识,你可以停下来仔细理解这张图示表达的意思,在后面我们还会经常回顾这张图。有了栈和堆的知识作为铺垫,你会更容易理解Rust中的一些特性为什么要那样设计。
下面我们回到Rust语言,继续讲Rust中另一个重要概念——可变性。
变量与可变性
回顾第一讲的知识,在Rust中定义一个变量,使用 let variable = value; 这种语法。比如 let x = 10u32;,就定义了变量 x。然后,10u32是一个值,它被绑定到这个变量上。
默认变量是不可变的,我们来做个实验。
fn main() { let x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); }
输出:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| -
| |
| first assignment to `x`
| help: consider making this binding mutable: `mut x`
3 | println!("The value of x is: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
Rust默认这样做是为了减少一些很低级的Bug。假如默认可以改的话,如果你在一个代码量很大而且离定义变量很远的某个分支语句里面修改了这个变量的值,然后在后面某个函数调用里面又用到了它,结果导致程序行为与期望不符,这时你很难看出来问题出在哪儿。这种低级错误能不犯就不犯,Rust干脆帮你禁用了这种方式。
但是下面这样做是可以的。
fn main() { let x = 5; println!("The value of x is: {x}"); let x = 6; // 注意这里,重新使用了 let 来定义新变量 println!("The value of x is: {x}"); }
这种方式在Rust中叫做变量的Shadowing。意思很好理解,就是定义了一个新的变量名,只不过这个变量名和老的相同。原来那个变量就被遮盖起来了,访问不到了。这种方式最大的用处是程序员不用再去费力地想另一个名字了!变量的Shadow甚至支持新的变量的类型和原来的不一样。
比如:
fn main() { let a = 10u32; let a = 'a'; println!("{}", a); }
那如果我们要修改变量的值应该怎么做呢?只需要在变量名前面加一个mut就可以声明一个变量为可以修改内容的。
let mut x = 10u32;
例子:
fn main() { let mut x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); } // 输出 The value of x is: 5 The value of x is: 6
注意,值的改变只能在同一种类型中变化,在变量x定义的时候,就已经确定了变量x的类型为数字了,你可以试试将其改成字符串,看会报什么错误。
这里你可以回过头去对比一下,可修改变量和变量的Shadow的不同之处。
一个变量,其内容是否可变,被称作这个变量的 可变性(mutability)。mut 叫作可变性修饰符(modifier)。
可能你会非常疑惑,变量不就应该是会变化的吗? 既然默认不可变,为什么要称其为变量呢?其实上面一段我已经回答了这个问题,Rust中变量的可变性是一种潜力,只要它有可能会变化,那么就可以称之为变量。而Rust给这种潜力加了一道开关, 当你想让这个变量的可变性暴露出来的时候,就在变量名前面明确地加个mut修饰符。
可以看到,变量名加了mut,多打了4个字符,这实际是在代码中留下了一种足迹。也就是说给了程序员一个信息,当你自己或别的程序员在读到这个变量的定义时,他会知道,后面一定会修改这个变量,因为如果你后面没修改它,Rust编译器会提示你把这个mut去掉。
这种设计还有一个好处,那就是减少滥用概率。我们在这里构造一个编程语言界的墨菲定律, 如果一个特性不太利于程序的健壮性,但是很好用,滥用的成本非常低,那么它一定会被滥用。
比如 TypeScript 中的 any 类型,有时写TS代码懒得去设计类型,直接就用any类型了,反正“先跑通了再说”。结果就是最后项目完成了,代码里面any满天飞,TS的设计初衷被抛至脑后。偷懒是人的天性,Rust接受了这种天性,让你想要修改一个变量的时候,需要多付出点成本,也就是多打4个字符。
另一个例子是 JS 中的 var 和 let,都是三个字符,敲的字符数一样,成本一样,结果就是在语言层面并不能驱动程序员往好的实践方面靠。有人会辩称,在这些语言中会有推荐规范或强制要求,要求你按好的实践方式写。不过在实际项目中,由于进度等问题,这些规范总是很难完全贯彻下去,即使贯彻下去也很难达到预期效果,这方面已有太多案例了。因为那些都是补救措施,哪有从语言层面强制约束你做来得统一。
变量的类型
值是有类型的,比如 10u32,它就是一个u32类型的数字。一旦一个变量绑定了一个值,或者说一个值被绑定到了一个变量上,那么这个变量就被指定为这种值的类型。比如 let x = 10u32; 编译器会自动推导出变量x的类型为 u32。完整的写法就是 let x: u32 = 10u32;。
此外还有一种方式,就是直接先指定变量的类型,然后把一个值绑定上去,比如 let x: u32 = 10;。这种方式更好, 它能说明你在写这句代码的时候就已经对它做了一个架构上的规划和设计,这种形式能帮助我们在编译阶段阻止一些错误。
比如输入下面这段代码:
fn main() { let a: u8 = 323232; println!("{a}"); }
编译器就会报错,指出u8类型装不下这么大的一个数字。
error: literal out of range for `u8`
--> src/main.rs:5:17
|
5 | let a: u8 = 323232;
| ^^^^^^
|
= note: the literal `323232` does not fit into the type `u8` whose range is `0..=255`
看到这个错误,你是不是感觉Rust特别贴心。同样的代码,你可以放在其他语言中实现,做一下对比。
所有的变量都应该具有明确的类型是Rust程序的基本设计。 当然其他语言中也有类型,不同语言对类型重视的程度不一样,这取决于语言自身的设计定位。
好了,变量的概念我们先解析到这里,下面我们来看一个Rust中的“奇怪”行为。
Rust中“奇怪”的行为
我们先来看一个例子。
fn main() { let a = 10u32; let b = a; println!("{a}"); println!("{b}"); }
很简单,它打印出:
10
10
然后我们再来看字符串的行为,你猜一下程序会输出什么。
fn main() { let s1 = String::from("I am a superman."); let s2 = s1; println!("{s1}"); println!("{s2}"); }
是两行“I am a superman”吗?反正在其他语言中是这样的。
结果在Rust中不是,编译器给出了出错信息,我们来看看。
Compiling playground v0.0.1 (/playground)
error[E0382]: borrow of moved value: `s1`
// 借用了移动后的值 `s1`
--> src/main.rs:4:15
|
2 | let s1 = String::from("I am a superman.");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
// 移动发生了,因为 `s1` 的类型是 `String`,而这种类型并没有实现 `Copy` trait."。
3 | let s2 = s1;
| -- value moved here
// 在这里值移动了。
4 | println!("{s1}");
| ^^^^ value borrowed here after move
// 值在被移动后在这里被借用
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
// 如果性能成本可以接受的话,考虑克隆这个值
|
3 | let s2 = s1.clone();
| ++++++++
既然给出了修改建议,那我们直接照着代码建议改一下试试。
fn main() { let s1 = String::from("I am a superman."); let s2 = s1.clone(); println!("{s1}"); println!("{s2}"); }
好了,这下输出我们预期的结果了。
I am a superman.
I am a superman.
Rust中的字符串为何有如此奇怪的行为呢?
所有权
首先,我们看到在Rust中,字符串的行为好像与u32这种数字类型不一样。前面我们说过,u32这种类型是固定尺寸类型,而String是非固定尺寸类型。一般来说,对于固定尺寸类型,会默认放在栈上;而非固定尺寸类型,会默认创建在堆上,成为堆上的一个资源,然后在栈上用一个局部变量来指向它,如代码中的s1。
在将一个变量赋值给另一个变量的时候,不同语言对底层细节的处理不一样。这里我们拿Java举例。前面我们说过,局部变量都是定义在栈帧中的,Java也是一样。Java语言对于int这类固定尺寸类型,在复制给另一个变量的时候,会直接复制它的值。在面对Object这种复杂对象的时候,默认只会复制这个Object的引用给另一个变量。这个引用的值(内存地址)就存在栈上的局部变量里面。
为什么会这样设计呢?因为如果那个Object占用的内存很大,每一次重新赋值,就把那个对象重新拷贝一次,也就是完全克隆,是非常低效的,凡是脑筋正常的语言都不会那样干。所以在用Java编程时,它实际上是隐藏了对象 引用的复制 这个细节。
回到Rust,我们看到对于u32这种固定尺寸类型来说,Rust与Java也是同样的处理,直接在栈上进行内容的拷贝。而对于字符串这种动态长度的类型来说,在变量的再赋值上,Rust除了拷贝字符串的引用外,实际还做了更多事情。具体是什么事情呢?我们先来看一下修改后的例子。
fn main() { let s1 = String::from("I am a superman."); let s2 = s1; //println!("{s1}"); println!("{s2}"); }
这个例子,就能正常打印。
I am a superman.
对比之后,我们发现 let s2 = s1; 语句执行后,s2可以使用,而s1不能再使用了。也就是说,在Rust里面,s1把内容“复制”给s2后,s2可用,s1不能用了!
从代码层面我们也可以说,s1把值(资源)“移动”给了s2。既然是移动了,那原来的变量就没有那个值了。请仔细体会这里与Java的不同之处。Java默认做了引用的拷贝,并且新旧两个变量同时指向原来那个对象。而Rust不一样, Rust虽然也是把字符串的引用由s1拷贝到了s2,但是只保留了最新的s2到字符串的指向,同时却把s1到字符串的指向给“抹去”了。 s1之后都处于一种“不可用”的状态,直到函数结束。这就是Rust编译器做的那个“更多”的部分。
下面的图示展示了这两种行为上的差异。
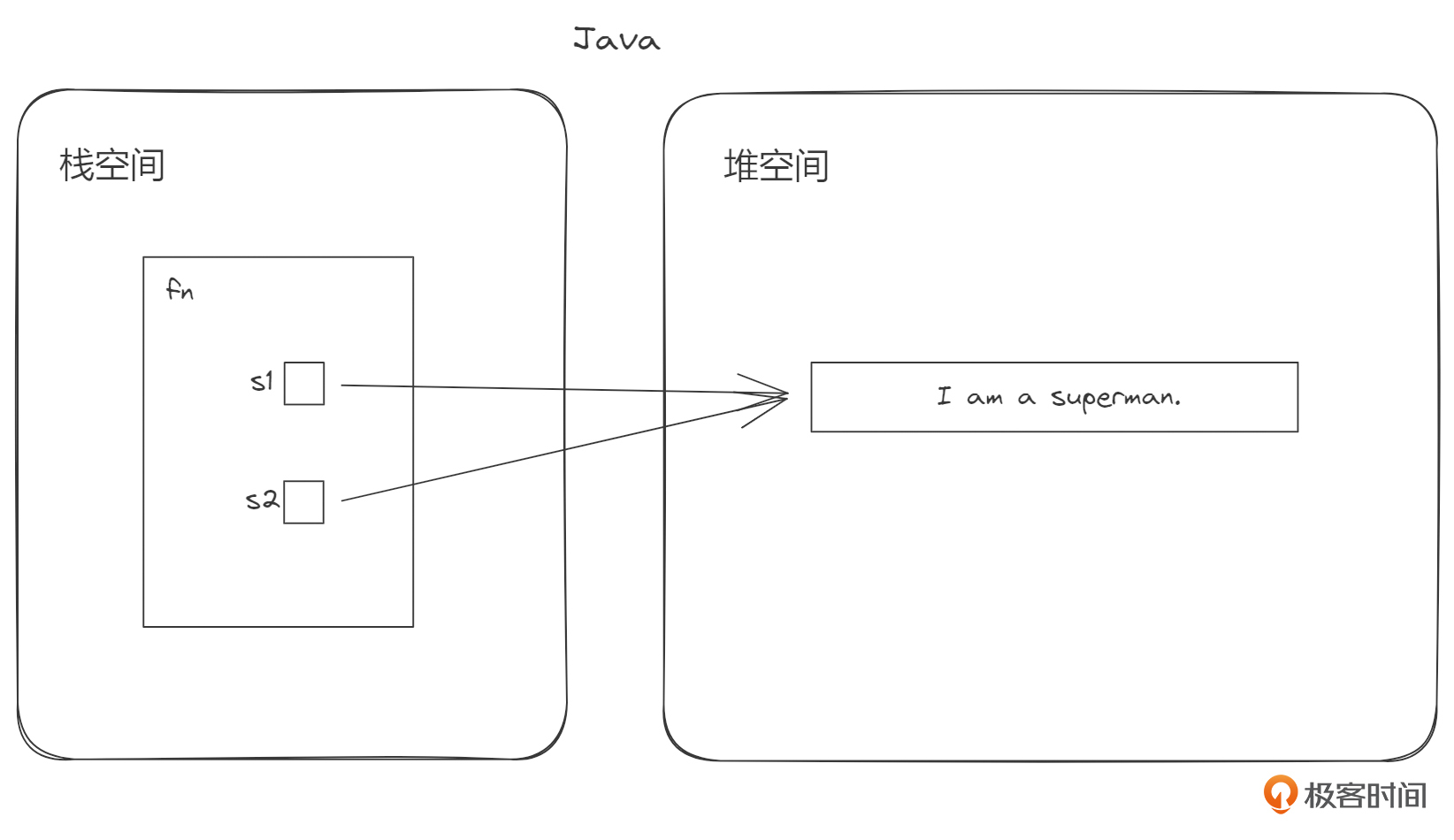
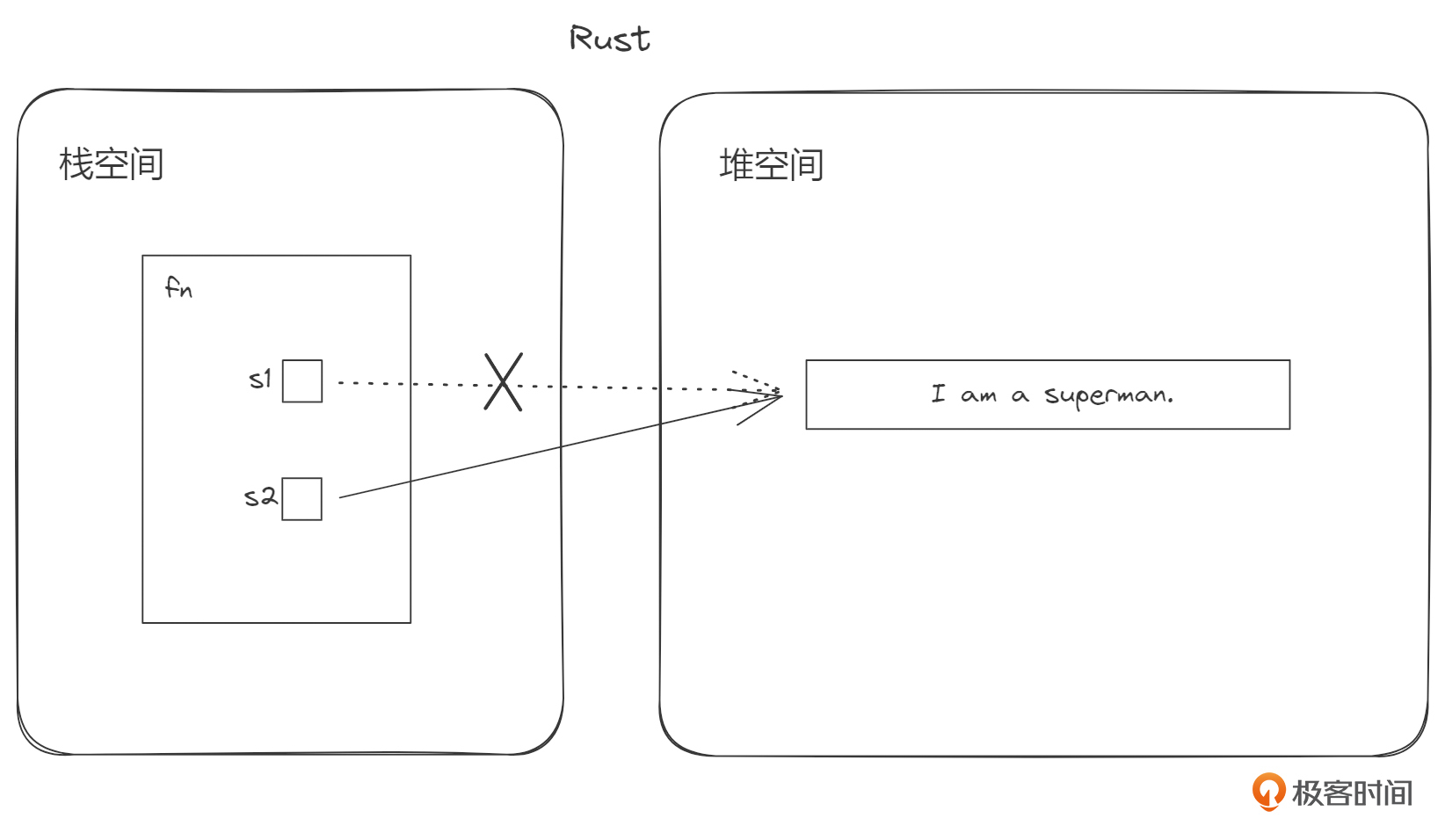
好奇怪呀!Rust怎么会这样设计呢?
其实这正是Rust从头开始梳理整个软件体系的地方,剑指一个目标: 内存安全。
所有权
长久以来,计算机领域最聪明的大脑都在探索如何写出更安全的程序,为此建立了各种理论、模式、模型。而Rust不走寻常路,它采用了一种全新的思路,利用所有权来管理内存资源,保证内存安全。接下来我们就一起来好好品鉴一下这个独特的思路。此刻 ,请你先卸下之前固有的思维,将脑袋放空一下。
Rust明确了所有权的概念,值也可以叫资源,所有权就是拥有资源的权利。一个变量拥有一个资源的所有权,那它就要负责那个资源的回收、释放。 Rust基于所有权定义出发,推导出了整个世界。
所有权的基础是三条定义。
- Rust中,每一个值都有一个所有者。
- 任何一个时刻,一个值只有一个所有者。
- 当所有者所在作用域(scope)结束的时候,其管理的值会被一起释放掉。
这三条规则涉及两个概念: 所有者和作用域。
所谓所有者,在代码里就用变量表示。而变量的作用域,就是变量有效(valid)的那个代码区间。在Rust中,一个所有权型变量的作用域,简单来说就是它定义时所在的那个最里层的花括号括起的部分,从变量创建时开始,到花括号结束的地方。
比如:
fn main() { let s = String::from("hello"); // do stuff with s } // 变量s的作用域到这里结束 fn main() { let a = 1u32; { let s = String::from("hello"); } // 变量s的作用域到这里结束 // xxxx } // 变量a的作用域到这里结束
变量在其作用域内是有效的,离开作用域就无效了。
好,理解了这一点,我们现在尝试用所有权规则去翻新一下对前面例子的理解。
fn main() { let a = 10u32; let b = a; println!("{a}"); println!("{b}"); }
在这个例子中,a具有对值 10u32的所有权。执行 let b = a 的时候,把值 10u32 复制了一份,b具有对这个新的10u32值的所有权。当main函数结束的时候,a、b两个变量就离开了作用域,其对应的两个10u32,就都被回收了。这里是栈帧结束,栈帧内存被回收,局部变量位于栈帧中,所以它们所占用的内存就被回收了。
再来看一个字符串的例子。
fn main() { let s1 = String::from("I am a superman."); println!("{s1}"); }
局部变量s1拥有这个字符串的所有权。s1的作用域从定义到开始,直到花括号结束。s1(栈帧上的局部变量)离开作用域时,变量s1上绑定的内存资源(字符串)就被回收掉了。注意,这里发生的事情是,栈帧中的局部变量离开作用域了,顺带要求堆内存中的字符串资源被回收。之所以能够做到这一点,是因为这个堆中的字符串资源被栈帧中的局部变量所指向了的。
而从Rust的语法层面看起来,就是变量s1对那个字符串拥有所有权。所以s1离开作用域的时候,那个资源就一起被回收了。这看起来好像是一个自动的过程,我们并没有像C语言中那样,需要手动调用free()函数去释放堆中的字符串资源。
这种 堆内存资源随着关联的栈上局部变量一起被回收 的内存管理特性,叫作 RAII(Resource Acquisition Is Initialization)。它实际不是Rust的原创,而是C++创造的。如果你学过C的话,可以对比一下C中的malloc()分配堆内存的方式,在分配堆内存后,C语言里面必须由程序员手动在后续的代码中使用free()来释放堆内存中的资源。而有了RAII特性后,我们不需要手动写free(),因此可以认为RAII内存管理方式是一个相当大的进步。
有了所有权的知识后,我们再回过头来分析上面那个例子。
fn main() { let s1 = String::from("I am a superman."); let s2 = s1; //println!("{s1}"); println!("{s2}"); }
变量s1持有这个字符串的所有权。s1对字符串的所有权从第2行定义时开始,到 let s2 = s1 执行后结束。这一行执行后,s2持有那个字符串的所有权。而此时s1处于什么状态呢?处于一种不可用的状态,或者叫无效状态(invalid),这个状态是由Rust编译器在编译阶段帮我们管理的,我们只需要从所有权模型去理解它,而不需要操心细节。Rustc小助手把这些事情给我们打理得明明白白的。
然后直到花括号结束,s2及s2所拥有的字符串内存,就被回收掉了,s1所对应的那个局部变量的内存空间也一并被回收了。
所有权是Rust语言的出发点,我们写的任何Rust程序,都必须遵循这套规则。
需要注意的一点是,所有权其实是内存结构之上的更上层概念,并不是说只有在堆中分配的资源才有所有权。实际上,栈上的资源也是有所有权的。所有权这个概念实际上屏蔽了底层内存结构的细节,让我们可以站在一个新的层次上更有效地对问题进行建模。
这个思维一定要注意,Rust语言中并不是所有的分析都需要归结到内存结构上去才能搞清楚,思维一直停留在内存结构上,有时会妨碍你的抽象建模能力,就像你精通量子力学不一定能当一个好的建筑师,所以这一点尤其要注意。
使用所有权书写函数
下面我们来看一下,基于所有权规则,函数的写法会变成什么样。
fn foo(s: String) { println!("{s}"); } fn main() { let s1 = String::from("I am a superman."); foo(s1); }
输出:
I am a superman.
没问题。
稍微改动一下例子,我们想在函数调用结束后,在外面再打印一下s1的值。
fn foo(s: String) { println!("{s}"); } fn main() { let s1 = String::from("I am a superman."); foo(s1); println!("{s1}"); // 这里加了一行 }
咦,编译出错了。提示:
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:8:16
|
6 | let s1 = String::from("I am a superman.");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
7 | foo(s1);
| -- value moved here
8 | println!("{s1}");
| ^^ value borrowed here after move
|
note: consider changing this parameter type in function `foo` to borrow instead if owning the value isn't necessary
--> src/main.rs:1:11
|
1 | fn foo(s: String) {
| --- ^^^^^^ this parameter takes ownership of the value
| |
| in this function
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
7 | foo(s1.clone());
| ++++++++
这个例子在其他语言中,一般是不会有问题的。foo函数也许会修改字符串的值,在外面重新打印的时候,会打印出新的值。但是,这其实是一种相当隐晦的设计模式,可能会造成一些错误(在下一讲我们会讲到),而Rust阻止了这种模式。
这个例子代码的提示与前面差不多,就是说s1所有权已经被移动进函数里面了,不能在移动后再使用了。
注意提示中的这一行:
1 | fn foo(s: String) {
| --- ^^^^^^ this parameter takes ownership of the value
函数的参数s获取了这个值的所有权。函数参数是这个函数的一个局部变量,它在这个函数栈帧结束的时候会被回收,因此这个字符串在这个函数调用结束后,就已经被回收了,这就是我们无法再打印这个字符串的原因。
同样我们再看一个上面例子的变形。
fn foo(s: String) { println!("{s}"); } fn main() { let s1 = String::from("I am a superman."); foo(s1); foo(s1); }
我们简单地想调用两次 foo() 函数都做不到,原因跟前面是一样的。这就是Rust有点反直觉的地方,也是令很多初学者崩溃的地方。原因我们再重复一下,一个苹果,你给了别人,那你就没有了。一个知识,我教给了你,我们都会得到。Rust的编程模型默认选择了前者,而以往的主流编程语言默认选择了后者。
回到前面例子,那我们后面的代码还想用s1,该怎么办?
可以这样,既然能把所有权移动到函数里面,也当然能把所有权转移出来。
fn foo(s: String) -> String { println!("{s}"); s } fn main() { let s1 = String::from("I am a superman."); let s1 = foo(s1); println!("{s1}"); }
这样就输出了结果:
I am a superman.
I am a superman.
我们适配了Rust的所有权规则,实现了我们期望的函数调用效果。
移动还是复制
前面讲到,u32这种类型在做变量的再赋值的时候,是做了复制所有权的操作。而String这种类型在做变量再赋值的时候,是做了移动所有权的操作。那么,在Rust中哪些类型默认是做移动所有权操作,哪些类型默认是做复制所有权操作呢?
默认做复制所有权的操作的有7种。
- 所有的整数类型,比如u32;
- 布尔类型bool;
- 浮点数类型,比如f32、f64;
- 字符类型char;
- 由以上类型组成的元组类型 tuple,如(i32, i32, char);
- 由以上类型组成的数组类型 array,如 [9; 100];
- 不可变引用类型&。
其他类型默认都是做移动所有权的操作。
小结
所有权是Rust语言中非常重要的一个概念,用于 管理程序中使用的资源。这些资源可以是堆上的动态分配的内存资源,也可以是栈上的内存资源,或者是其他的系统资源,比如IO资源。所有权通过把语句绑定在变量上,封装了栈和堆的实现细节。对于固定尺寸基础类型(小尺寸类型),它们的值默认是可复制的,这主要是为了编程方便。对于非固定尺寸类型或大尺寸类型的变量再赋值时,默认使用移动操作。除非显式地clone,否则它只保持一份所有权。
所有权可以被转移,一旦所有权被转移,原来持有该资源的变量就失效了。变量的作用域是在最近的花括号位置内。
思考题
最后我来考一考你。
- 下面的示例将输出什么?
fn main() { let s = "I am a superman.".to_string(); for i in 1..10 { let tmp_s = s; println!("s is {}", tmp_s); } }
- 一个由固定尺寸类型组成的结构体变量,如下面示例中的Point类型,在赋值给另一个变量时,采用的是移动方式还是复制方式?
struct Point {
x: i64,
y: i64,
z: i64
}
欢迎你把你思考后的答案分享到评论区,和我一起讨论,也欢迎你把这节课分享给需要的朋友,邀他一起学习,我们下节课再见!